 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeThe STOIC2021 COVID-19 AI challenge: applying reusable training methodologies to private data
Jun 25, 2023Challenges drive the state-of-the-art of automated medical image analysis. The quantity of public training data that they provide can limit the performance of their solutions. Public access to the training methodology for these solutions remains absent. This study implements the Type Three (T3) challenge format, which allows for training solutions on private data and guarantees reusable training methodologies. With T3, challenge organizers train a codebase provided by the participants on sequestered training data. T3 was implemented in the STOIC2021 challenge, with the goal of predicting from a computed tomography (CT) scan whether subjects had a severe COVID-19 infection, defined as intubation or death within one month. STOIC2021 consisted of a Qualification phase, where participants developed challenge solutions using 2000 publicly available CT scans, and a Final phase, where participants submitted their training methodologies with which solutions were trained on CT scans of 9724 subjects. The organizers successfully trained six of the eight Final phase submissions. The submitted codebases for training and running inference were released publicly. The winning solution obtained an area under the receiver operating characteristic curve for discerning between severe and non-severe COVID-19 of 0.815. The Final phase solutions of all finalists improved upon their Qualification phase solutions.HSUXJM-TNZF9CHSUXJM-TNZF9C
Leaping Into Memories: Space-Time Deep Feature Synthesis
Mar 29, 2023



The success of deep learning models has led to their adaptation and adoption by prominent video understanding methods. The majority of these approaches encode features in a joint space-time modality for which the inner workings and learned representations are difficult to visually interpret. We propose LEArned Preconscious Synthesis (LEAPS), an architecture-agnostic method for synthesizing videos from the internal spatiotemporal representations of models. Using a stimulus video and a target class, we prime a fixed space-time model and iteratively optimize a video initialized with random noise. We incorporate additional regularizers to improve the feature diversity of the synthesized videos as well as the cross-frame temporal coherence of motions. We quantitatively and qualitatively evaluate the applicability of LEAPS by inverting a range of spatiotemporal convolutional and attention-based architectures trained on Kinetics-400, which to the best of our knowledge has not been previously accomplished.
Entropy-Based Feature Extraction For Real-Time Semantic Segmentation
Jul 07, 2022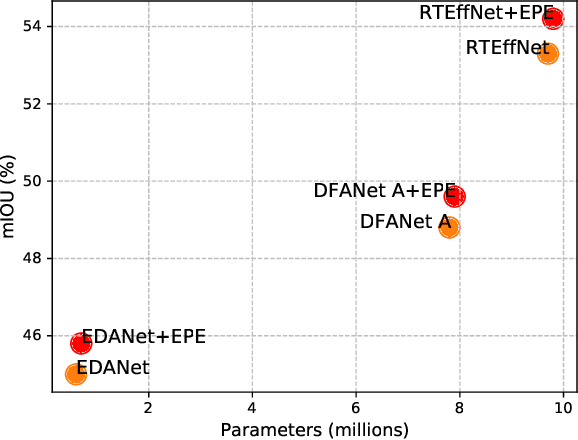
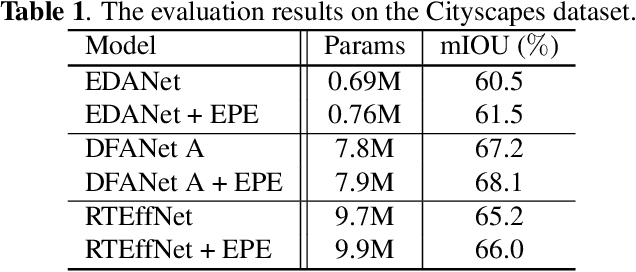
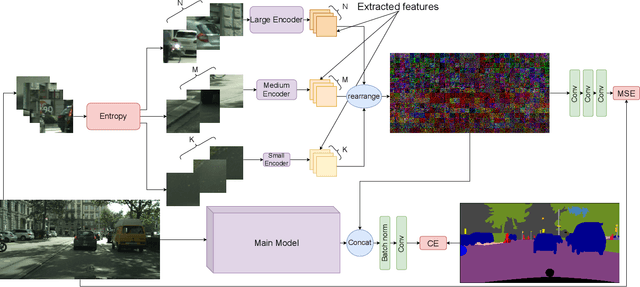

This paper introduces an efficient patch-based computational module, coined Entropy-based Patch Encoder (EPE) module, for resource-constrained semantic segmentation. The EPE module consists of three lightweight fully-convolutional encoders, each extracting features from image patches with a different amount of entropy. Patches with high entropy are being processed by the encoder with the largest number of parameters, patches with moderate entropy are processed by the encoder with a moderate number of parameters, and patches with low entropy are processed by the smallest encoder. The intuition behind the module is the following: as patches with high entropy contain more information, they need an encoder with more parameters, unlike low entropy patches, which can be processed using a small encoder. Consequently, processing part of the patches via the smaller encoder can significantly reduce the computational cost of the module. Experiments show that EPE can boost the performance of existing real-time semantic segmentation models with a slight increase in the computational cost. Specifically, EPE increases the mIOU performance of DFANet A by 0.9% with only 1.2% increase in the number of parameters and the mIOU performance of EDANet by 1% with 10% increase of the model parameters.
Representation Learning with Information Theory for COVID-19 Detection
Jul 04, 2022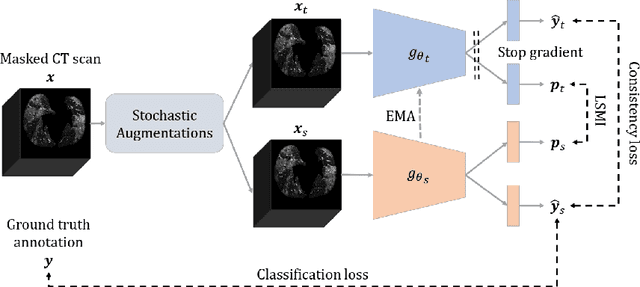
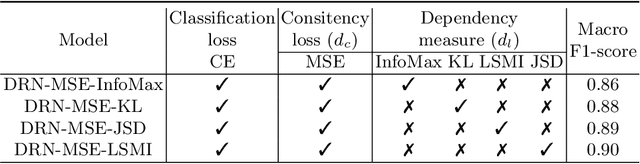
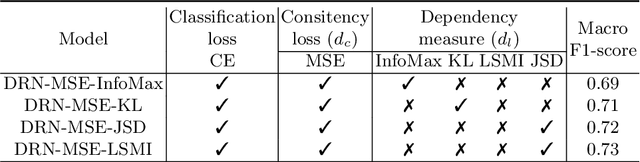
Successful data representation is a fundamental factor in machine learning based medical imaging analysis. Deep Learning (DL) has taken an essential role in robust representation learning. However, the inability of deep models to generalize to unseen data can quickly overfit intricate patterns. Thereby, we can conveniently implement strategies to aid deep models in discovering useful priors from data to learn their intrinsic properties. Our model, which we call a dual role network (DRN), uses a dependency maximization approach based on Least Squared Mutual Information (LSMI). The LSMI leverages dependency measures to ensure representation invariance and local smoothness. While prior works have used information theory measures like mutual information, known to be computationally expensive due to a density estimation step, our LSMI formulation alleviates the issues of intractable mutual information estimation and can be used to approximate it. Experiments on CT based COVID-19 Detection and COVID-19 Severity Detection benchmarks demonstrate the effectiveness of our method.
Visualizing and Understanding Self-Supervised Vision Learning
Jun 20, 2022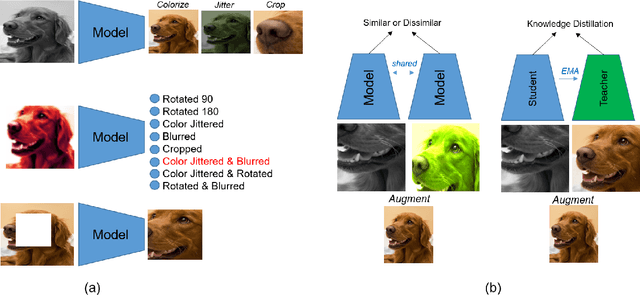
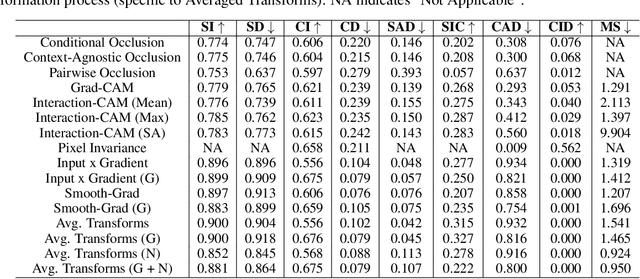
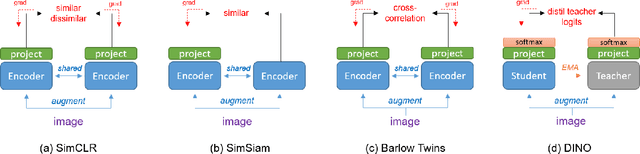
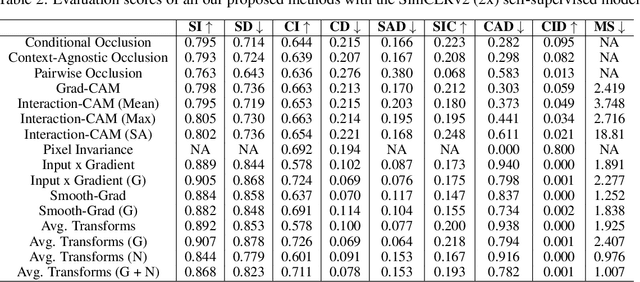
Self-Supervised vision learning has revolutionized deep learning, becoming the next big challenge in the domain and rapidly closing the gap with supervised methods on large computer vision benchmarks. With current models and training data exponentially growing, explaining and understanding these models becomes pivotal. We study the problem of explainable artificial intelligence in the domain of self-supervised learning for vision tasks, and present methods to understand networks trained with self-supervision and their inner workings. Given the huge diversity of self-supervised vision pretext tasks, we narrow our focus on understanding paradigms which learn from two views of the same image, and mainly aim to understand the pretext task. Our work focuses on explaining similarity learning, and is easily extendable to all other pretext tasks. We study two popular self-supervised vision models: SimCLR and Barlow Twins. We develop a total of six methods for visualizing and understanding these models: Perturbation-based methods (conditional occlusion, context-agnostic conditional occlusion and pairwise occlusion), Interaction-CAM, Feature Visualization, Model Difference Visualization, Averaged Transforms and Pixel Invaraince. Finally, we evaluate these explanations by translating well-known evaluation metrics tailored towards supervised image classification systems involving a single image, into the domain of self-supervised learning where two images are involved. Code is at: https://github.com/fawazsammani/xai-ssl
NLX-GPT: A Model for Natural Language Explanations in Vision and Vision-Language Tasks
Mar 09, 2022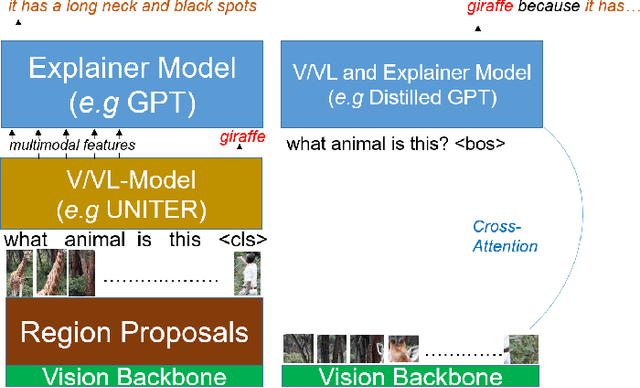


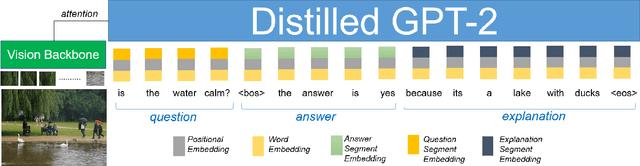
Natural language explanation (NLE) models aim at explaining the decision-making process of a black box system via generating natural language sentences which are human-friendly, high-level and fine-grained. Current NLE models explain the decision-making process of a vision or vision-language model (a.k.a., task model), e.g., a VQA model, via a language model (a.k.a., explanation model), e.g., GPT. Other than the additional memory resources and inference time required by the task model, the task and explanation models are completely independent, which disassociates the explanation from the reasoning process made to predict the answer. We introduce NLX-GPT, a general, compact and faithful language model that can simultaneously predict an answer and explain it. We first conduct pre-training on large scale data of image-caption pairs for general understanding of images, and then formulate the answer as a text prediction task along with the explanation. Without region proposals nor a task model, our resulting overall framework attains better evaluation scores, contains much less parameters and is 15$\times$ faster than the current SoA model. We then address the problem of evaluating the explanations which can be in many times generic, data-biased and can come in several forms. We therefore design 2 new evaluation measures: (1) explain-predict and (2) retrieval-based attack, a self-evaluation framework that requires no labels. Code is at: https://github.com/fawazsammani/nlxgpt.
Gradient Variance Loss for Structure-Enhanced Image Super-Resolution
Feb 02, 2022
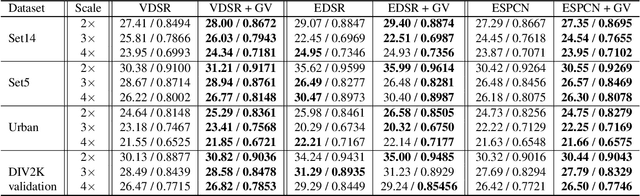
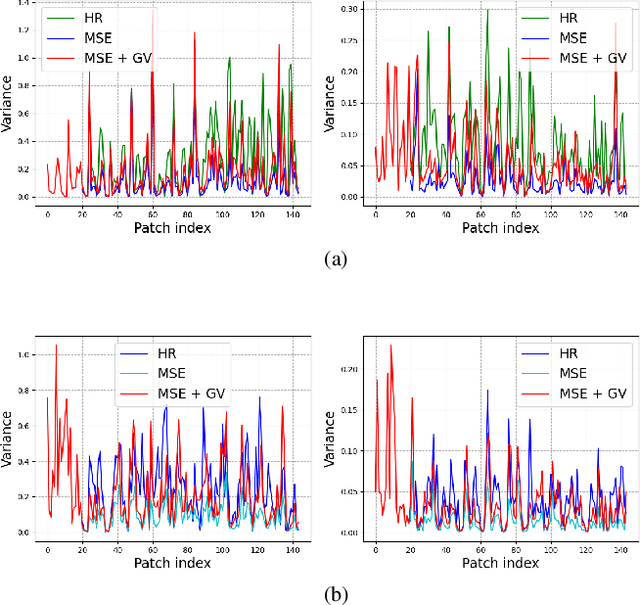
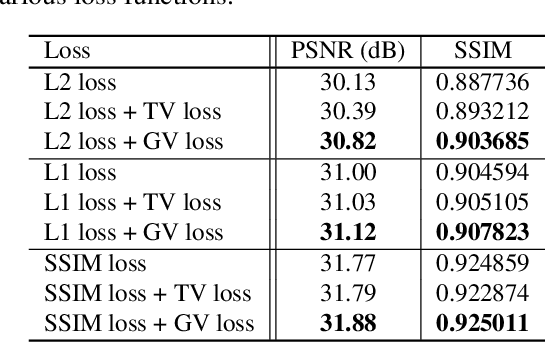
Recent success in the field of single image super-resolution (SISR) is achieved by optimizing deep convolutional neural networks (CNNs) in the image space with the L1 or L2 loss. However, when trained with these loss functions, models usually fail to recover sharp edges present in the high-resolution (HR) images for the reason that the model tends to give a statistical average of potential HR solutions. During our research, we observe that gradient maps of images generated by the models trained with the L1 or L2 loss have significantly lower variance than the gradient maps of the original high-resolution images. In this work, we propose to alleviate the above issue by introducing a structure-enhancing loss function, coined Gradient Variance (GV) loss, and generate textures with perceptual-pleasant details. Specifically, during the training of the model, we extract patches from the gradient maps of the target and generated output, calculate the variance of each patch and form variance maps for these two images. Further, we minimize the distance between the computed variance maps to enforce the model to produce high variance gradient maps that will lead to the generation of high-resolution images with sharper edges. Experimental results show that the GV loss can significantly improve both Structure Similarity (SSIM) and peak signal-to-noise ratio (PSNR) performance of existing image super-resolution (SR) deep learning models.
Traffic Event Detection as a Slot Filling Problem
Sep 13, 2021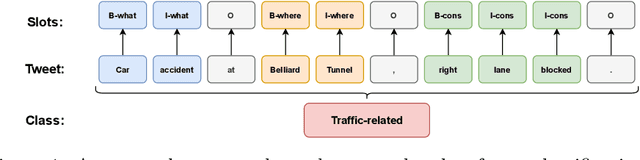
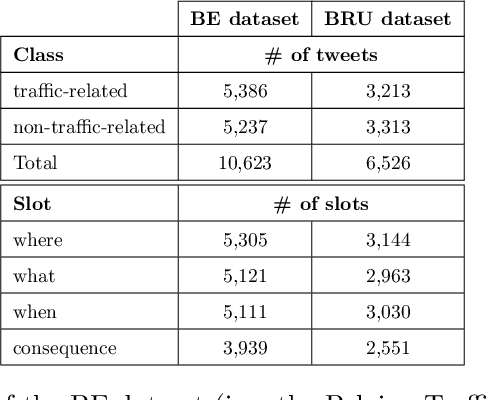
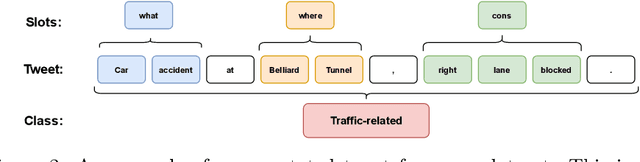
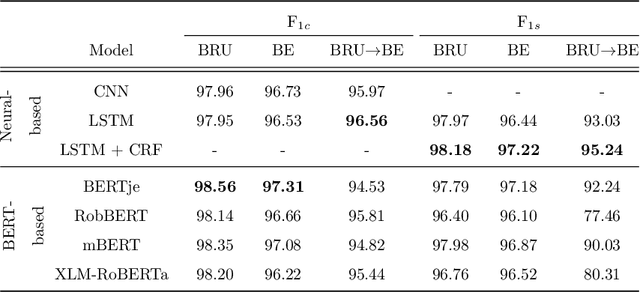
In this paper, we introduce the new problem of extracting fine-grained traffic information from Twitter streams by also making publicly available the two (constructed) traffic-related datasets from Belgium and the Brussels capital region. In particular, we experiment with several models to identify (i) whether a tweet is traffic-related or not, and (ii) in the case that the tweet is traffic-related to identify more fine-grained information regarding the event (e.g., the type of the event, where the event happened). To do so, we frame (i) the problem of identifying whether a tweet is a traffic-related event or not as a text classification subtask, and (ii) the problem of identifying more fine-grained traffic-related information as a slot filling subtask, where fine-grained information (e.g., where an event has happened) is represented as a slot/entity of a particular type. We propose the use of several methods that process the two subtasks either separately or in a joint setting, and we evaluate the effectiveness of the proposed methods for solving the traffic event detection problem. Experimental results indicate that the proposed architectures achieve high performance scores (i.e., more than 95% in terms of F$_{1}$ score) on the constructed datasets for both of the subtasks (i.e., text classification and slot filling) even in a transfer learning scenario. In addition, by incorporating tweet-level information in each of the tokens comprising the tweet (for the BERT-based model) can lead to a performance improvement for the joint setting.
Bias Loss for Mobile Neural Networks
Aug 10, 2021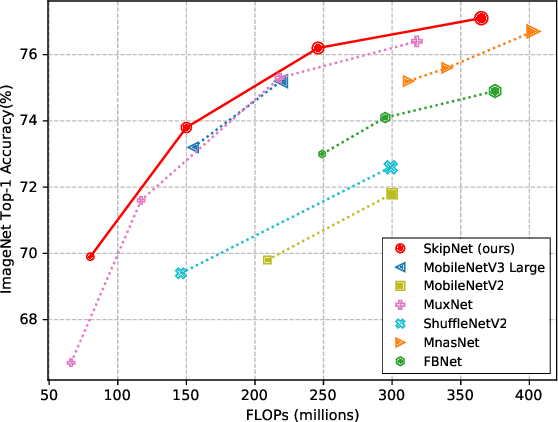
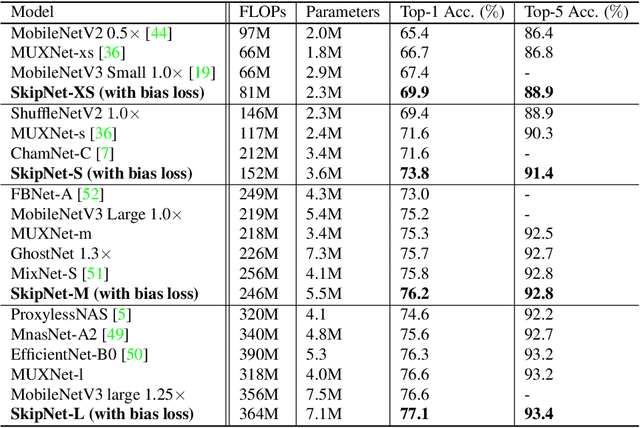
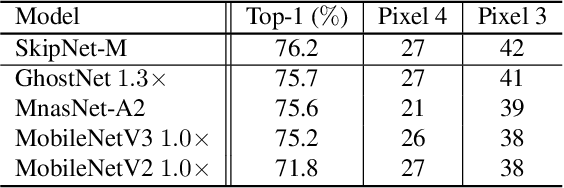
Compact convolutional neural networks (CNNs) have witnessed exceptional improvements in performance in recent years. However, they still fail to provide the same predictive power as CNNs with a large number of parameters. The diverse and even abundant features captured by the layers is an important characteristic of these successful CNNs. However, differences in this characteristic between large CNNs and their compact counterparts have rarely been investigated. In compact CNNs, due to the limited number of parameters, abundant features are unlikely to be obtained, and feature diversity becomes an essential characteristic. Diverse features present in the activation maps derived from a data point during model inference may indicate the presence of a set of unique descriptors necessary to distinguish between objects of different classes. In contrast, data points with low feature diversity may not provide a sufficient amount of unique descriptors to make a valid prediction; we refer to them as random predictions. Random predictions can negatively impact the optimization process and harm the final performance. This paper proposes addressing the problem raised by random predictions by reshaping the standard cross-entropy to make it biased toward data points with a limited number of unique descriptive features. Our novel Bias Loss focuses the training on a set of valuable data points and prevents the vast number of samples with poor learning features from misleading the optimization process. Furthermore, to show the importance of diversity, we present a family of SkipNet models whose architectures are brought to boost the number of unique descriptors in the last layers. Our Skipnet-M can achieve 1% higher classification accuracy than MobileNetV3 Large.
Learned Gradient Compression for Distributed Deep Learning
Mar 17, 2021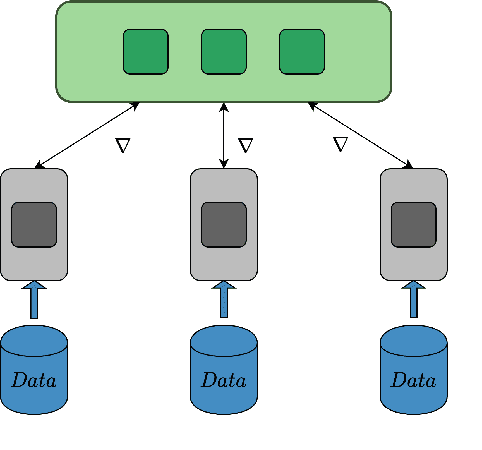
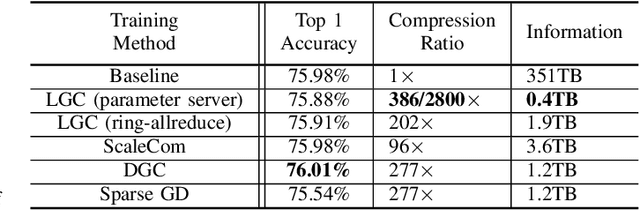
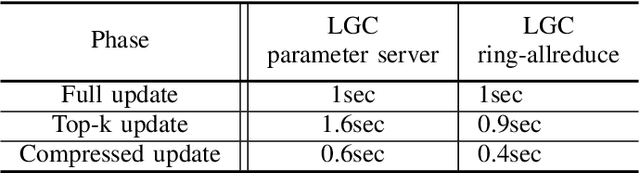
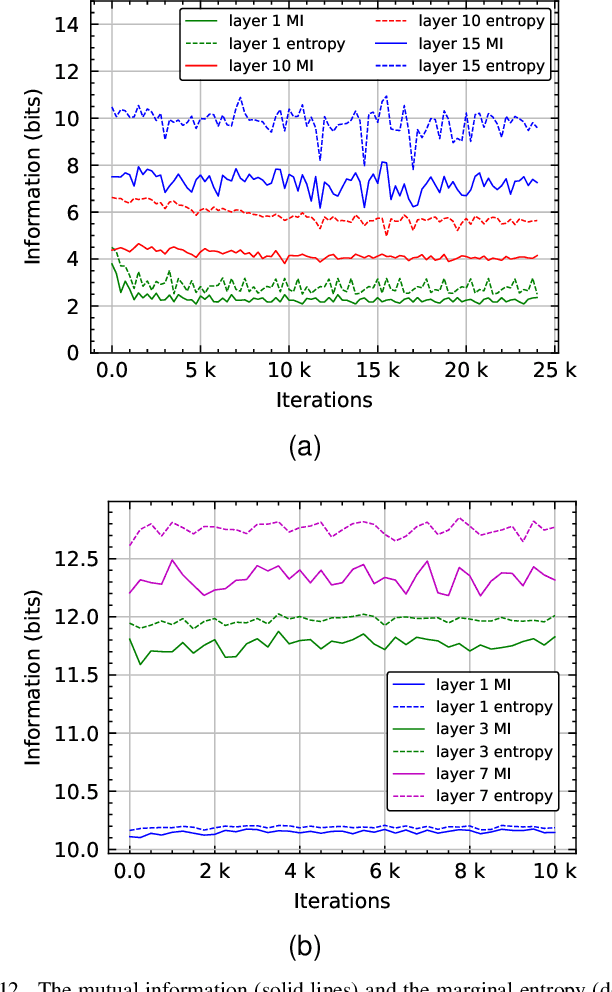
Training deep neural networks on large datasets containing high-dimensional data requires a large amount of computation. A solution to this problem is data-parallel distributed training, where a model is replicated into several computational nodes that have access to different chunks of the data. This approach, however, entails high communication rates and latency because of the computed gradients that need to be shared among nodes at every iteration. The problem becomes more pronounced in the case that there is wireless communication between the nodes (i.e. due to the limited network bandwidth). To address this problem, various compression methods have been proposed including sparsification, quantization, and entropy encoding of the gradients. Existing methods leverage the intra-node information redundancy, that is, they compress gradients at each node independently. In contrast, we advocate that the gradients across the nodes are correlated and propose methods to leverage this inter-node redundancy to improve compression efficiency. Depending on the node communication protocol (parameter server or ring-allreduce), we propose two instances of the LGC approach that we coin Learned Gradient Compression (LGC). Our methods exploit an autoencoder (i.e. trained during the first stages of the distributed training) to capture the common information that exists in the gradients of the distributed nodes. We have tested our LGC methods on the image classification and semantic segmentation tasks using different convolutional neural networks (ResNet50, ResNet101, PSPNet) and multiple datasets (ImageNet, Cifar10, CamVid). The ResNet101 model trained for image classification on Cifar10 achieved an accuracy of 93.57%, which is lower than the baseline distributed training with uncompressed gradients only by 0.18%.