 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeInHabit: Leveraging Image Foundation Models for Scalable 3D Human Placement
Apr 21, 2026Training embodied agents to understand 3D scenes as humans do requires large-scale data of people meaningfully interacting with diverse environments, yet such data is scarce. Real-world motion capture is costly and limited to controlled settings, while existing synthetic datasets rely on simple geometric heuristics that ignore rich scene context. In contrast, 2D foundation models trained on internet-scale data have implicitly acquired commonsense knowledge of human-environment interactions. To transfer this knowledge into 3D, we introduce InHabit, a fully automatic and scalable data generator for populating 3D scenes with interacting humans. InHabit follows a render-generate-lift principle: given a rendered 3D scene, a vision-language model proposes contextually meaningful actions, an image-editing model inserts a human, and an optimization procedure lifts the edited result into physically plausible SMPL-X bodies aligned with the scene geometry. Applied to Habitat-Matterport3D, InHabit produces the first large-scale photorealistic 3D human-scene interaction dataset, containing 78K samples across 800 building-scale scenes with complete 3D geometry, SMPL-X bodies, and RGB images. Augmenting standard training data with our samples improves RGB-based 3D human-scene reconstruction and contact estimation, and in a perceptual user study our data is preferred in 78% of cases over the state of the art.
GRAFT: Geometric Refinement and Fitting Transformer for Human Scene Reconstruction
Apr 21, 2026Reconstructing physically plausible 3D human-scene interactions (HSI) from a single image currently presents a trade-off: optimization based methods offer accurate contact but are slow (~20s), while feed-forward approaches are fast yet lack explicit interaction reasoning, producing floating and interpenetration artifacts. Our key insight is that geometry-based human--scene fitting can be amortized into fast feed-forward inference. We present GRAFT (Geometric Refinement And Fitting Transformer), a learned HSI prior that predicts Interaction Gradients: corrective parameter updates that iteratively refine human meshes by reasoning about their 3D relationship to the surrounding scene. GRAFT encodes the interaction state into compact body-anchored tokens, each grounded in the scene geometry via Geometric Probes that capture spatial relationships with nearby surfaces. A lightweight transformer recurrently updates human meshes and re-probes the scene, ensuring the final pose aligns with both learned priors and observed geometry. GRAFT operates either as an end-to-end reconstructor using image features, or with geometry alone as a transferable plug-and-play HSI prior that improves feed-forward methods without retraining. Experiments show GRAFT improves interaction quality by up to 113% over state-of-the-art feed-forward methods and matches optimization-based interaction quality at ${\sim}50{\times}$ lower runtime, while generalizing seamlessly to in-the-wild multi-person scenes and being preferred in 64.8% of three-way user study. Project page: https://pradyumnaym.github.io/graft .
Are Pose Estimators Ready for the Open World? STAGE: Synthetic Data Generation Toolkit for Auditing 3D Human Pose Estimators
Aug 28, 2024



The estimation of 3D human poses from images has progressed tremendously over the last few years as measured on standard benchmarks. However, performance in the open world remains underexplored, as current benchmarks cannot capture its full extent. Especially in safety-critical systems, it is crucial that 3D pose estimators are audited before deployment, and their sensitivity towards single factors or attributes occurring in the operational domain is thoroughly examined. Nevertheless, we currently lack a benchmark that would enable such fine-grained analysis. We thus present STAGE, a GenAI data toolkit for auditing 3D human pose estimators. We enable a text-to-image model to control the 3D human body pose in the generated image. This allows us to create customized annotated data covering a wide range of open-world attributes. We leverage STAGE and generate a series of benchmarks to audit the sensitivity of popular pose estimators towards attributes such as gender, ethnicity, age, clothing, location, and weather. Our results show that the presence of such naturally occurring attributes can cause severe degradation in the performance of pose estimators and leads us to question if they are ready for open-world deployment.
The Center of Attention: Center-Keypoint Grouping via Attention for Multi-Person Pose Estimation
Oct 11, 2021



We introduce CenterGroup, an attention-based framework to estimate human poses from a set of identity-agnostic keypoints and person center predictions in an image. Our approach uses a transformer to obtain context-aware embeddings for all detected keypoints and centers and then applies multi-head attention to directly group joints into their corresponding person centers. While most bottom-up methods rely on non-learnable clustering at inference, CenterGroup uses a fully differentiable attention mechanism that we train end-to-end together with our keypoint detector. As a result, our method obtains state-of-the-art performance with up to 2.5x faster inference time than competing bottom-up methods. Our code is available at https://github.com/dvl-tum/center-group .
Assessment of Deep Convolutional Neural Networks for Road Surface Classification
Aug 07, 2018
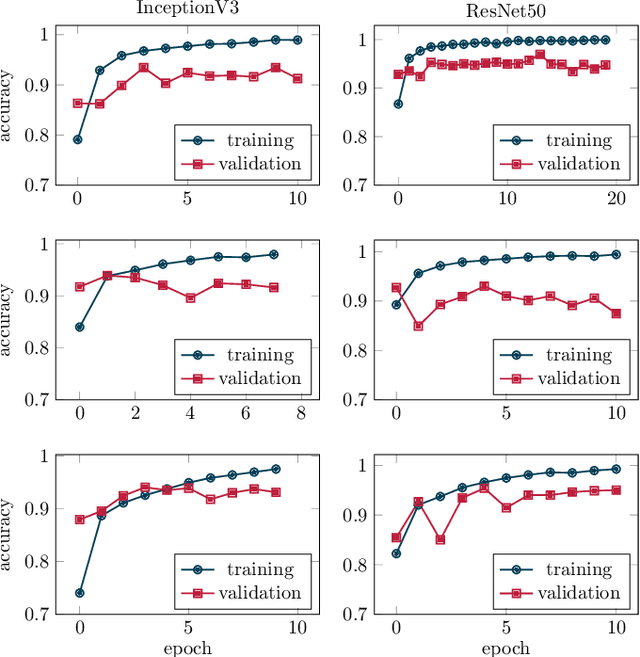


When parameterizing vehicle control algorithms for stability or trajectory control, the road-tire friction coefficient is an essential model parameter when it comes to control performance. One major impact on the friction coefficient is the condition of the road surface. A camera-based, forward-looking classification of the road-surface helps enabling an early parametrization of vehicle control algorithms. In this paper, we train and compare two different Deep Convolutional Neural Network models, regarding their application for road friction estimation and describe the challenges for training the classifier in terms of available training data and the construction of suitable datasets.