 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeStanding on FURM ground -- A framework for evaluating Fair, Useful, and Reliable AI Models in healthcare systems
Mar 14, 2024



The impact of using artificial intelligence (AI) to guide patient care or operational processes is an interplay of the AI model's output, the decision-making protocol based on that output, and the capacity of the stakeholders involved to take the necessary subsequent action. Estimating the effects of this interplay before deployment, and studying it in real time afterwards, are essential to bridge the chasm between AI model development and achievable benefit. To accomplish this, the Data Science team at Stanford Health Care has developed a Testing and Evaluation (T&E) mechanism to identify fair, useful and reliable AI models (FURM) by conducting an ethical review to identify potential value mismatches, simulations to estimate usefulness, financial projections to assess sustainability, as well as analyses to determine IT feasibility, design a deployment strategy, and recommend a prospective monitoring and evaluation plan. We report on FURM assessments done to evaluate six AI guided solutions for potential adoption, spanning clinical and operational settings, each with the potential to impact from several dozen to tens of thousands of patients each year. We describe the assessment process, summarize the six assessments, and share our framework to enable others to conduct similar assessments. Of the six solutions we assessed, two have moved into a planning and implementation phase. Our novel contributions - usefulness estimates by simulation, financial projections to quantify sustainability, and a process to do ethical assessments - as well as their underlying methods and open source tools, are available for other healthcare systems to conduct actionable evaluations of candidate AI solutions.
Zero-Shot Clinical Trial Patient Matching with LLMs
Feb 05, 2024



Matching patients to clinical trials is a key unsolved challenge in bringing new drugs to market. Today, identifying patients who meet a trial's eligibility criteria is highly manual, taking up to 1 hour per patient. Automated screening is challenging, however, as it requires understanding unstructured clinical text. Large language models (LLMs) offer a promising solution. In this work, we explore their application to trial matching. First, we design an LLM-based system which, given a patient's medical history as unstructured clinical text, evaluates whether that patient meets a set of inclusion criteria (also specified as free text). Our zero-shot system achieves state-of-the-art scores on the n2c2 2018 cohort selection benchmark. Second, we improve the data and cost efficiency of our method by identifying a prompting strategy which matches patients an order of magnitude faster and more cheaply than the status quo, and develop a two-stage retrieval pipeline that reduces the number of tokens processed by up to a third while retaining high performance. Third, we evaluate the interpretability of our system by having clinicians evaluate the natural language justifications generated by the LLM for each eligibility decision, and show that it can output coherent explanations for 97% of its correct decisions and 75% of its incorrect ones. Our results establish the feasibility of using LLMs to accelerate clinical trial operations.
INSPECT: A Multimodal Dataset for Pulmonary Embolism Diagnosis and Prognosis
Nov 17, 2023



Synthesizing information from multiple data sources plays a crucial role in the practice of modern medicine. Current applications of artificial intelligence in medicine often focus on single-modality data due to a lack of publicly available, multimodal medical datasets. To address this limitation, we introduce INSPECT, which contains de-identified longitudinal records from a large cohort of patients at risk for pulmonary embolism (PE), along with ground truth labels for multiple outcomes. INSPECT contains data from 19,402 patients, including CT images, radiology report impression sections, and structured electronic health record (EHR) data (i.e. demographics, diagnoses, procedures, vitals, and medications). Using INSPECT, we develop and release a benchmark for evaluating several baseline modeling approaches on a variety of important PE related tasks. We evaluate image-only, EHR-only, and multimodal fusion models. Trained models and the de-identified dataset are made available for non-commercial use under a data use agreement. To the best of our knowledge, INSPECT is the largest multimodal dataset integrating 3D medical imaging and EHR for reproducible methods evaluation and research.
MedAlign: A Clinician-Generated Dataset for Instruction Following with Electronic Medical Records
Aug 27, 2023



The ability of large language models (LLMs) to follow natural language instructions with human-level fluency suggests many opportunities in healthcare to reduce administrative burden and improve quality of care. However, evaluating LLMs on realistic text generation tasks for healthcare remains challenging. Existing question answering datasets for electronic health record (EHR) data fail to capture the complexity of information needs and documentation burdens experienced by clinicians. To address these challenges, we introduce MedAlign, a benchmark dataset of 983 natural language instructions for EHR data. MedAlign is curated by 15 clinicians (7 specialities), includes clinician-written reference responses for 303 instructions, and provides 276 longitudinal EHRs for grounding instruction-response pairs. We used MedAlign to evaluate 6 general domain LLMs, having clinicians rank the accuracy and quality of each LLM response. We found high error rates, ranging from 35% (GPT-4) to 68% (MPT-7B-Instruct), and an 8.3% drop in accuracy moving from 32k to 2k context lengths for GPT-4. Finally, we report correlations between clinician rankings and automated natural language generation metrics as a way to rank LLMs without human review. We make MedAlign available under a research data use agreement to enable LLM evaluations on tasks aligned with clinician needs and preferences.
All models are local: time to replace external validation with recurrent local validation
May 13, 2023External validation is often recommended to ensure the generalizability of ML models. However, it neither guarantees generalizability nor equates to a model's clinical usefulness (the ultimate goal of any clinical decision-support tool). External validation is misaligned with current healthcare ML needs. First, patient data changes across time, geography, and facilities. These changes create significant volatility in the performance of a single fixed model (especially for deep learning models, which dominate clinical ML). Second, newer ML techniques, current market forces, and updated regulatory frameworks are enabling frequent updating and monitoring of individual deployed model instances. We submit that external validation is insufficient to establish ML models' safety or utility. Proposals to fix the external validation paradigm do not go far enough. Continued reliance on it as the ultimate test is likely to lead us astray. We propose the MLOps-inspired paradigm of recurring local validation as an alternative that ensures the validity of models while protecting against performance-disruptive data variability. This paradigm relies on site-specific reliability tests before every deployment, followed by regular and recurrent checks throughout the life cycle of the deployed algorithm. Initial and recurrent reliability tests protect against performance-disruptive distribution shifts, and concept drifts that jeopardize patient safety.
Evaluation of GPT-3.5 and GPT-4 for supporting real-world information needs in healthcare delivery
May 01, 2023


Despite growing interest in using large language models (LLMs) in healthcare, current explorations do not assess the real-world utility and safety of LLMs in clinical settings. Our objective was to determine whether two LLMs can serve information needs submitted by physicians as questions to an informatics consultation service in a safe and concordant manner. Sixty six questions from an informatics consult service were submitted to GPT-3.5 and GPT-4 via simple prompts. 12 physicians assessed the LLM responses' possibility of patient harm and concordance with existing reports from an informatics consultation service. Physician assessments were summarized based on majority vote. For no questions did a majority of physicians deem either LLM response as harmful. For GPT-3.5, responses to 8 questions were concordant with the informatics consult report, 20 discordant, and 9 were unable to be assessed. There were 29 responses with no majority on "Agree", "Disagree", and "Unable to assess". For GPT-4, responses to 13 questions were concordant, 15 discordant, and 3 were unable to be assessed. There were 35 responses with no majority. Responses from both LLMs were largely devoid of overt harm, but less than 20% of the responses agreed with an answer from an informatics consultation service, responses contained hallucinated references, and physicians were divided on what constitutes harm. These results suggest that while general purpose LLMs are able to provide safe and credible responses, they often do not meet the specific information need of a given question. A definitive evaluation of the usefulness of LLMs in healthcare settings will likely require additional research on prompt engineering, calibration, and custom-tailoring of general purpose models.
The Shaky Foundations of Clinical Foundation Models: A Survey of Large Language Models and Foundation Models for EMRs
Mar 24, 2023



The successes of foundation models such as ChatGPT and AlphaFold have spurred significant interest in building similar models for electronic medical records (EMRs) to improve patient care and hospital operations. However, recent hype has obscured critical gaps in our understanding of these models' capabilities. We review over 80 foundation models trained on non-imaging EMR data (i.e. clinical text and/or structured data) and create a taxonomy delineating their architectures, training data, and potential use cases. We find that most models are trained on small, narrowly-scoped clinical datasets (e.g. MIMIC-III) or broad, public biomedical corpora (e.g. PubMed) and are evaluated on tasks that do not provide meaningful insights on their usefulness to health systems. In light of these findings, we propose an improved evaluation framework for measuring the benefits of clinical foundation models that is more closely grounded to metrics that matter in healthcare.
DEPLOYR: A technical framework for deploying custom real-time machine learning models into the electronic medical record
Mar 11, 2023


Machine learning (ML) applications in healthcare are extensively researched, but successful translations to the bedside are scant. Healthcare institutions are establishing frameworks to govern and promote the implementation of accurate, actionable and reliable models that integrate with clinical workflow. Such governance frameworks require an accompanying technical framework to deploy models in a resource efficient manner. Here we present DEPLOYR, a technical framework for enabling real-time deployment and monitoring of researcher created clinical ML models into a widely used electronic medical record (EMR) system. We discuss core functionality and design decisions, including mechanisms to trigger inference based on actions within EMR software, modules that collect real-time data to make inferences, mechanisms that close-the-loop by displaying inferences back to end-users within their workflow, monitoring modules that track performance of deployed models over time, silent deployment capabilities, and mechanisms to prospectively evaluate a deployed model's impact. We demonstrate the use of DEPLOYR by silently deploying and prospectively evaluating twelve ML models triggered by clinician button-clicks in Stanford Health Care's production instance of Epic. Our study highlights the need and feasibility for such silent deployment, because prospectively measured performance varies from retrospective estimates. By describing DEPLOYR, we aim to inform ML deployment best practices and help bridge the model implementation gap.
Instability in clinical risk stratification models using deep learning
Nov 20, 2022



While it has been well known in the ML community that deep learning models suffer from instability, the consequences for healthcare deployments are under characterised. We study the stability of different model architectures trained on electronic health records, using a set of outpatient prediction tasks as a case study. We show that repeated training runs of the same deep learning model on the same training data can result in significantly different outcomes at a patient level even though global performance metrics remain stable. We propose two stability metrics for measuring the effect of randomness of model training, as well as mitigation strategies for improving model stability.
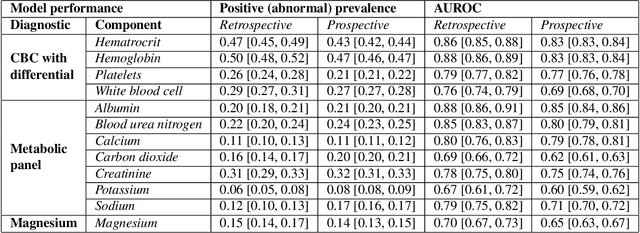
Net benefit, calibration, threshold selection, and training objectives for algorithmic fairness in healthcare
Feb 03, 2022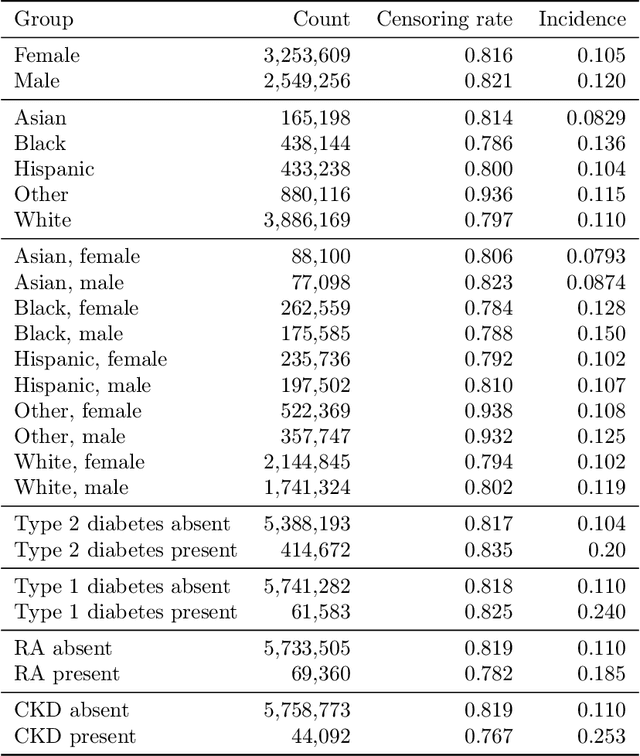
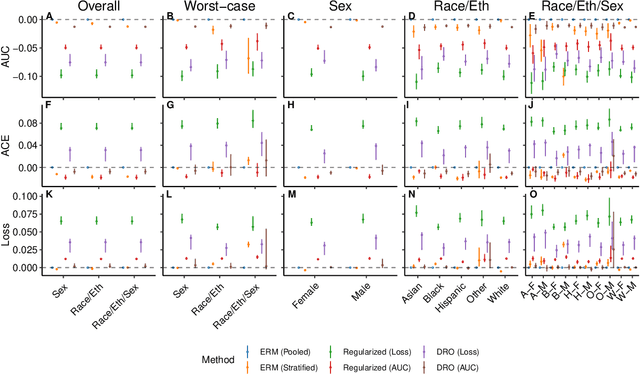
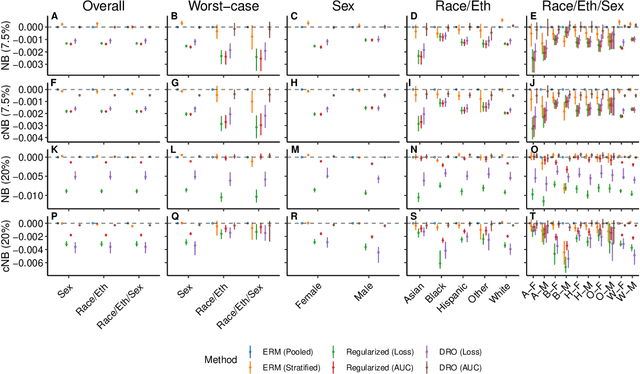
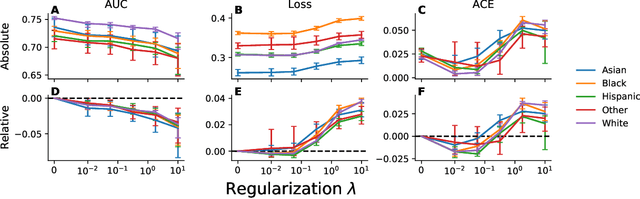
A growing body of work uses the paradigm of algorithmic fairness to frame the development of techniques to anticipate and proactively mitigate the introduction or exacerbation of health inequities that may follow from the use of model-guided decision-making. We evaluate the interplay between measures of model performance, fairness, and the expected utility of decision-making to offer practical recommendations for the operationalization of algorithmic fairness principles for the development and evaluation of predictive models in healthcare. We conduct an empirical case-study via development of models to estimate the ten-year risk of atherosclerotic cardiovascular disease to inform statin initiation in accordance with clinical practice guidelines. We demonstrate that approaches that incorporate fairness considerations into the model training objective typically do not improve model performance or confer greater net benefit for any of the studied patient populations compared to the use of standard learning paradigms followed by threshold selection concordant with patient preferences, evidence of intervention effectiveness, and model calibration. These results hold when the measured outcomes are not subject to differential measurement error across patient populations and threshold selection is unconstrained, regardless of whether differences in model performance metrics, such as in true and false positive error rates, are present. In closing, we argue for focusing model development efforts on developing calibrated models that predict outcomes well for all patient populations while emphasizing that such efforts are complementary to transparent reporting, participatory design, and reasoning about the impact of model-informed interventions in context.