 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeDoes AI See like Art Historians? Interpreting How Vision Language Models Recognize Artistic Style
Mar 11, 2026VLMs have become increasingly proficient at a range of computer vision tasks, such as visual question answering and object detection. This includes increasingly strong capabilities in the domain of art, from analyzing artwork to generation of art. In an interdisciplinary collaboration between computer scientists and art historians, we characterize the mechanisms underlying VLMs' ability to predict artistic style and assess the extent to which they align with the criteria art historians use to reason about artistic style. We employ a latent-space decomposition approach to identify concepts that drive art style prediction and conduct quantitative evaluations, causal analysis and assessment by art historians. Our findings indicate that 73% of the extracted concepts are judged by art historians to exhibit a coherent and semantically meaningful visual feature and 90% of concepts used to predict style of a given artwork were judged relevant. In cases where an irrelevant concept was used to successfully predict style, art historians identified possible reasons for its success; for example, the model might "understand" a concept in more formal terms, such as dark/light contrasts.
LLMs as Science Journalists: Supporting Early-stage Researchers in Communicating Their Science to the Public
Jan 09, 2026The scientific community needs tools that help early-stage researchers effectively communicate their findings and innovations to the public. Although existing general-purpose Large Language Models (LLMs) can assist in this endeavor, they are not optimally aligned for it. To address this, we propose a framework for training LLMs to emulate the role of a science journalist that can be used by early-stage researchers to learn how to properly communicate their papers to the general public. We evaluate the usefulness of our trained LLM Journalists in leading conversations with both simulated and human researchers. %compared to the general-purpose ones. Our experiments indicate that LLMs trained using our framework ask more relevant questions that address the societal impact of research, prompting researchers to clarify and elaborate on their findings. In the user study, the majority of participants who interacted with our trained LLM Journalist appreciated it more than interacting with general-purpose LLMs.
Layered Insights: Generalizable Analysis of Authorial Style by Leveraging All Transformer Layers
Mar 02, 2025We propose a new approach for the authorship attribution task that leverages the various linguistic representations learned at different layers of pre-trained transformer-based models. We evaluate our approach on three datasets, comparing it to a state-of-the-art baseline in in-domain and out-of-domain scenarios. We found that utilizing various transformer layers improves the robustness of authorship attribution models when tested on out-of-domain data, resulting in new state-of-the-art results. Our analysis gives further insights into how our model's different layers get specialized in representing certain stylistic features that benefit the model when tested out of the domain.
Latent Space Interpretation for Stylistic Analysis and Explainable Authorship Attribution
Sep 11, 2024



Recent state-of-the-art authorship attribution methods learn authorship representations of texts in a latent, non-interpretable space, hindering their usability in real-world applications. Our work proposes a novel approach to interpreting these learned embeddings by identifying representative points in the latent space and utilizing LLMs to generate informative natural language descriptions of the writing style of each point. We evaluate the alignment of our interpretable space with the latent one and find that it achieves the best prediction agreement compared to other baselines. Additionally, we conduct a human evaluation to assess the quality of these style descriptions, validating their utility as explanations for the latent space. Finally, we investigate whether human performance on the challenging AA task improves when aided by our system's explanations, finding an average improvement of around +20% in accuracy.
"Is ChatGPT a Better Explainer than My Professor?": Evaluating the Explanation Capabilities of LLMs in Conversation Compared to a Human Baseline
Jun 26, 2024Explanations form the foundation of knowledge sharing and build upon communication principles, social dynamics, and learning theories. We focus specifically on conversational approaches for explanations because the context is highly adaptive and interactive. Our research leverages previous work on explanatory acts, a framework for understanding the different strategies that explainers and explainees employ in a conversation to both explain, understand, and engage with the other party. We use the 5-Levels dataset was constructed from the WIRED YouTube series by Wachsmuth et al., and later annotated by Booshehri et al. with explanatory acts. These annotations provide a framework for understanding how explainers and explainees structure their response when crafting a response. With the rise of generative AI in the past year, we hope to better understand the capabilities of Large Language Models (LLMs) and how they can augment expert explainer's capabilities in conversational settings. To achieve this goal, the 5-Levels dataset (We use Booshehri et al.'s 2023 annotated dataset with explanatory acts.) allows us to audit the ability of LLMs in engaging in explanation dialogues. To evaluate the effectiveness of LLMs in generating explainer responses, we compared 3 different strategies, we asked human annotators to evaluate 3 different strategies: human explainer response, GPT4 standard response, GPT4 response with Explanation Moves.
Modeling the Quality of Dialogical Explanations
Mar 01, 2024Explanations are pervasive in our lives. Mostly, they occur in dialogical form where an {\em explainer} discusses a concept or phenomenon of interest with an {\em explainee}. Leaving the explainee with a clear understanding is not straightforward due to the knowledge gap between the two participants. Previous research looked at the interaction of explanation moves, dialogue acts, and topics in successful dialogues with expert explainers. However, daily-life explanations often fail, raising the question of what makes a dialogue successful. In this work, we study explanation dialogues in terms of the interactions between the explainer and explainee and how they correlate with the quality of explanations in terms of a successful understanding on the explainee's side. In particular, we first construct a corpus of 399 dialogues from the Reddit forum {\em Explain Like I am Five} and annotate it for interaction flows and explanation quality. We then analyze the interaction flows, comparing them to those appearing in expert dialogues. Finally, we encode the interaction flows using two language models that can handle long inputs, and we provide empirical evidence for the effectiveness boost gained through the encoding in predicting the success of explanation dialogues.
The Touché23-ValueEval Dataset for Identifying Human Values behind Arguments
Jan 31, 2023



We present the Touch\'e23-ValueEval Dataset for Identifying Human Values behind Arguments. To investigate approaches for the automated detection of human values behind arguments, we collected 9324 arguments from 6 diverse sources, covering religious texts, political discussions, free-text arguments, newspaper editorials, and online democracy platforms. Each argument was annotated by 3 crowdworkers for 54 values. The Touch\'e23-ValueEval dataset extends the Webis-ArgValues-22. In comparison to the previous dataset, the effectiveness of a 1-Baseline decreases, but that of an out-of-the-box BERT model increases. Therefore, though the classification difficulty increased as per the label distribution, the larger dataset allows for training better models.
Conclusion-based Counter-Argument Generation
Jan 24, 2023In real-world debates, the most common way to counter an argument is to reason against its main point, that is, its conclusion. Existing work on the automatic generation of natural language counter-arguments does not address the relation to the conclusion, possibly because many arguments leave their conclusion implicit. In this paper, we hypothesize that the key to effective counter-argument generation is to explicitly model the argument's conclusion and to ensure that the stance of the generated counter is opposite to that conclusion. In particular, we propose a multitask approach that jointly learns to generate both the conclusion and the counter of an input argument. The approach employs a stance-based ranking component that selects the counter from a diverse set of generated candidates whose stance best opposes the generated conclusion. In both automatic and manual evaluation, we provide evidence that our approach generates more relevant and stance-adhering counters than strong baselines.
"Mama Always Had a Way of Explaining Things So I Could Understand'': A Dialogue Corpus for Learning to Construct Explanations
Sep 06, 2022
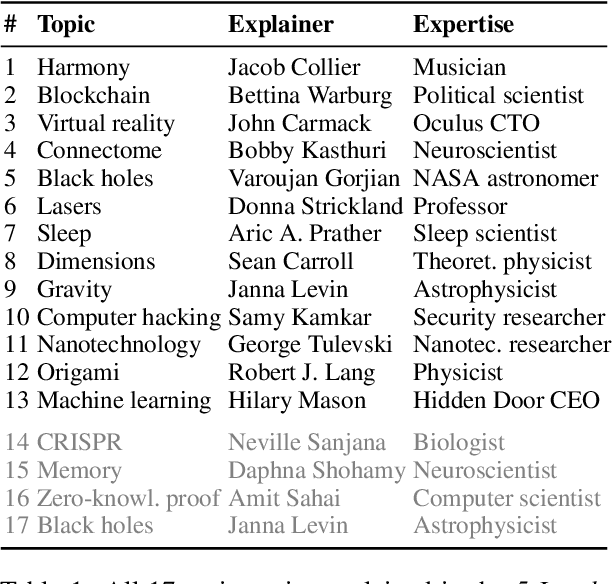
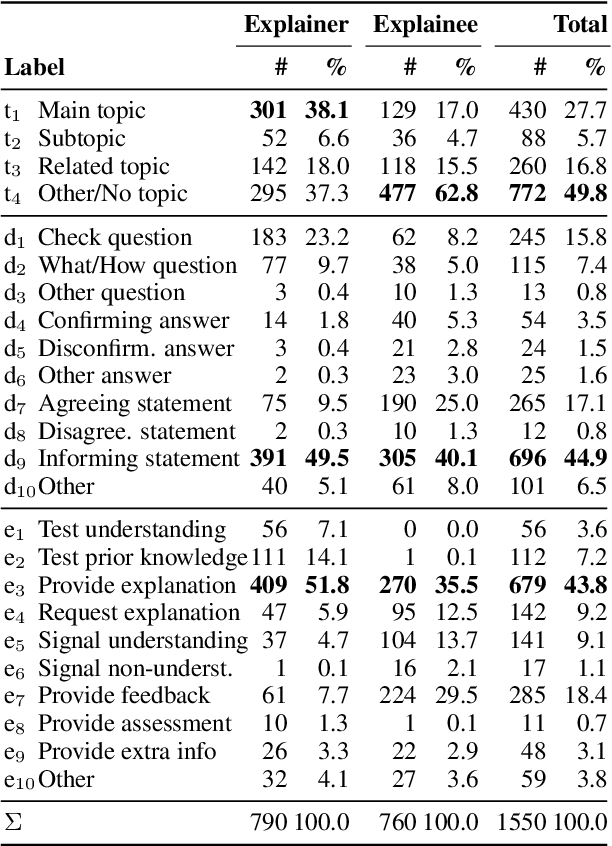
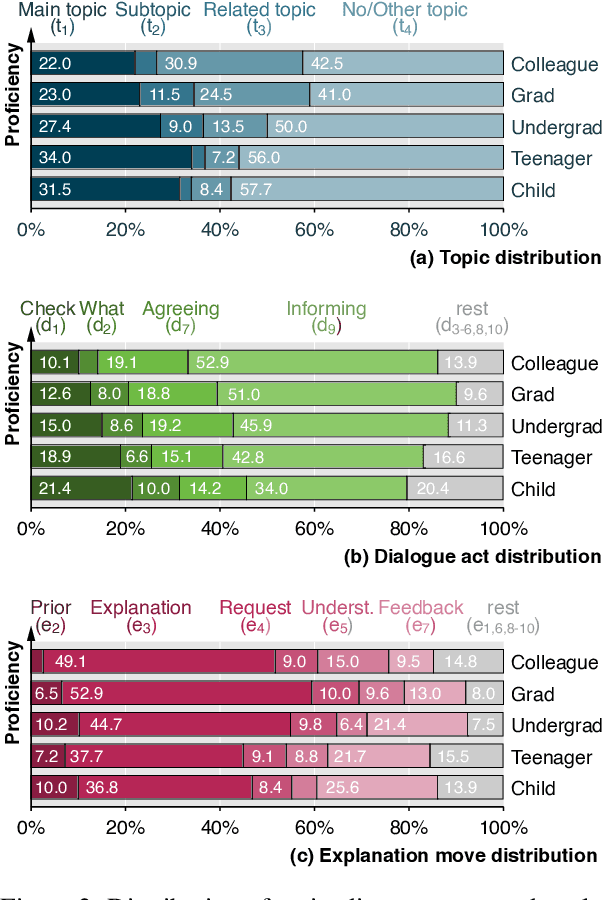
As AI is more and more pervasive in everyday life, humans have an increasing demand to understand its behavior and decisions. Most research on explainable AI builds on the premise that there is one ideal explanation to be found. In fact, however, everyday explanations are co-constructed in a dialogue between the person explaining (the explainer) and the specific person being explained to (the explainee). In this paper, we introduce a first corpus of dialogical explanations to enable NLP research on how humans explain as well as on how AI can learn to imitate this process. The corpus consists of 65 transcribed English dialogues from the Wired video series \emph{5 Levels}, explaining 13 topics to five explainees of different proficiency. All 1550 dialogue turns have been manually labeled by five independent professionals for the topic discussed as well as for the dialogue act and the explanation move performed. We analyze linguistic patterns of explainers and explainees, and we explore differences across proficiency levels. BERT-based baseline results indicate that sequence information helps predicting topics, acts, and moves effectively
The Moral Debater: A Study on the Computational Generation of Morally Framed Arguments
Mar 28, 2022
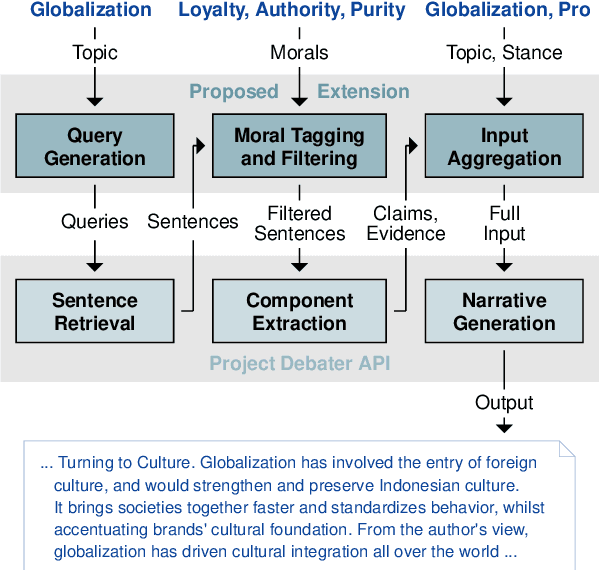
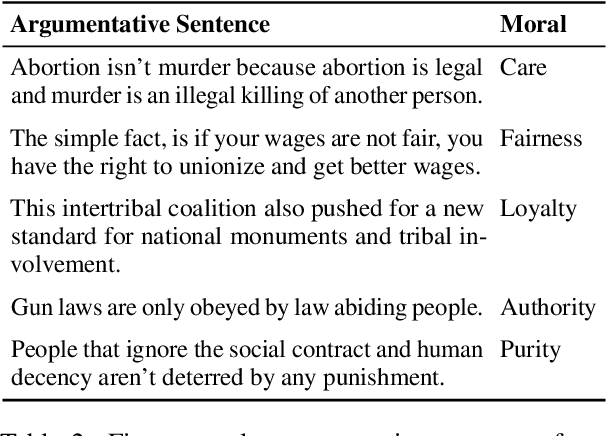
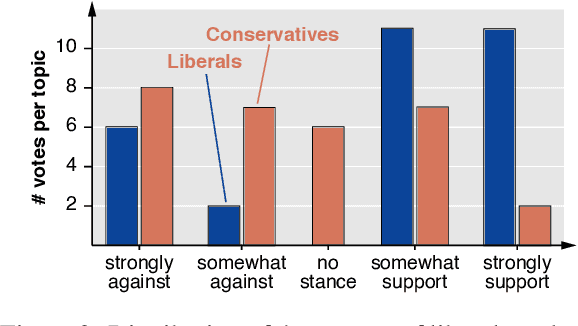
An audience's prior beliefs and morals are strong indicators of how likely they will be affected by a given argument. Utilizing such knowledge can help focus on shared values to bring disagreeing parties towards agreement. In argumentation technology, however, this is barely exploited so far. This paper studies the feasibility of automatically generating morally framed arguments as well as their effect on different audiences. Following the moral foundation theory, we propose a system that effectively generates arguments focusing on different morals. In an in-depth user study, we ask liberals and conservatives to evaluate the impact of these arguments. Our results suggest that, particularly when prior beliefs are challenged, an audience becomes more affected by morally framed arguments.