 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeArchitectural Backdoors in Neural Networks
Jun 15, 2022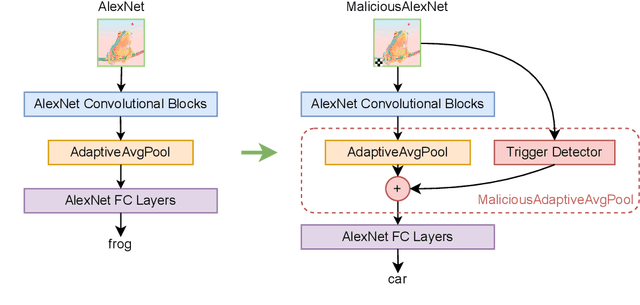
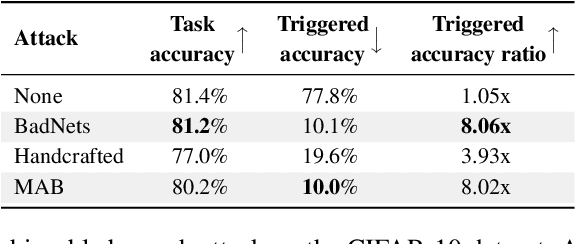
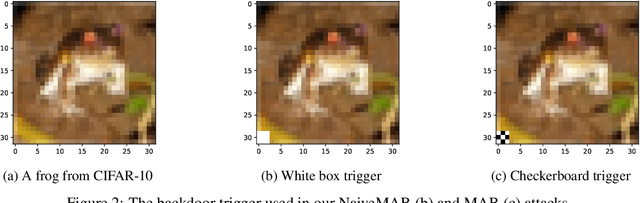

Machine learning is vulnerable to adversarial manipulation. Previous literature has demonstrated that at the training stage attackers can manipulate data and data sampling procedures to control model behaviour. A common attack goal is to plant backdoors i.e. force the victim model to learn to recognise a trigger known only by the adversary. In this paper, we introduce a new class of backdoor attacks that hide inside model architectures i.e. in the inductive bias of the functions used to train. These backdoors are simple to implement, for instance by publishing open-source code for a backdoored model architecture that others will reuse unknowingly. We demonstrate that model architectural backdoors represent a real threat and, unlike other approaches, can survive a complete re-training from scratch. We formalise the main construction principles behind architectural backdoors, such as a link between the input and the output, and describe some possible protections against them. We evaluate our attacks on computer vision benchmarks of different scales and demonstrate the underlying vulnerability is pervasive in a variety of training settings.
Selective Classification Via Neural Network Training Dynamics
May 26, 2022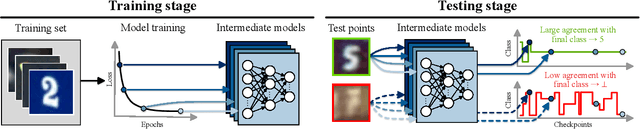
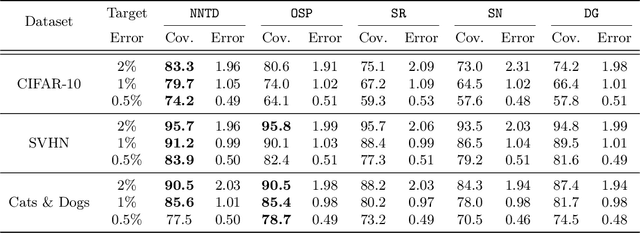
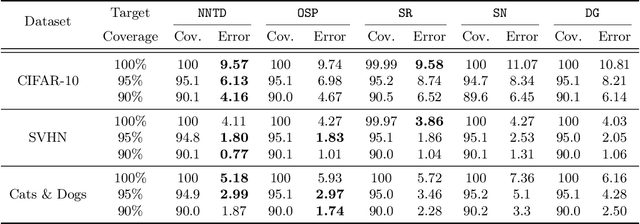
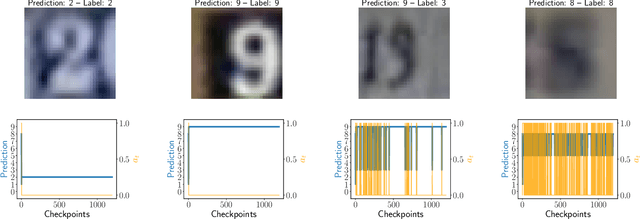
Selective classification is the task of rejecting inputs a model would predict incorrectly on through a trade-off between input space coverage and model accuracy. Current methods for selective classification impose constraints on either the model architecture or the loss function; this inhibits their usage in practice. In contrast to prior work, we show that state-of-the-art selective classification performance can be attained solely from studying the (discretized) training dynamics of a model. We propose a general framework that, for a given test input, monitors metrics capturing the disagreement with the final predicted label over intermediate models obtained during training; we then reject data points exhibiting too much disagreement at late stages in training. In particular, we instantiate a method that tracks when the label predicted during training stops disagreeing with the final predicted label. Our experimental evaluation shows that our method achieves state-of-the-art accuracy/coverage trade-offs on typical selective classification benchmarks. For example, we improve coverage on CIFAR-10/SVHN by 10.1%/1.5% respectively at a fixed target error of 0.5%.
On the Difficulty of Defending Self-Supervised Learning against Model Extraction
May 16, 2022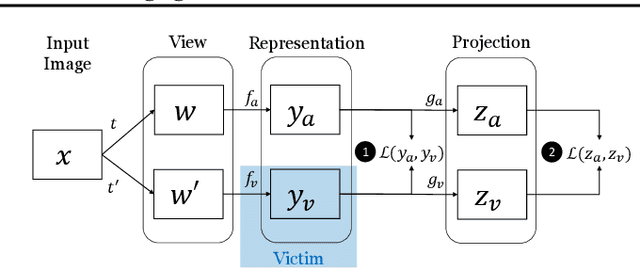
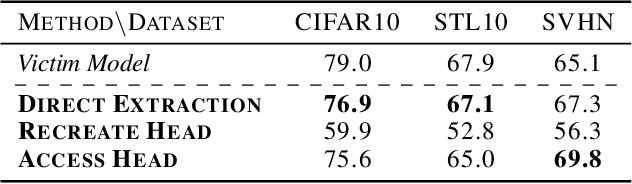
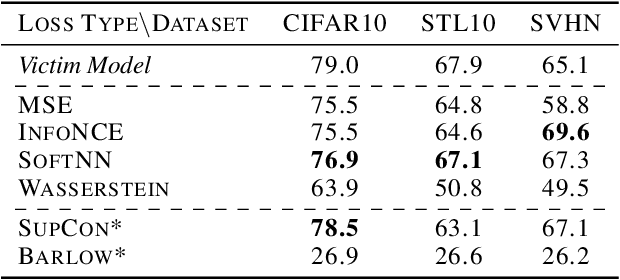
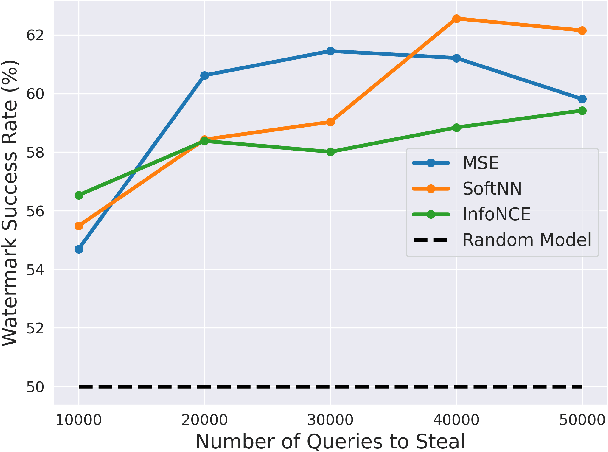
Self-Supervised Learning (SSL) is an increasingly popular ML paradigm that trains models to transform complex inputs into representations without relying on explicit labels. These representations encode similarity structures that enable efficient learning of multiple downstream tasks. Recently, ML-as-a-Service providers have commenced offering trained SSL models over inference APIs, which transform user inputs into useful representations for a fee. However, the high cost involved to train these models and their exposure over APIs both make black-box extraction a realistic security threat. We thus explore model stealing attacks against SSL. Unlike traditional model extraction on classifiers that output labels, the victim models here output representations; these representations are of significantly higher dimensionality compared to the low-dimensional prediction scores output by classifiers. We construct several novel attacks and find that approaches that train directly on a victim's stolen representations are query efficient and enable high accuracy for downstream models. We then show that existing defenses against model extraction are inadequate and not easily retrofitted to the specificities of SSL.
Is Fairness Only Metric Deep? Evaluating and Addressing Subgroup Gaps in Deep Metric Learning
Mar 23, 2022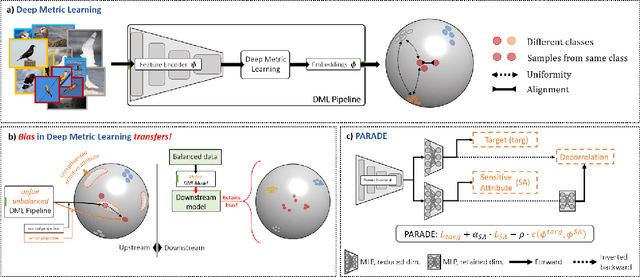
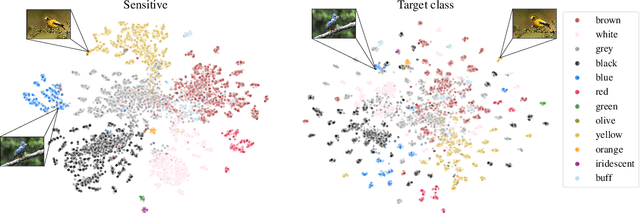
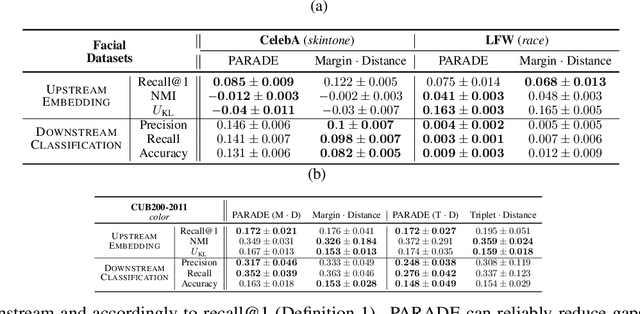
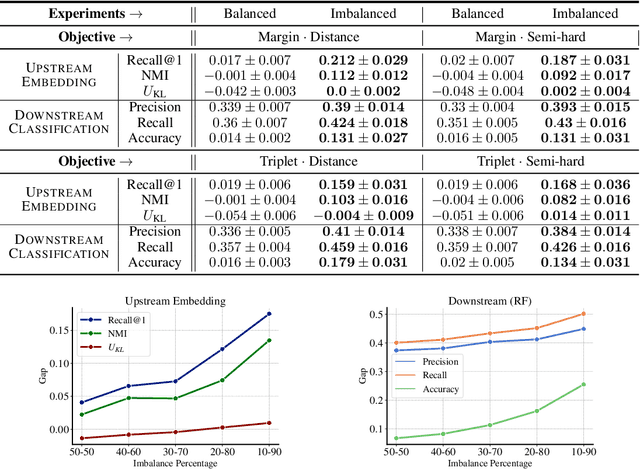
Deep metric learning (DML) enables learning with less supervision through its emphasis on the similarity structure of representations. There has been much work on improving generalization of DML in settings like zero-shot retrieval, but little is known about its implications for fairness. In this paper, we are the first to evaluate state-of-the-art DML methods trained on imbalanced data, and to show the negative impact these representations have on minority subgroup performance when used for downstream tasks. In this work, we first define fairness in DML through an analysis of three properties of the representation space -- inter-class alignment, intra-class alignment, and uniformity -- and propose finDML, the fairness in non-balanced DML benchmark to characterize representation fairness. Utilizing finDML, we find bias in DML representations to propagate to common downstream classification tasks. Surprisingly, this bias is propagated even when training data in the downstream task is re-balanced. To address this problem, we present Partial Attribute De-correlation (PARADE) to de-correlate feature representations from sensitive attributes and reduce performance gaps between subgroups in both embedding space and downstream metrics.
Bounding Membership Inference
Feb 24, 2022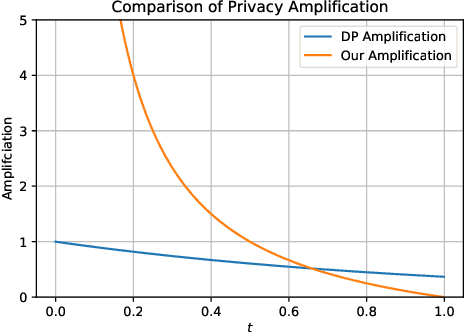

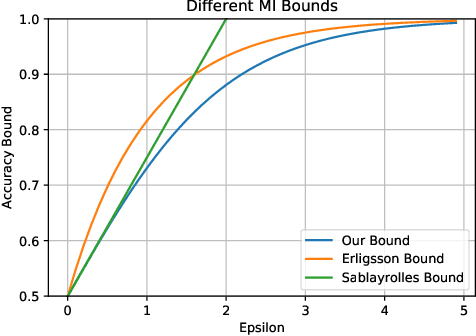
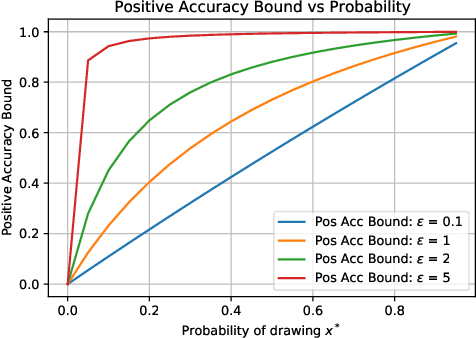
Differential Privacy (DP) is the de facto standard for reasoning about the privacy guarantees of a training algorithm. Despite the empirical observation that DP reduces the vulnerability of models to existing membership inference (MI) attacks, a theoretical underpinning as to why this is the case is largely missing in the literature. In practice, this means that models need to be trained with DP guarantees that greatly decrease their accuracy. In this paper, we provide a tighter bound on the accuracy of any MI adversary when a training algorithm provides $\epsilon$-DP. Our bound informs the design of a novel privacy amplification scheme, where an effective training set is sub-sampled from a larger set prior to the beginning of training, to greatly reduce the bound on MI accuracy. As a result, our scheme enables $\epsilon$-DP users to employ looser DP guarantees when training their model to limit the success of any MI adversary; this ensures that the model's accuracy is less impacted by the privacy guarantee. Finally, we discuss implications of our MI bound on the field of machine unlearning.
Differentially Private Speaker Anonymization
Feb 23, 2022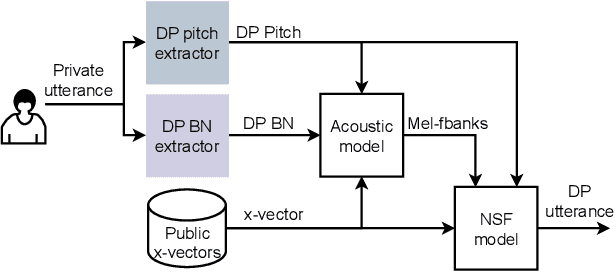
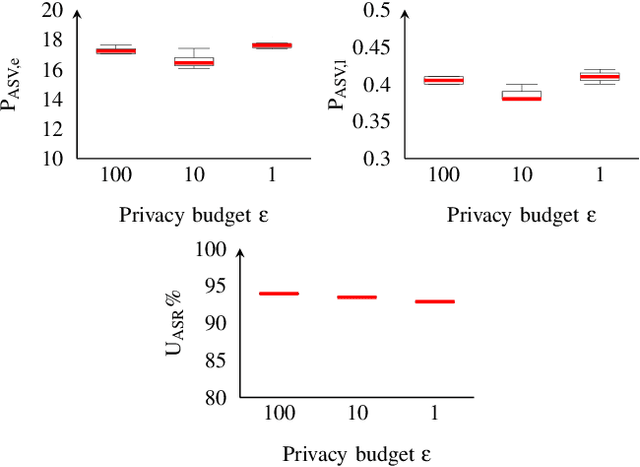
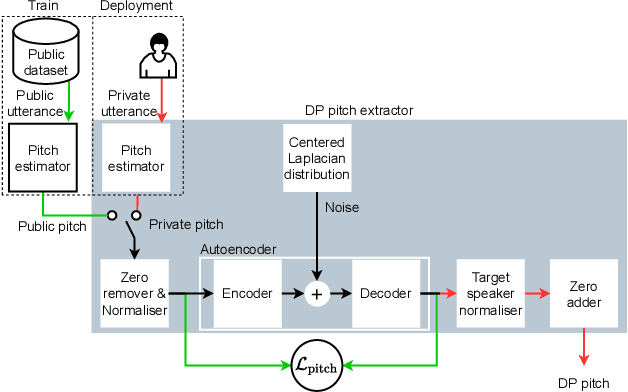
Sharing real-world speech utterances is key to the training and deployment of voice-based services. However, it also raises privacy risks as speech contains a wealth of personal data. Speaker anonymization aims to remove speaker information from a speech utterance while leaving its linguistic and prosodic attributes intact. State-of-the-art techniques operate by disentangling the speaker information (represented via a speaker embedding) from these attributes and re-synthesizing speech based on the speaker embedding of another speaker. Prior research in the privacy community has shown that anonymization often provides brittle privacy protection, even less so any provable guarantee. In this work, we show that disentanglement is indeed not perfect: linguistic and prosodic attributes still contain speaker information. We remove speaker information from these attributes by introducing differentially private feature extractors based on an autoencoder and an automatic speech recognizer, respectively, trained using noise layers. We plug these extractors in the state-of-the-art anonymization pipeline and generate, for the first time, differentially private utterances with a provable upper bound on the speaker information they contain. We evaluate empirically the privacy and utility resulting from our differentially private speaker anonymization approach on the LibriSpeech data set. Experimental results show that the generated utterances retain very high utility for automatic speech recognition training and inference, while being much better protected against strong adversaries who leverage the full knowledge of the anonymization process to try to infer the speaker identity.
Pipe Overflow: Smashing Voice Authentication for Fun and Profit
Feb 06, 2022



Recent years have seen a surge of popularity of acoustics-enabled personal devices powered by machine learning. Yet, machine learning has proven to be vulnerable to adversarial examples. Large number of modern systems protect themselves against such attacks by targeting the artificiality, i.e., they deploy mechanisms to detect the lack of human involvement in generating the adversarial examples. However, these defenses implicitly assume that humans are incapable of producing meaningful and targeted adversarial examples. In this paper, we show that this base assumption is wrong. In particular, we demonstrate that for tasks like speaker identification, a human is capable of producing analog adversarial examples directly with little cost and supervision: by simply speaking through a tube, an adversary reliably impersonates other speakers in eyes of ML models for speaker identification. Our findings extend to a range of other acoustic-biometric tasks such as liveness, bringing into question their use in security-critical settings in real life, such as phone banking.
Increasing the Cost of Model Extraction with Calibrated Proof of Work
Jan 23, 2022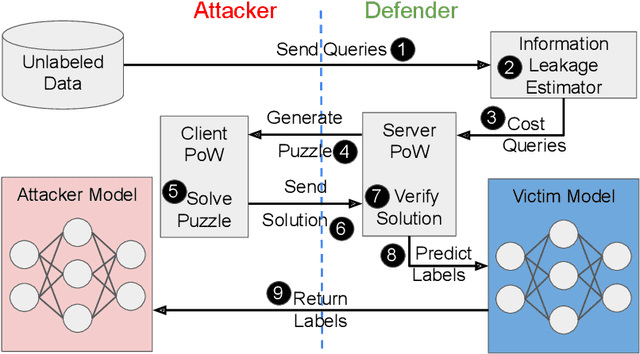

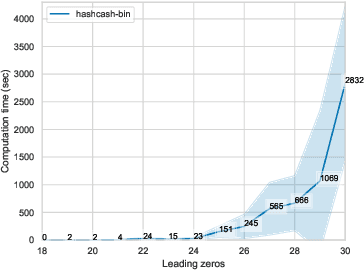
In model extraction attacks, adversaries can steal a machine learning model exposed via a public API by repeatedly querying it and adjusting their own model based on obtained predictions. To prevent model stealing, existing defenses focus on detecting malicious queries, truncating, or distorting outputs, thus necessarily introducing a tradeoff between robustness and model utility for legitimate users. Instead, we propose to impede model extraction by requiring users to complete a proof-of-work before they can read the model's predictions. This deters attackers by greatly increasing (even up to 100x) the computational effort needed to leverage query access for model extraction. Since we calibrate the effort required to complete the proof-of-work to each query, this only introduces a slight overhead for regular users (up to 2x). To achieve this, our calibration applies tools from differential privacy to measure the information revealed by a query. Our method requires no modification of the victim model and can be applied by machine learning practitioners to guard their publicly exposed models against being easily stolen.
When the Curious Abandon Honesty: Federated Learning Is Not Private
Dec 06, 2021

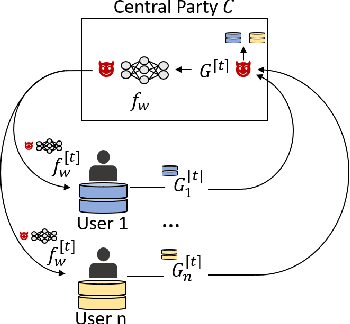
In federated learning (FL), data does not leave personal devices when they are jointly training a machine learning model. Instead, these devices share gradients with a central party (e.g., a company). Because data never "leaves" personal devices, FL is presented as privacy-preserving. Yet, recently it was shown that this protection is but a thin facade, as even a passive attacker observing gradients can reconstruct data of individual users. In this paper, we argue that prior work still largely underestimates the vulnerability of FL. This is because prior efforts exclusively consider passive attackers that are honest-but-curious. Instead, we introduce an active and dishonest attacker acting as the central party, who is able to modify the shared model's weights before users compute model gradients. We call the modified weights "trap weights". Our active attacker is able to recover user data perfectly and at near zero costs: the attack requires no complex optimization objectives. Instead, it exploits inherent data leakage from model gradients and amplifies this effect by maliciously altering the weights of the shared model. These specificities enable our attack to scale to models trained with large mini-batches of data. Where attackers from prior work require hours to recover a single data point, our method needs milliseconds to capture the full mini-batch of data from both fully-connected and convolutional deep neural networks. Finally, we consider mitigations. We observe that current implementations of differential privacy (DP) in FL are flawed, as they explicitly trust the central party with the crucial task of adding DP noise, and thus provide no protection against a malicious central party. We also consider other defenses and explain why they are similarly inadequate. A significant redesign of FL is required for it to provide any meaningful form of data privacy to users.
On the Necessity of Auditable Algorithmic Definitions for Machine Unlearning
Oct 22, 2021

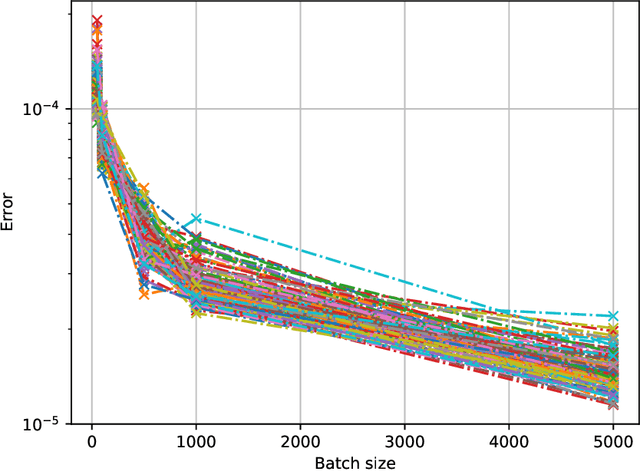
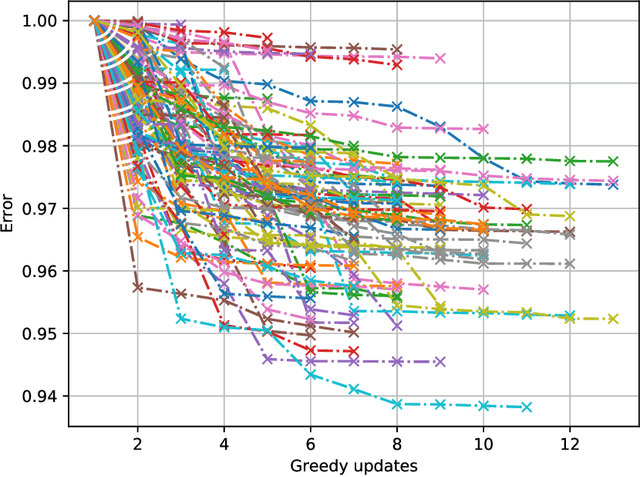
Machine unlearning, i.e. having a model forget about some of its training data, has become increasingly more important as privacy legislation promotes variants of the right-to-be-forgotten. In the context of deep learning, approaches for machine unlearning are broadly categorized into two classes: exact unlearning methods, where an entity has formally removed the data point's impact on the model by retraining the model from scratch, and approximate unlearning, where an entity approximates the model parameters one would obtain by exact unlearning to save on compute costs. In this paper we first show that the definition that underlies approximate unlearning, which seeks to prove the approximately unlearned model is close to an exactly retrained model, is incorrect because one can obtain the same model using different datasets. Thus one could unlearn without modifying the model at all. We then turn to exact unlearning approaches and ask how to verify their claims of unlearning. Our results show that even for a given training trajectory one cannot formally prove the absence of certain data points used during training. We thus conclude that unlearning is only well-defined at the algorithmic level, where an entity's only possible auditable claim to unlearning is that they used a particular algorithm designed to allow for external scrutiny during an audit.