 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeTowards Understanding Sharpness-Aware Minimization
Jun 13, 2022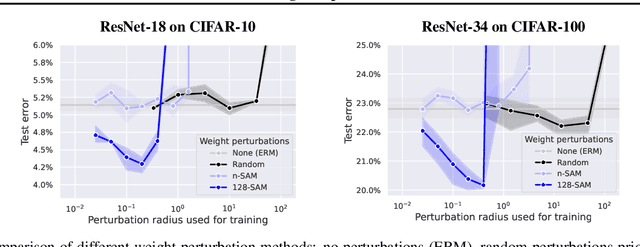
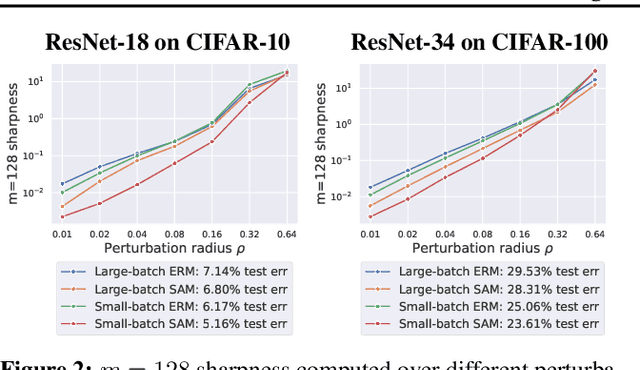
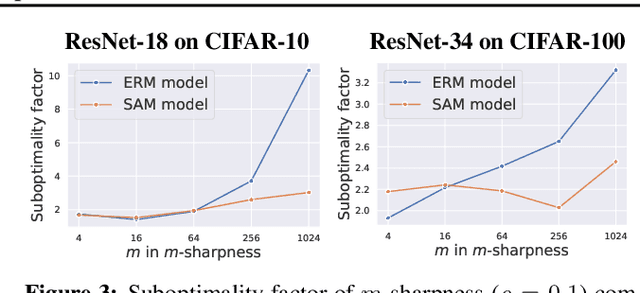
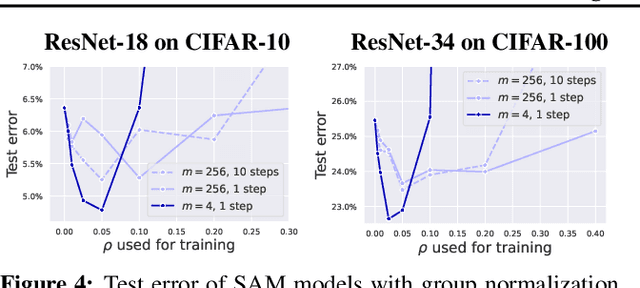
Sharpness-Aware Minimization (SAM) is a recent training method that relies on worst-case weight perturbations which significantly improves generalization in various settings. We argue that the existing justifications for the success of SAM which are based on a PAC-Bayes generalization bound and the idea of convergence to flat minima are incomplete. Moreover, there are no explanations for the success of using $m$-sharpness in SAM which has been shown as essential for generalization. To better understand this aspect of SAM, we theoretically analyze its implicit bias for diagonal linear networks. We prove that SAM always chooses a solution that enjoys better generalization properties than standard gradient descent for a certain class of problems, and this effect is amplified by using $m$-sharpness. We further study the properties of the implicit bias on non-linear networks empirically, where we show that fine-tuning a standard model with SAM can lead to significant generalization improvements. Finally, we provide convergence results of SAM for non-convex objectives when used with stochastic gradients. We illustrate these results empirically for deep networks and discuss their relation to the generalization behavior of SAM. The code of our experiments is available at https://github.com/tml-epfl/understanding-sam.
Gradient flow dynamics of shallow ReLU networks for square loss and orthogonal inputs
Jun 02, 2022
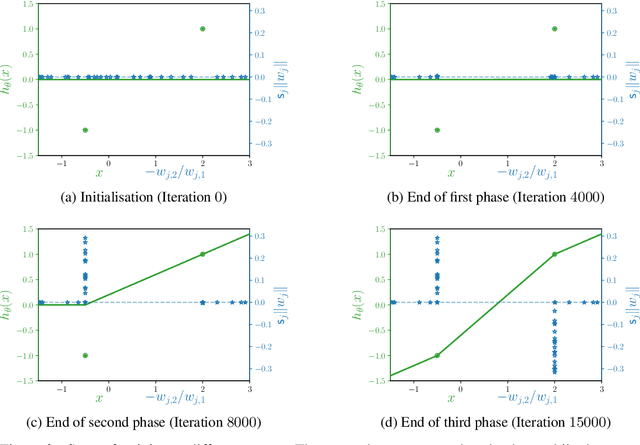
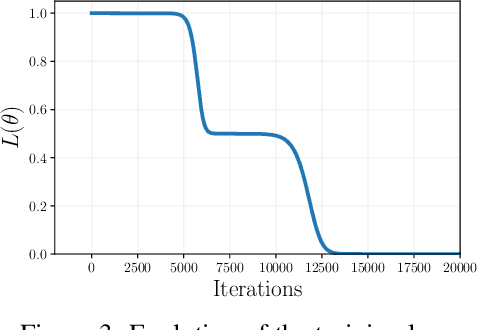
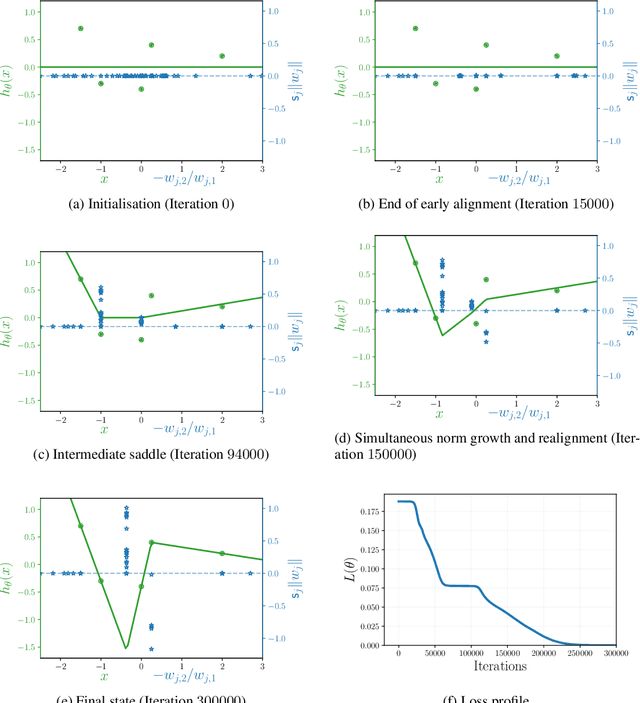
The training of neural networks by gradient descent methods is a cornerstone of the deep learning revolution. Yet, despite some recent progress, a complete theory explaining its success is still missing. This article presents, for orthogonal input vectors, a precise description of the gradient flow dynamics of training one-hidden layer ReLU neural networks for the mean squared error at small initialisation. In this setting, despite non-convexity, we show that the gradient flow converges to zero loss and characterise its implicit bias towards minimum variation norm. Furthermore, some interesting phenomena are highlighted: a quantitative description of the initial alignment phenomenon and a proof that the process follows a specific saddle to saddle dynamics.
Accelerated SGD for Non-Strongly-Convex Least Squares
Mar 03, 2022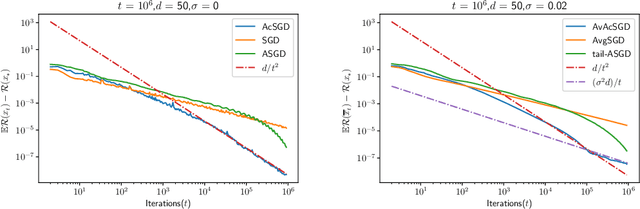
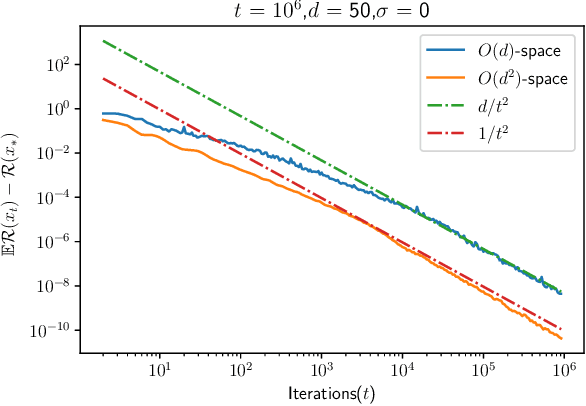
We consider stochastic approximation for the least squares regression problem in the non-strongly convex setting. We present the first practical algorithm that achieves the optimal prediction error rates in terms of dependence on the noise of the problem, as $O(d/t)$ while accelerating the forgetting of the initial conditions to $O(d/t^2)$. Our new algorithm is based on a simple modification of the accelerated gradient descent. We provide convergence results for both the averaged and the last iterate of the algorithm. In order to describe the tightness of these new bounds, we present a matching lower bound in the noiseless setting and thus show the optimality of our algorithm.
ARIA: Adversarially Robust Image Attribution for Content Provenance
Feb 25, 2022
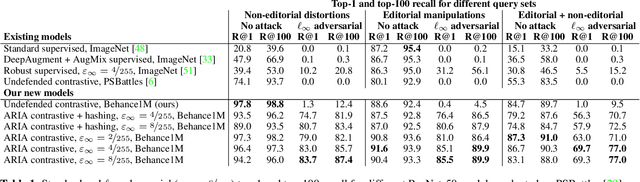

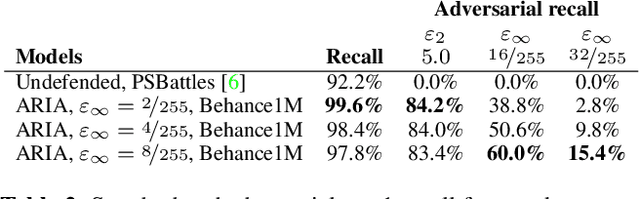
Image attribution -- matching an image back to a trusted source -- is an emerging tool in the fight against online misinformation. Deep visual fingerprinting models have recently been explored for this purpose. However, they are not robust to tiny input perturbations known as adversarial examples. First we illustrate how to generate valid adversarial images that can easily cause incorrect image attribution. Then we describe an approach to prevent imperceptible adversarial attacks on deep visual fingerprinting models, via robust contrastive learning. The proposed training procedure leverages training on $\ell_\infty$-bounded adversarial examples, it is conceptually simple and incurs only a small computational overhead. The resulting models are substantially more robust, are accurate even on unperturbed images, and perform well even over a database with millions of images. In particular, we achieve 91.6% standard and 85.1% adversarial recall under $\ell_\infty$-bounded perturbations on manipulated images compared to 80.1% and 0.0% from prior work. We also show that robustness generalizes to other types of imperceptible perturbations unseen during training. Finally, we show how to train an adversarially robust image comparator model for detecting editorial changes in matched images.
Trace norm regularization for multi-task learning with scarce data
Feb 14, 2022
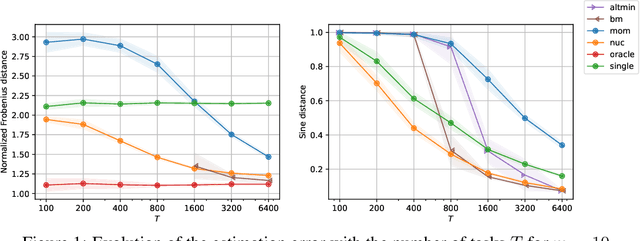
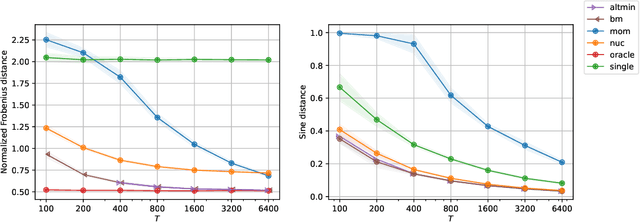
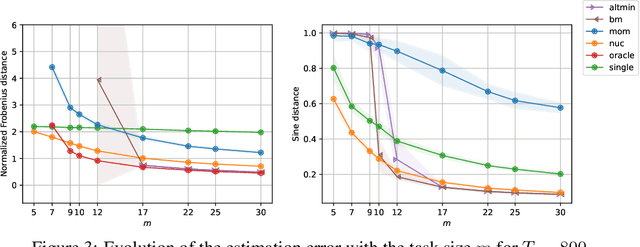
Multi-task learning leverages structural similarities between multiple tasks to learn despite very few samples. Motivated by the recent success of neural networks applied to data-scarce tasks, we consider a linear low-dimensional shared representation model. Despite an extensive literature, existing theoretical results either guarantee weak estimation rates or require a large number of samples per task. This work provides the first estimation error bound for the trace norm regularized estimator when the number of samples per task is small. The advantages of trace norm regularization for learning data-scarce tasks extend to meta-learning and are confirmed empirically on synthetic datasets.
Linear Speedup in Personalized Collaborative Learning
Nov 10, 2021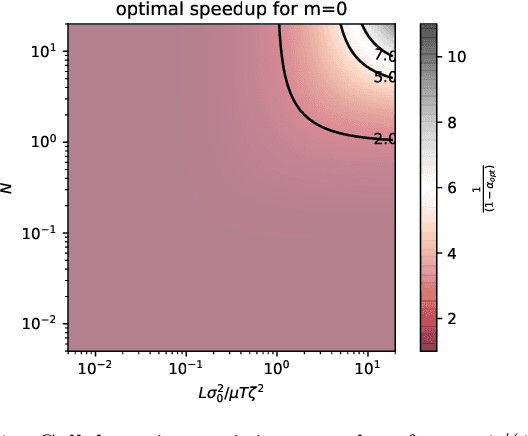
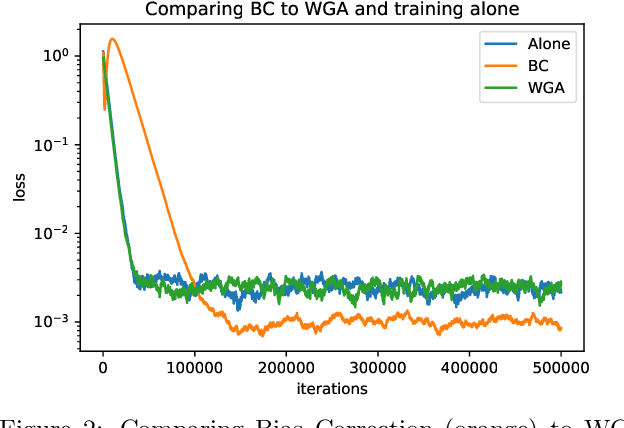
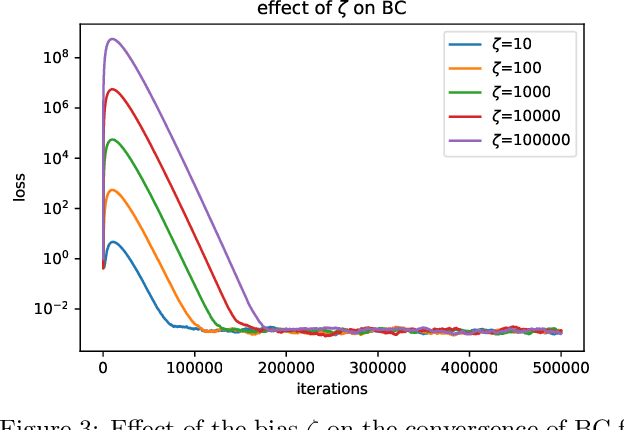
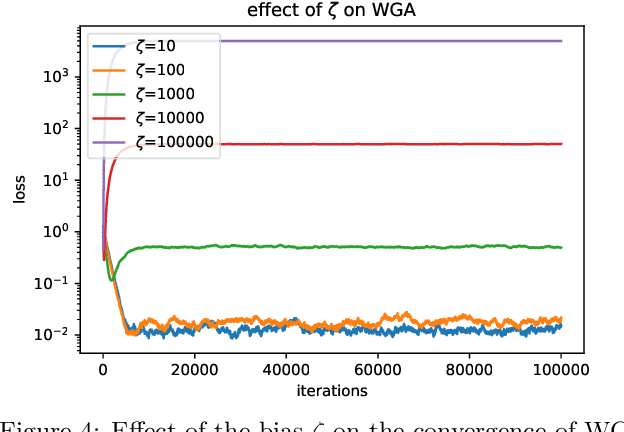
Personalization in federated learning can improve the accuracy of a model for a user by trading off the model's bias (introduced by using data from other users who are potentially different) against its variance (due to the limited amount of data on any single user). In order to develop training algorithms that optimally balance this trade-off, it is necessary to extend our theoretical foundations. In this work, we formalize the personalized collaborative learning problem as stochastic optimization of a user's objective $f_0(x)$ while given access to $N$ related but different objectives of other users $\{f_1(x), \dots, f_N(x)\}$. We give convergence guarantees for two algorithms in this setting -- a popular personalization method known as \emph{weighted gradient averaging}, and a novel \emph{bias correction} method -- and explore conditions under which we can optimally trade-off their bias for a reduction in variance and achieve linear speedup w.r.t.\ the number of users $N$. Further, we also empirically study their performance confirming our theoretical insights.
Implicit Bias of SGD for Diagonal Linear Networks: a Provable Benefit of Stochasticity
Jun 17, 2021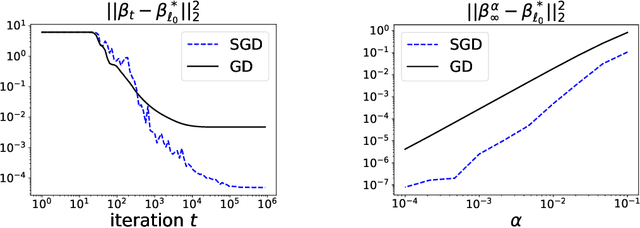
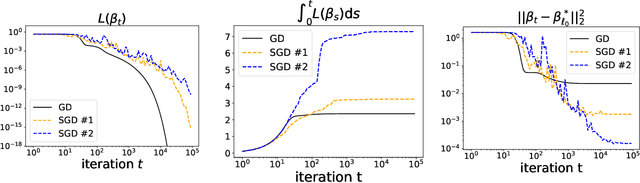
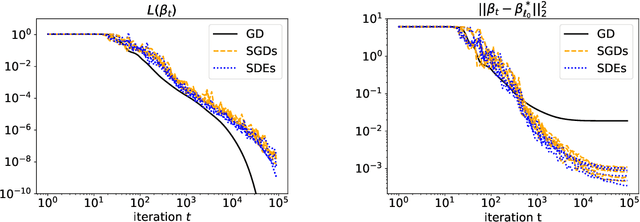
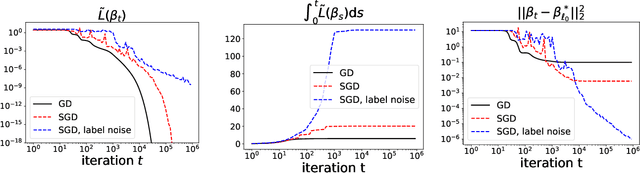
Understanding the implicit bias of training algorithms is of crucial importance in order to explain the success of overparametrised neural networks. In this paper, we study the dynamics of stochastic gradient descent over diagonal linear networks through its continuous time version, namely stochastic gradient flow. We explicitly characterise the solution chosen by the stochastic flow and prove that it always enjoys better generalisation properties than that of gradient flow. Quite surprisingly, we show that the convergence speed of the training loss controls the magnitude of the biasing effect: the slower the convergence, the better the bias. To fully complete our analysis, we provide convergence guarantees for the dynamics. We also give experimental results which support our theoretical claims. Our findings highlight the fact that structured noise can induce better generalisation and they help explain the greater performances observed in practice of stochastic gradient descent over gradient descent.
A Continuized View on Nesterov Acceleration for Stochastic Gradient Descent and Randomized Gossip
Jun 10, 2021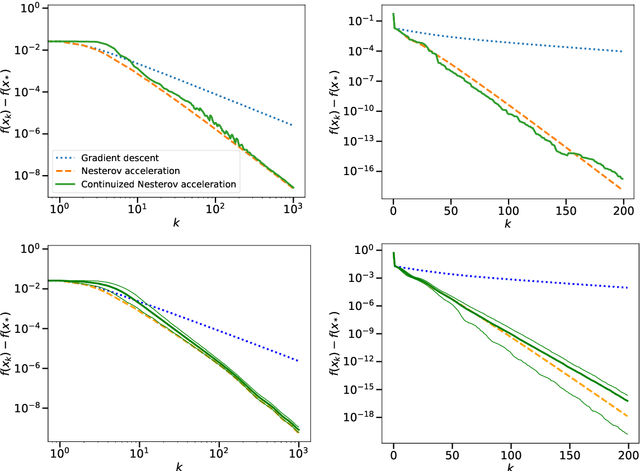
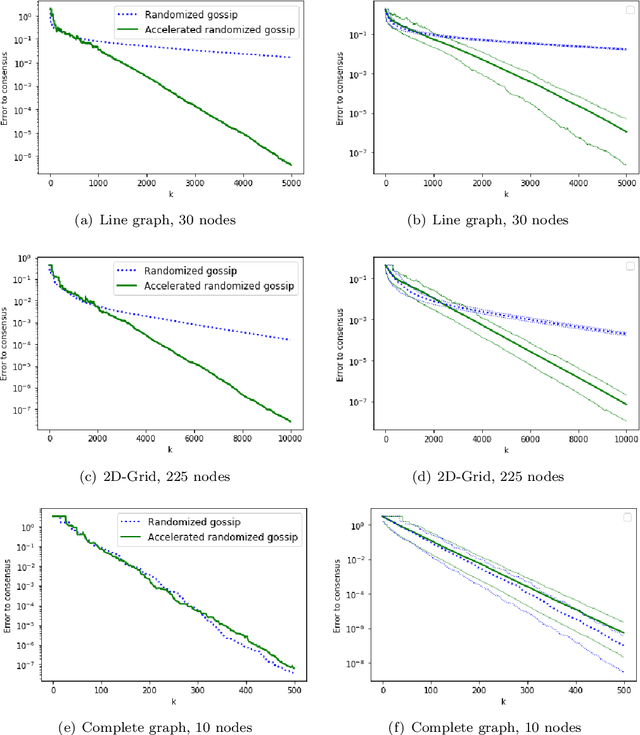
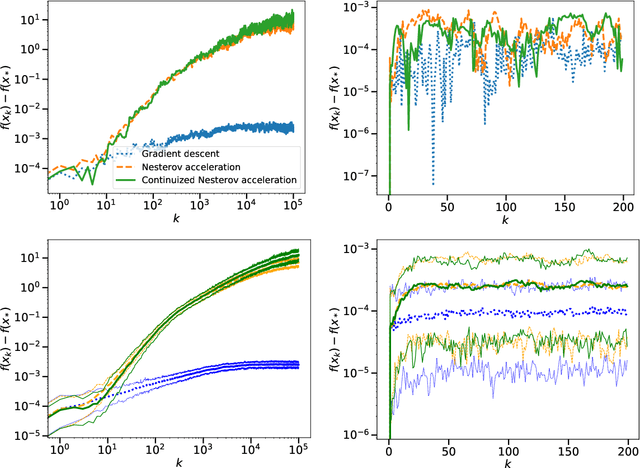
We introduce the continuized Nesterov acceleration, a close variant of Nesterov acceleration whose variables are indexed by a continuous time parameter. The two variables continuously mix following a linear ordinary differential equation and take gradient steps at random times. This continuized variant benefits from the best of the continuous and the discrete frameworks: as a continuous process, one can use differential calculus to analyze convergence and obtain analytical expressions for the parameters; and a discretization of the continuized process can be computed exactly with convergence rates similar to those of Nesterov original acceleration. We show that the discretization has the same structure as Nesterov acceleration, but with random parameters. We provide continuized Nesterov acceleration under deterministic as well as stochastic gradients, with either additive or multiplicative noise. Finally, using our continuized framework and expressing the gossip averaging problem as the stochastic minimization of a certain energy function, we provide the first rigorous acceleration of asynchronous gossip algorithms.
On the effectiveness of adversarial training against common corruptions
Mar 03, 2021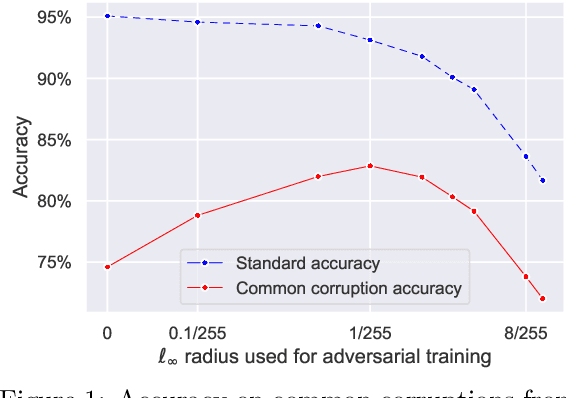

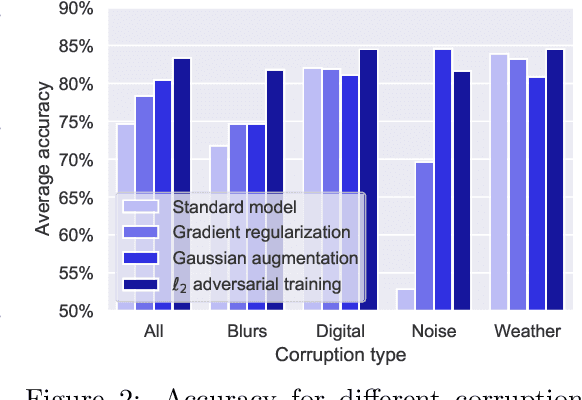

The literature on robustness towards common corruptions shows no consensus on whether adversarial training can improve the performance in this setting. First, we show that, when used with an appropriately selected perturbation radius, $\ell_p$ adversarial training can serve as a strong baseline against common corruptions. Then we explain why adversarial training performs better than data augmentation with simple Gaussian noise which has been observed to be a meaningful baseline on common corruptions. Related to this, we identify the $\sigma$-overfitting phenomenon when Gaussian augmentation overfits to a particular standard deviation used for training which has a significant detrimental effect on common corruption accuracy. We discuss how to alleviate this problem and then how to further enhance $\ell_p$ adversarial training by introducing an efficient relaxation of adversarial training with learned perceptual image patch similarity as the distance metric. Through experiments on CIFAR-10 and ImageNet-100, we show that our approach does not only improve the $\ell_p$ adversarial training baseline but also has cumulative gains with data augmentation methods such as AugMix, ANT, and SIN leading to state-of-the-art performance on common corruptions. The code of our experiments is publicly available at https://github.com/tml-epfl/adv-training-corruptions.
Last iterate convergence of SGD for Least-Squares in the Interpolation regime
Feb 05, 2021
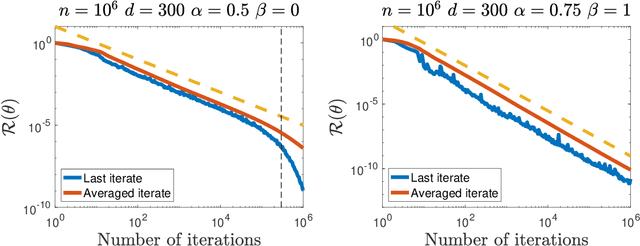


Motivated by the recent successes of neural networks that have the ability to fit the data perfectly and generalize well, we study the noiseless model in the fundamental least-squares setup. We assume that an optimum predictor fits perfectly inputs and outputs $\langle \theta_* , \phi(X) \rangle = Y$, where $\phi(X)$ stands for a possibly infinite dimensional non-linear feature map. To solve this problem, we consider the estimator given by the last iterate of stochastic gradient descent (SGD) with constant step-size. In this context, our contribution is two fold: (i) from a (stochastic) optimization perspective, we exhibit an archetypal problem where we can show explicitly the convergence of SGD final iterate for a non-strongly convex problem with constant step-size whereas usual results use some form of average and (ii) from a statistical perspective, we give explicit non-asymptotic convergence rates in the over-parameterized setting and leverage a fine-grained parameterization of the problem to exhibit polynomial rates that can be faster than $O(1/T)$. The link with reproducing kernel Hilbert spaces is established.