 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeOn the Limits of Selective AI Prediction: A Case Study in Clinical Decision Making
Aug 11, 2025



AI has the potential to augment human decision making. However, even high-performing models can produce inaccurate predictions when deployed. These inaccuracies, combined with automation bias, where humans overrely on AI predictions, can result in worse decisions. Selective prediction, in which potentially unreliable model predictions are hidden from users, has been proposed as a solution. This approach assumes that when AI abstains and informs the user so, humans make decisions as they would without AI involvement. To test this assumption, we study the effects of selective prediction on human decisions in a clinical context. We conducted a user study of 259 clinicians tasked with diagnosing and treating hospitalized patients. We compared their baseline performance without any AI involvement to their AI-assisted accuracy with and without selective prediction. Our findings indicate that selective prediction mitigates the negative effects of inaccurate AI in terms of decision accuracy. Compared to no AI assistance, clinician accuracy declined when shown inaccurate AI predictions (66% [95% CI: 56%-75%] vs. 56% [95% CI: 46%-66%]), but recovered under selective prediction (64% [95% CI: 54%-73%]). However, while selective prediction nearly maintains overall accuracy, our results suggest that it alters patterns of mistakes: when informed the AI abstains, clinicians underdiagnose (18% increase in missed diagnoses) and undertreat (35% increase in missed treatments) compared to no AI input at all. Our findings underscore the importance of empirically validating assumptions about how humans engage with AI within human-AI systems.
What Do People Want to Know About Artificial Intelligence (AI)? The Importance of Answering End-User Questions to Explain Autonomous Vehicle (AV) Decisions
May 09, 2025



Improving end-users' understanding of decisions made by autonomous vehicles (AVs) driven by artificial intelligence (AI) can improve utilization and acceptance of AVs. However, current explanation mechanisms primarily help AI researchers and engineers in debugging and monitoring their AI systems, and may not address the specific questions of end-users, such as passengers, about AVs in various scenarios. In this paper, we conducted two user studies to investigate questions that potential AV passengers might pose while riding in an AV and evaluate how well answers to those questions improve their understanding of AI-driven AV decisions. Our initial formative study identified a range of questions about AI in autonomous driving that existing explanation mechanisms do not readily address. Our second study demonstrated that interactive text-based explanations effectively improved participants' comprehension of AV decisions compared to simply observing AV decisions. These findings inform the design of interactions that motivate end-users to engage with and inquire about the reasoning behind AI-driven AV decisions.
Audrey: A Personalized Open-Domain Conversational Bot
Nov 11, 2020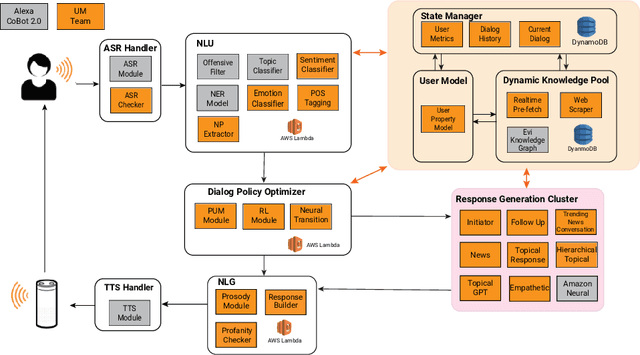


Conversational Intelligence requires that a person engage on informational, personal and relational levels. Advances in Natural Language Understanding have helped recent chatbots succeed at dialog on the informational level. However, current techniques still lag for conversing with humans on a personal level and fully relating to them. The University of Michigan's submission to the Alexa Prize Grand Challenge 3, Audrey, is an open-domain conversational chat-bot that aims to engage customers on these levels through interest driven conversations guided by customers' personalities and emotions. Audrey is built from socially-aware models such as Emotion Detection and a Personal Understanding Module to grasp a deeper understanding of users' interests and desires. Our architecture interacts with customers using a hybrid approach balanced between knowledge-driven response generators and context-driven neural response generators to cater to all three levels of conversations. During the semi-finals period, we achieved an average cumulative rating of 3.25 on a 1-5 Likert scale.