 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeAdvSumm: Adversarial Training for Bias Mitigation in Text Summarization
Jun 06, 2025Large Language Models (LLMs) have achieved impressive performance in text summarization and are increasingly deployed in real-world applications. However, these systems often inherit associative and framing biases from pre-training data, leading to inappropriate or unfair outputs in downstream tasks. In this work, we present AdvSumm (Adversarial Summarization), a domain-agnostic training framework designed to mitigate bias in text summarization through improved generalization. Inspired by adversarial robustness, AdvSumm introduces a novel Perturber component that applies gradient-guided perturbations at the embedding level of Sequence-to-Sequence models, enhancing the model's robustness to input variations. We empirically demonstrate that AdvSumm effectively reduces different types of bias in summarization-specifically, name-nationality bias and political framing bias-without compromising summarization quality. Compared to standard transformers and data augmentation techniques like back-translation, AdvSumm achieves stronger bias mitigation performance across benchmark datasets.
Layered Insights: Generalizable Analysis of Authorial Style by Leveraging All Transformer Layers
Mar 02, 2025We propose a new approach for the authorship attribution task that leverages the various linguistic representations learned at different layers of pre-trained transformer-based models. We evaluate our approach on three datasets, comparing it to a state-of-the-art baseline in in-domain and out-of-domain scenarios. We found that utilizing various transformer layers improves the robustness of authorship attribution models when tested on out-of-domain data, resulting in new state-of-the-art results. Our analysis gives further insights into how our model's different layers get specialized in representing certain stylistic features that benefit the model when tested out of the domain.
Using Distributional Thesaurus Embedding for Co-hyponymy Detection
Feb 24, 2020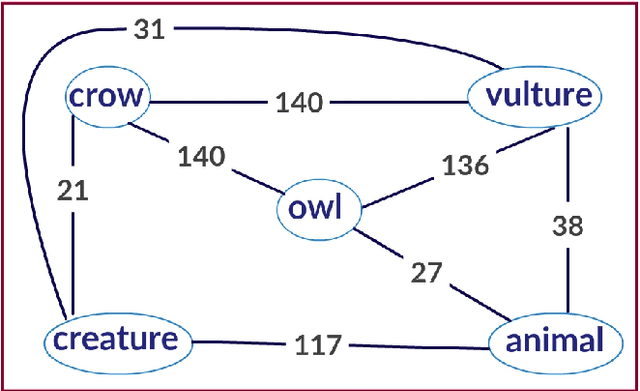

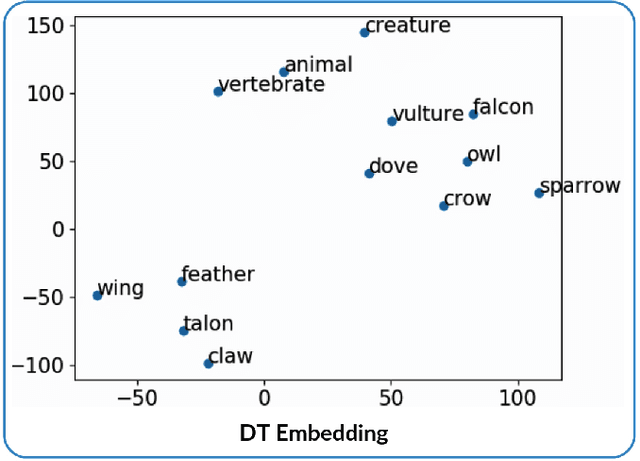
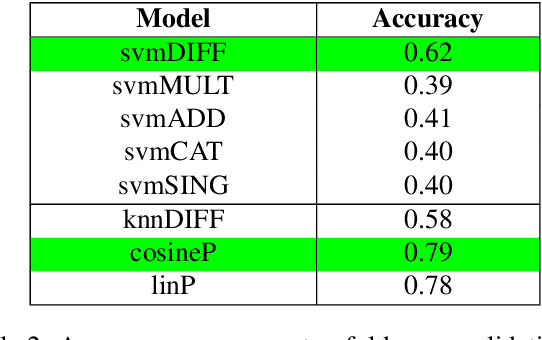
Discriminating lexical relations among distributionally similar words has always been a challenge for natural language processing (NLP) community. In this paper, we investigate whether the network embedding of distributional thesaurus can be effectively utilized to detect co-hyponymy relations. By extensive experiments over three benchmark datasets, we show that the vector representation obtained by applying node2vec on distributional thesaurus outperforms the state-of-the-art models for binary classification of co-hyponymy vs. hypernymy, as well as co-hyponymy vs. meronymy, by huge margins.