 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeLost in OCR Translation? Vision-Based Approaches to Robust Document Retrieval
May 08, 2025Retrieval-Augmented Generation (RAG) has become a popular technique for enhancing the reliability and utility of Large Language Models (LLMs) by grounding responses in external documents. Traditional RAG systems rely on Optical Character Recognition (OCR) to first process scanned documents into text. However, even state-of-the-art OCRs can introduce errors, especially in degraded or complex documents. Recent vision-language approaches, such as ColPali, propose direct visual embedding of documents, eliminating the need for OCR. This study presents a systematic comparison between a vision-based RAG system (ColPali) and more traditional OCR-based pipelines utilizing Llama 3.2 (90B) and Nougat OCR across varying document qualities. Beyond conventional retrieval accuracy metrics, we introduce a semantic answer evaluation benchmark to assess end-to-end question-answering performance. Our findings indicate that while vision-based RAG performs well on documents it has been fine-tuned on, OCR-based RAG is better able to generalize to unseen documents of varying quality. We highlight the key trade-offs between computational efficiency and semantic accuracy, offering practical guidance for RAG practitioners in selecting between OCR-dependent and vision-based document retrieval systems in production environments.
LLM-Assisted Translation of Legacy FORTRAN Codes to C++: A Cross-Platform Study
Apr 21, 2025Large Language Models (LLMs) are increasingly being leveraged for generating and translating scientific computer codes by both domain-experts and non-domain experts. Fortran has served as one of the go to programming languages in legacy high-performance computing (HPC) for scientific discoveries. Despite growing adoption, LLM-based code translation of legacy code-bases has not been thoroughly assessed or quantified for its usability. Here, we studied the applicability of LLM-based translation of Fortran to C++ as a step towards building an agentic-workflow using open-weight LLMs on two different computational platforms. We statistically quantified the compilation accuracy of the translated C++ codes, measured the similarity of the LLM translated code to the human translated C++ code, and statistically quantified the output similarity of the Fortran to C++ translation.
Effects of the Nonlinearity in Activation Functions on the Performance of Deep Learning Models
Oct 14, 2020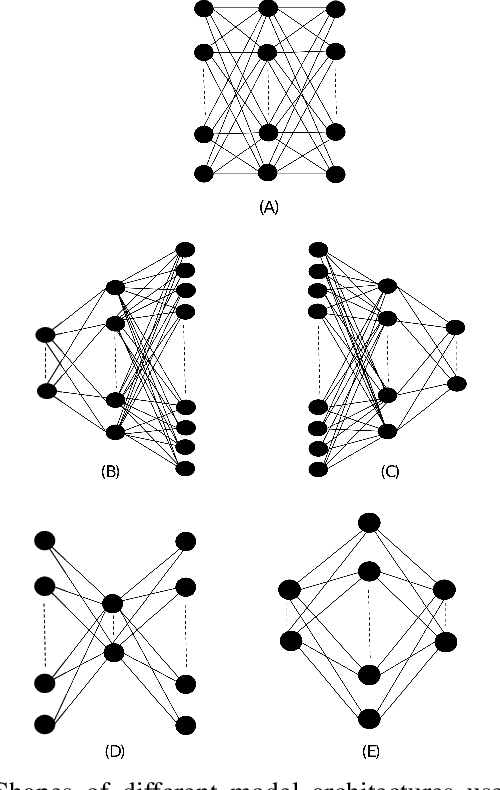
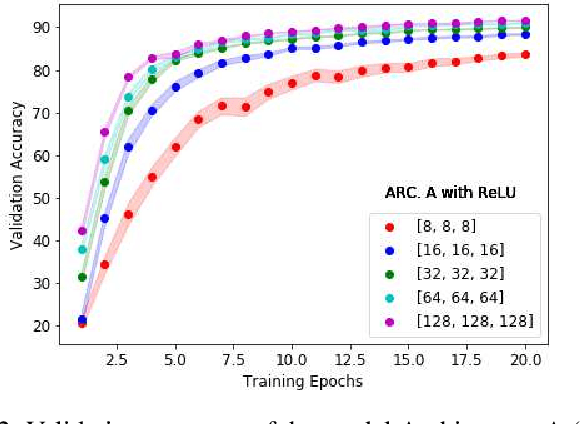
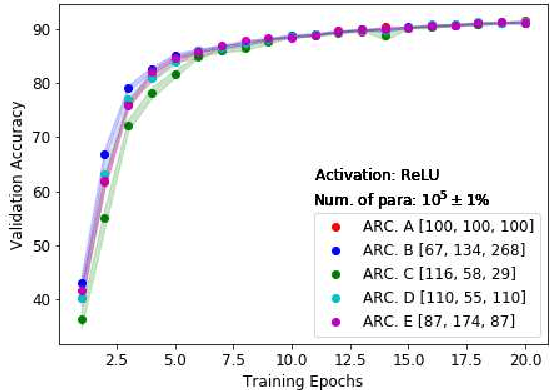
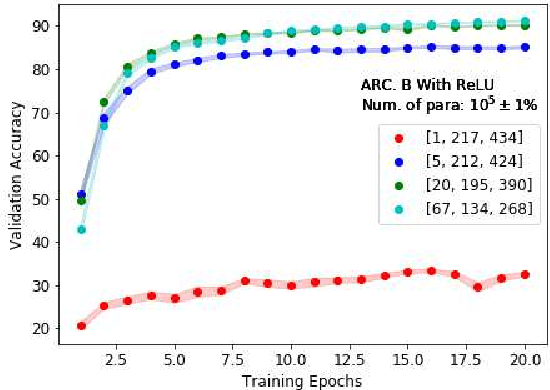
The nonlinearity of activation functions used in deep learning models are crucial for the success of predictive models. There are several commonly used simple nonlinear functions, including Rectified Linear Unit (ReLU) and Leaky-ReLU (L-ReLU). In practice, these functions remarkably enhance the model accuracy. However, there is limited insight into the functionality of these nonlinear activation functions in terms of why certain models perform better than others. Here, we investigate the model performance when using ReLU or L-ReLU as activation functions in different model architectures and data domains. Interestingly, we found that the application of L-ReLU is mostly effective when the number of trainable parameters in a model is relatively small. Furthermore, we found that the image classification models seem to perform well with L-ReLU in fully connected layers, especially when pre-trained models such as the VGG-16 are used for the transfer learning.