 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeGneissWeb: Preparing High Quality Data for LLMs at Scale
Feb 19, 2025



Data quantity and quality play a vital role in determining the performance of Large Language Models (LLMs). High-quality data, in particular, can significantly boost the LLM's ability to generalize on a wide range of downstream tasks. Large pre-training datasets for leading LLMs remain inaccessible to the public, whereas many open datasets are small in size (less than 5 trillion tokens), limiting their suitability for training large models. In this paper, we introduce GneissWeb, a large dataset yielding around 10 trillion tokens that caters to the data quality and quantity requirements of training LLMs. Our GneissWeb recipe that produced the dataset consists of sharded exact sub-string deduplication and a judiciously constructed ensemble of quality filters. GneissWeb achieves a favorable trade-off between data quality and quantity, producing models that outperform models trained on state-of-the-art open large datasets (5+ trillion tokens). We show that models trained using GneissWeb dataset outperform those trained on FineWeb-V1.1.0 by 2.73 percentage points in terms of average score computed on a set of 11 commonly used benchmarks (both zero-shot and few-shot) for pre-training dataset evaluation. When the evaluation set is extended to 20 benchmarks (both zero-shot and few-shot), models trained using GneissWeb still achieve a 1.75 percentage points advantage over those trained on FineWeb-V1.1.0.
Data-Prep-Kit: getting your data ready for LLM application development
Sep 26, 2024



Data preparation is the first and a very important step towards any Large Language Model (LLM) development. This paper introduces an easy-to-use, extensible, and scale-flexible open-source data preparation toolkit called Data Prep Kit (DPK). DPK is architected and designed to enable users to scale their data preparation to their needs. With DPK they can prepare data on a local machine or effortlessly scale to run on a cluster with thousands of CPU Cores. DPK comes with a highly scalable, yet extensible set of modules that transform natural language and code data. If the user needs additional transforms, they can be easily developed using extensive DPK support for transform creation. These modules can be used independently or pipelined to perform a series of operations. In this paper, we describe DPK architecture and show its performance from a small scale to a very large number of CPUs. The modules from DPK have been used for the preparation of Granite Models [1] [2]. We believe DPK is a valuable contribution to the AI community to easily prepare data to enhance the performance of their LLM models or to fine-tune models with Retrieval-Augmented Generation (RAG).
Scaling Granite Code Models to 128K Context
Jul 18, 2024This paper introduces long-context Granite code models that support effective context windows of up to 128K tokens. Our solution for scaling context length of Granite 3B/8B code models from 2K/4K to 128K consists of a light-weight continual pretraining by gradually increasing its RoPE base frequency with repository-level file packing and length-upsampled long-context data. Additionally, we also release instruction-tuned models with long-context support which are derived by further finetuning the long context base models on a mix of permissively licensed short and long-context instruction-response pairs. While comparing to the original short-context Granite code models, our long-context models achieve significant improvements on long-context tasks without any noticeable performance degradation on regular code completion benchmarks (e.g., HumanEval). We release all our long-context Granite code models under an Apache 2.0 license for both research and commercial use.
Granite Code Models: A Family of Open Foundation Models for Code Intelligence
May 07, 2024



Large Language Models (LLMs) trained on code are revolutionizing the software development process. Increasingly, code LLMs are being integrated into software development environments to improve the productivity of human programmers, and LLM-based agents are beginning to show promise for handling complex tasks autonomously. Realizing the full potential of code LLMs requires a wide range of capabilities, including code generation, fixing bugs, explaining and documenting code, maintaining repositories, and more. In this work, we introduce the Granite series of decoder-only code models for code generative tasks, trained with code written in 116 programming languages. The Granite Code models family consists of models ranging in size from 3 to 34 billion parameters, suitable for applications ranging from complex application modernization tasks to on-device memory-constrained use cases. Evaluation on a comprehensive set of tasks demonstrates that Granite Code models consistently reaches state-of-the-art performance among available open-source code LLMs. The Granite Code model family was optimized for enterprise software development workflows and performs well across a range of coding tasks (e.g. code generation, fixing and explanation), making it a versatile all around code model. We release all our Granite Code models under an Apache 2.0 license for both research and commercial use.
Towards API Testing Across Cloud and Edge
Sep 06, 2021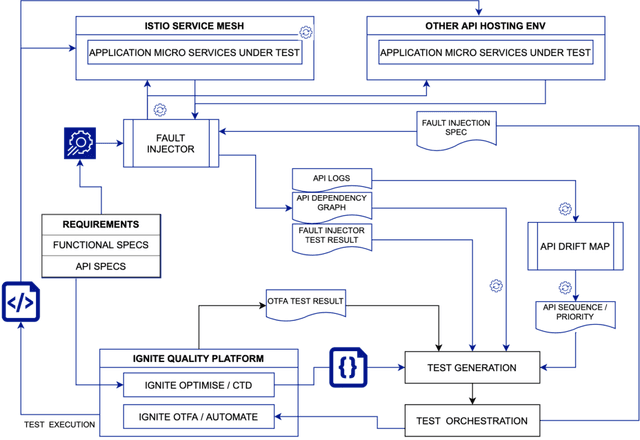
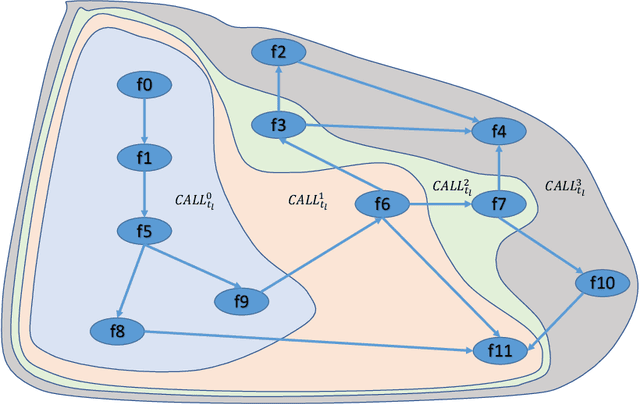
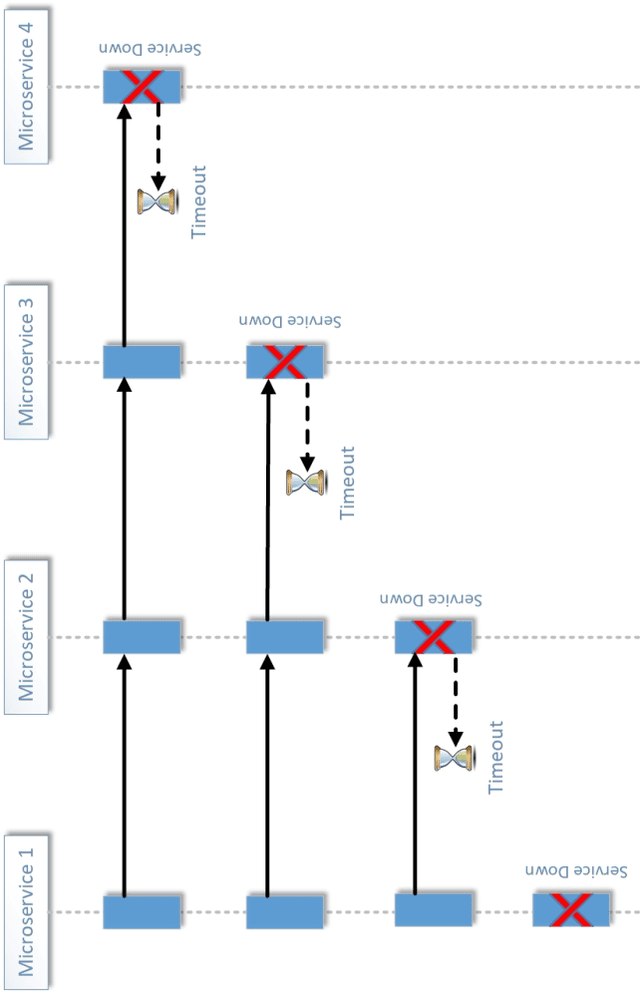
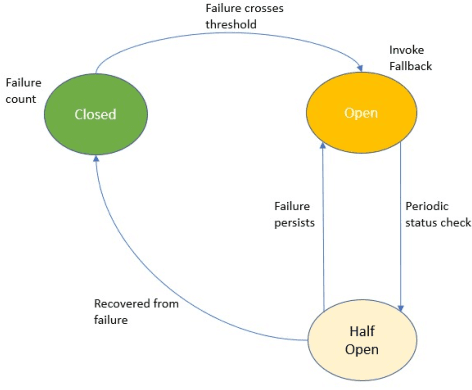
API economy is driving the digital transformation of business applications across the hybrid Cloud and edge environments. For such transformations to succeed, end-to-end testing of the application API composition is required. Testing of API compositions, even in centralized Cloud environments, is challenging as it requires coverage of functional as well as reliability requirements. The combinatorial space of scenarios is huge, e.g., API input parameters, order of API execution, and network faults. Hybrid Cloud and edge environments exacerbate the challenge of API testing due to the need to coordinate test execution across dynamic wide-area networks, possibly across network boundaries. To handle this challenge, we envision a test framework named Distributed Software Test Kit (DSTK). The DSTK leverages Combinatorial Test Design (CTD) to cover the functional requirements and then automatically covers the reliability requirements via under-the-hood closed loop between test execution feedback and AI based search algorithms. In each iteration of the closed loop, the search algorithms generate more reliability test scenarios to be executed next. Specifically, five kinds of reliability tests are envisioned: out-of-order execution of APIs, network delays and faults, API performance and throughput, changes in API call graph patterns, and changes in application topology.
Environment Transfer for Distributed Systems
Jan 06, 2021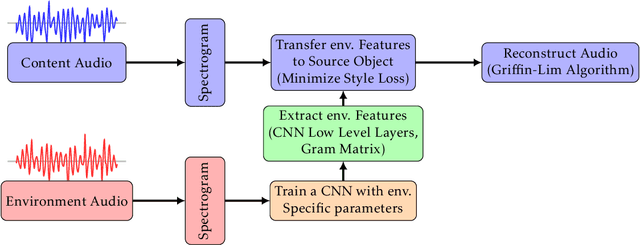

Collecting sufficient amount of data that can represent various acoustic environmental attributes is a critical problem for distributed acoustic machine learning. Several audio data augmentation techniques have been introduced to address this problem but they tend to remain in simple manipulation of existing data and are insufficient to cover the variability of the environments. We propose a method to extend a technique that has been used for transferring acoustic style textures between audio data. The method transfers audio signatures between environments for distributed acoustic data augmentation. This paper devises metrics to evaluate the generated acoustic data, based on classification accuracy and content preservation. A series of experiments were conducted using UrbanSound8K dataset and the results show that the proposed method generates better audio data with transferred environmental features while preserving content features.
SEEC: Semantic Vector Federation across Edge Computing Environments
Aug 30, 2020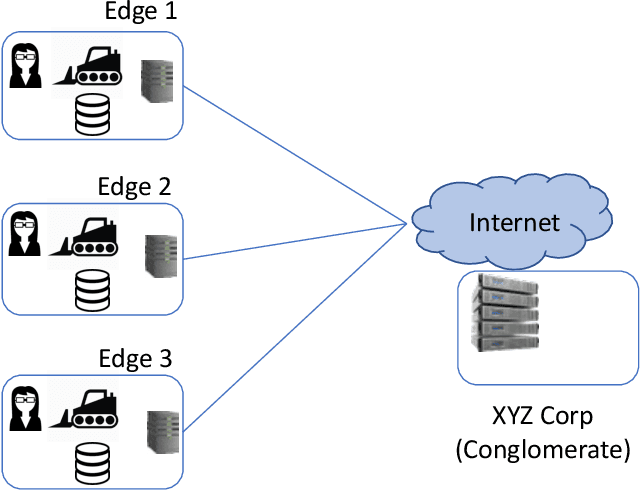
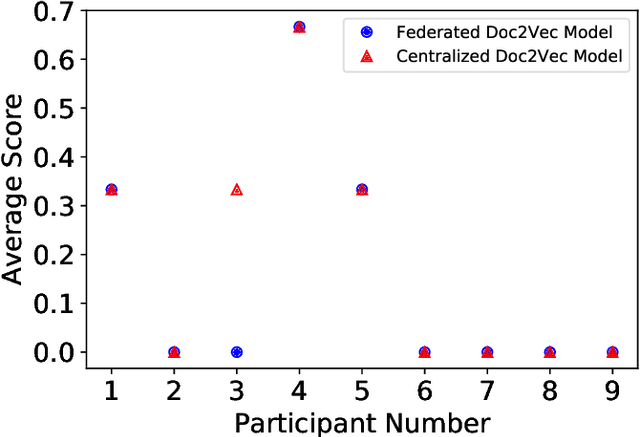
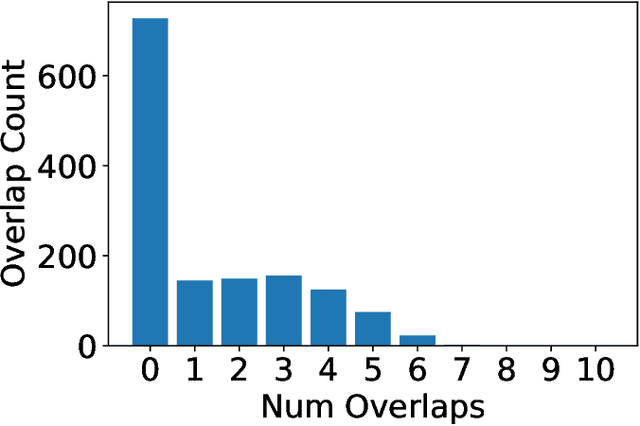
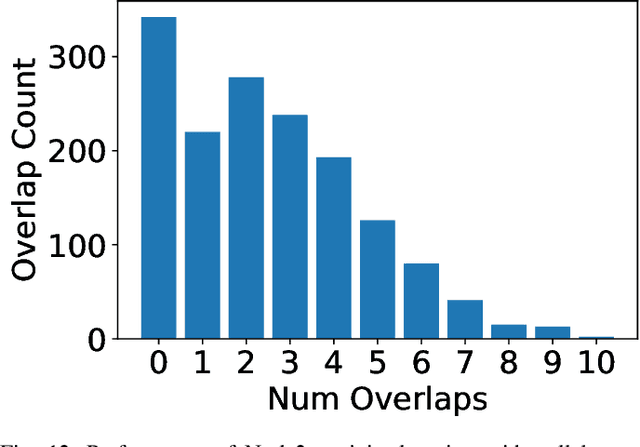
Semantic vector embedding techniques have proven useful in learning semantic representations of data across multiple domains. A key application enabled by such techniques is the ability to measure semantic similarity between given data samples and find data most similar to a given sample. State-of-the-art embedding approaches assume all data is available on a single site. However, in many business settings, data is distributed across multiple edge locations and cannot be aggregated due to a variety of constraints. Hence, the applicability of state-of-the-art embedding approaches is limited to freely shared datasets, leaving out applications with sensitive or mission-critical data. This paper addresses this gap by proposing novel unsupervised algorithms called \emph{SEEC} for learning and applying semantic vector embedding in a variety of distributed settings. Specifically, for scenarios where multiple edge locations can engage in joint learning, we adapt the recently proposed federated learning techniques for semantic vector embedding. Where joint learning is not possible, we propose novel semantic vector translation algorithms to enable semantic query across multiple edge locations, each with its own semantic vector-space. Experimental results on natural language as well as graph datasets show that this may be a promising new direction.
neuralRank: Searching and ranking ANN-based model repositories
Mar 02, 2019
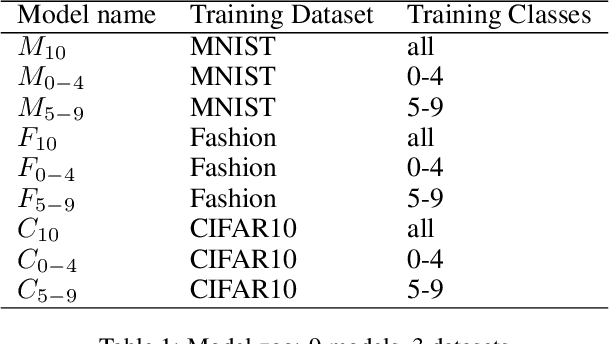
Widespread applications of deep learning have led to a plethora of pre-trained neural network models for common tasks. Such models are often adapted from other models via transfer learning. The models may have varying training sets, training algorithms, network architectures, and hyper-parameters. For a given application, what isthe most suitable model in a model repository? This is a critical question for practical deployments but it has not received much attention. This paper introduces the novel problem of searching and ranking models based on suitability relative to a target dataset and proposes a ranking algorithm called \textit{neuralRank}. The key idea behind this algorithm is to base model suitability on the discriminating power of a model, using a novel metric to measure it. With experimental results on the MNIST, Fashion, and CIFAR10 datasets, we demonstrate that (1) neuralRank is independent of the domain, the training set, or the network architecture and (2) that the models ranked highly by neuralRank ranking tend to have higher model accuracy in practice.