 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeHyperspectral pansharpening: a review
Apr 17, 2015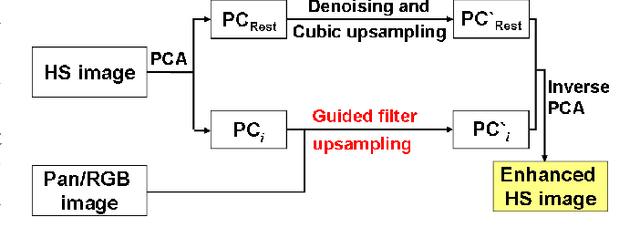
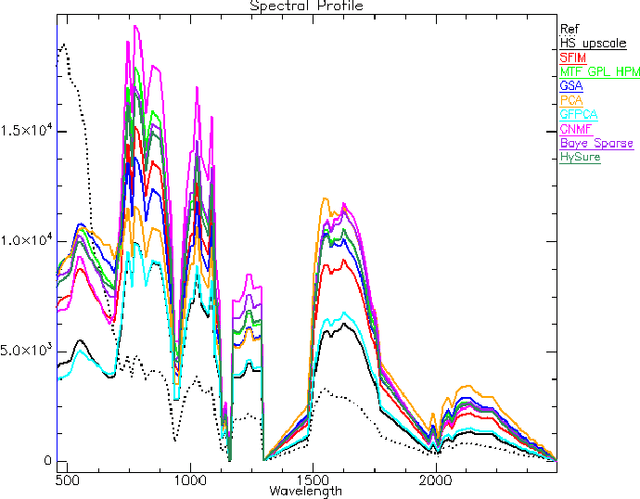
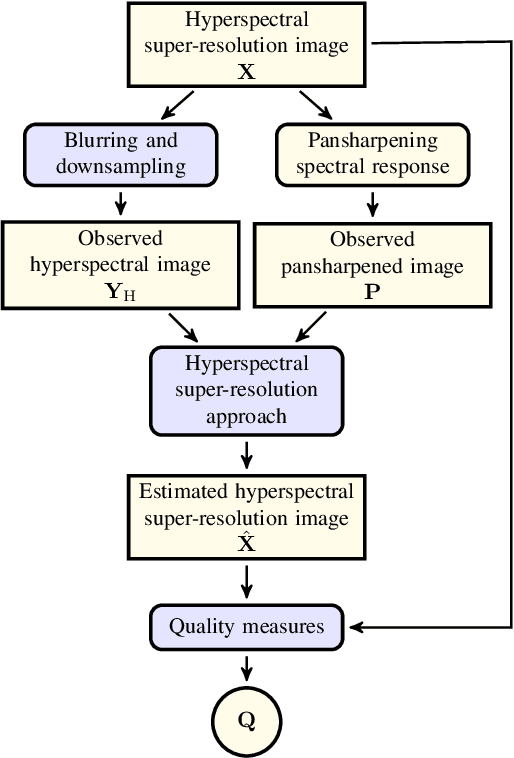
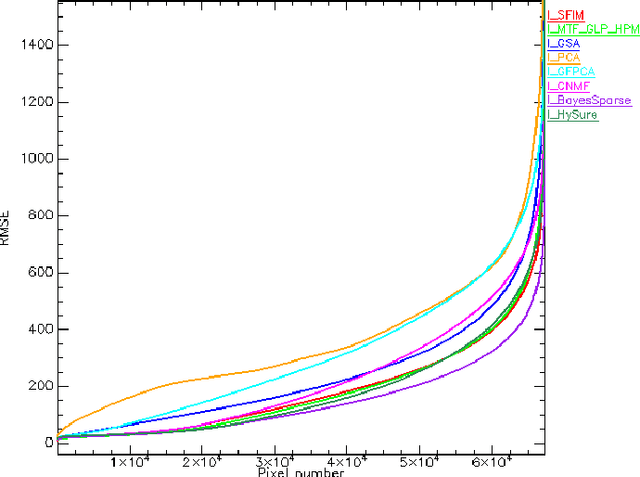
Pansharpening aims at fusing a panchromatic image with a multispectral one, to generate an image with the high spatial resolution of the former and the high spectral resolution of the latter. In the last decade, many algorithms have been presented in the literature for pansharpening using multispectral data. With the increasing availability of hyperspectral systems, these methods are now being adapted to hyperspectral images. In this work, we compare new pansharpening techniques designed for hyperspectral data with some of the state of the art methods for multispectral pansharpening, which have been adapted for hyperspectral data. Eleven methods from different classes (component substitution, multiresolution analysis, hybrid, Bayesian and matrix factorization) are analyzed. These methods are applied to three datasets and their effectiveness and robustness are evaluated with widely used performance indicators. In addition, all the pansharpening techniques considered in this paper have been implemented in a MATLAB toolbox that is made available to the community.
Bayesian estimation of the multifractality parameter for image texture using a Whittle approximation
Apr 09, 2015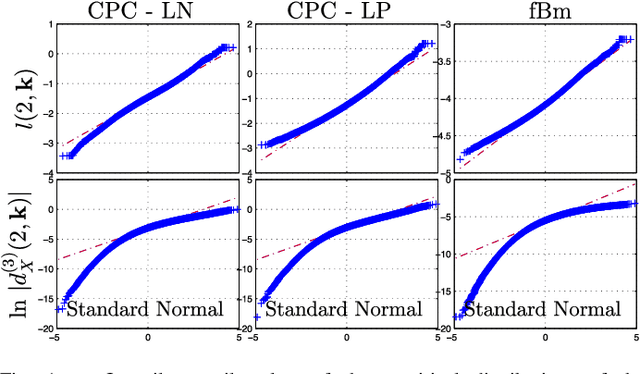
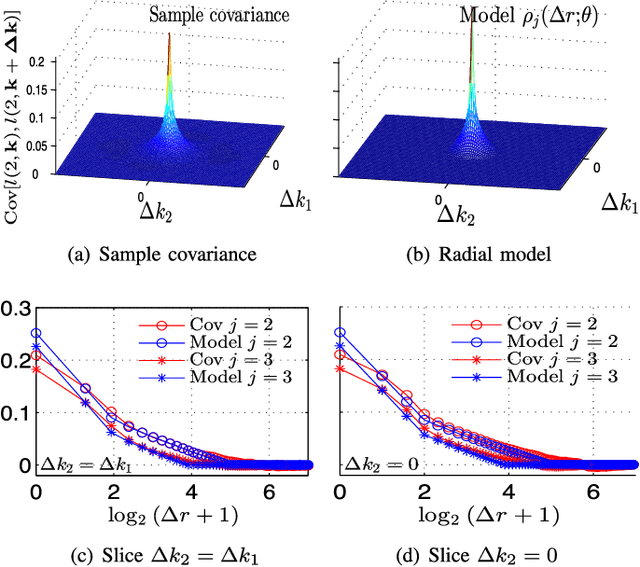
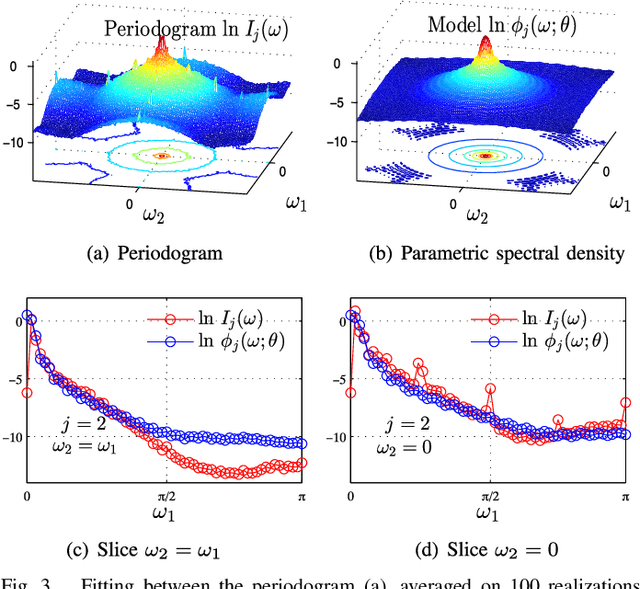
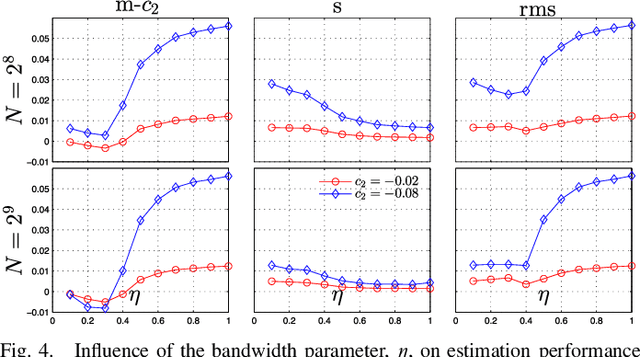
Texture characterization is a central element in many image processing applications. Multifractal analysis is a useful signal and image processing tool, yet, the accurate estimation of multifractal parameters for image texture remains a challenge. This is due in the main to the fact that current estimation procedures consist of performing linear regressions across frequency scales of the two-dimensional (2D) dyadic wavelet transform, for which only a few such scales are computable for images. The strongly non-Gaussian nature of multifractal processes, combined with their complicated dependence structure, makes it difficult to develop suitable models for parameter estimation. Here, we propose a Bayesian procedure that addresses the difficulties in the estimation of the multifractality parameter. The originality of the procedure is threefold: The construction of a generic semi-parametric statistical model for the logarithm of wavelet leaders; the formulation of Bayesian estimators that are associated with this model and the set of parameter values admitted by multifractal theory; the exploitation of a suitable Whittle approximation within the Bayesian model which enables the otherwise infeasible evaluation of the posterior distribution associated with the model. Performance is assessed numerically for several 2D multifractal processes, for several image sizes and a large range of process parameters. The procedure yields significant benefits over current benchmark estimators in terms of estimation performance and ability to discriminate between the two most commonly used classes of multifractal process models. The gains in performance are particularly pronounced for small image sizes, notably enabling for the first time the analysis of image patches as small as 64x64 pixels.
Fast Fusion of Multi-Band Images Based on Solving a Sylvester Equation
Feb 10, 2015

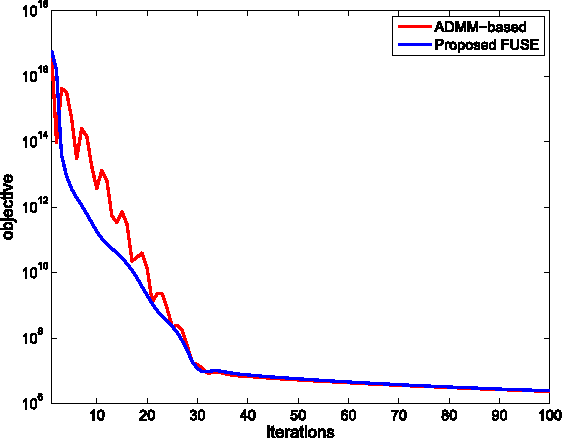

This paper proposes a fast multi-band image fusion algorithm, which combines a high-spatial low-spectral resolution image and a low-spatial high-spectral resolution image. The well admitted forward model is explored to form the likelihoods of the observations. Maximizing the likelihoods leads to solving a Sylvester equation. By exploiting the properties of the circulant and downsampling matrices associated with the fusion problem, a closed-form solution for the corresponding Sylvester equation is obtained explicitly, getting rid of any iterative update step. Coupled with the alternating direction method of multipliers and the block coordinate descent method, the proposed algorithm can be easily generalized to incorporate prior information for the fusion problem, allowing a Bayesian estimator. Simulation results show that the proposed algorithm achieves the same performance as existing algorithms with the advantage of significantly decreasing the computational complexity of these algorithms.
Hyperspectral and Multispectral Image Fusion based on a Sparse Representation
Sep 19, 2014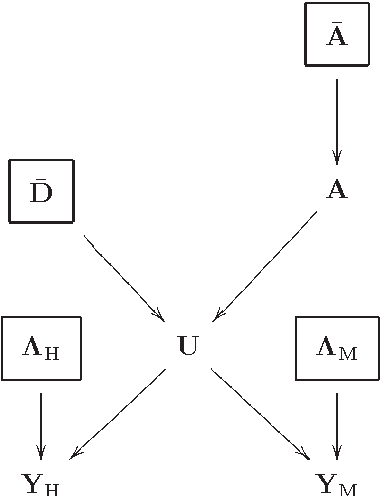


This paper presents a variational based approach to fusing hyperspectral and multispectral images. The fusion process is formulated as an inverse problem whose solution is the target image assumed to live in a much lower dimensional subspace. A sparse regularization term is carefully designed, relying on a decomposition of the scene on a set of dictionaries. The dictionary atoms and the corresponding supports of active coding coefficients are learned from the observed images. Then, conditionally on these dictionaries and supports, the fusion problem is solved via alternating optimization with respect to the target image (using the alternating direction method of multipliers) and the coding coefficients. Simulation results demonstrate the efficiency of the proposed algorithm when compared with the state-of-the-art fusion methods.
Bayesian Fusion of Multi-Band Images
Aug 26, 2014

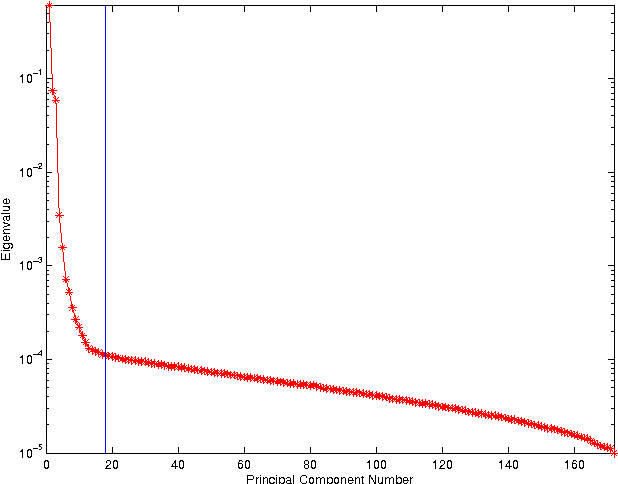

In this paper, a Bayesian fusion technique for remotely sensed multi-band images is presented. The observed images are related to the high spectral and high spatial resolution image to be recovered through physical degradations, e.g., spatial and spectral blurring and/or subsampling defined by the sensor characteristics. The fusion problem is formulated within a Bayesian estimation framework. An appropriate prior distribution exploiting geometrical consideration is introduced. To compute the Bayesian estimator of the scene of interest from its posterior distribution, a Markov chain Monte Carlo algorithm is designed to generate samples asymptotically distributed according to the target distribution. To efficiently sample from this high-dimension distribution, a Hamiltonian Monte Carlo step is introduced in the Gibbs sampling strategy. The efficiency of the proposed fusion method is evaluated with respect to several state-of-the-art fusion techniques. In particular, low spatial resolution hyperspectral and multispectral images are fused to produce a high spatial resolution hyperspectral image.
Nonlinear hyperspectral unmixing with robust nonnegative matrix factorization
Mar 06, 2014
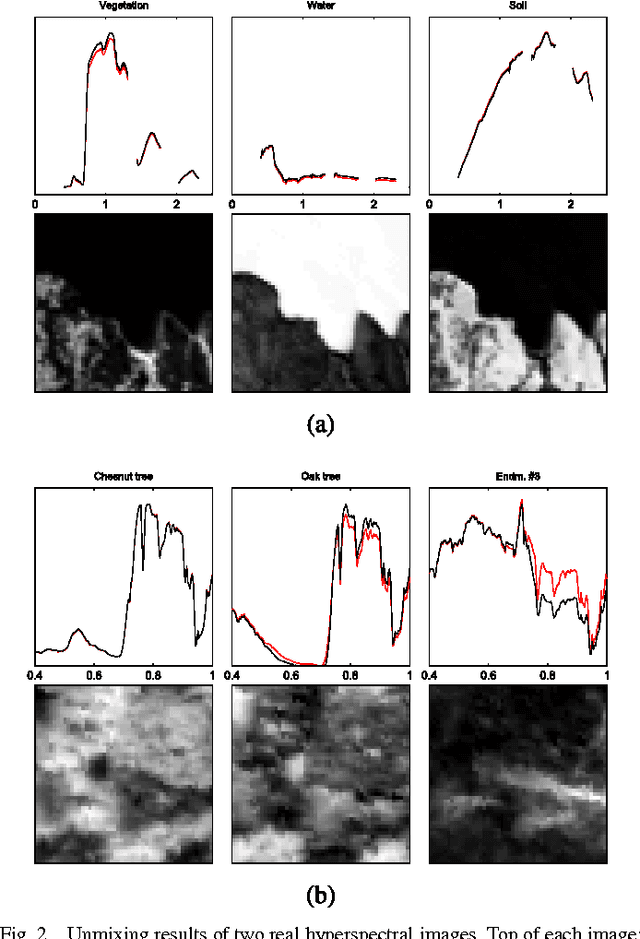

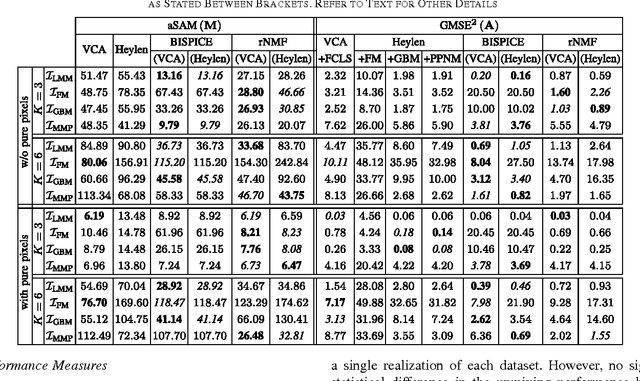
This paper introduces a robust mixing model to describe hyperspectral data resulting from the mixture of several pure spectral signatures. This new model not only generalizes the commonly used linear mixing model, but also allows for possible nonlinear effects to be easily handled, relying on mild assumptions regarding these nonlinearities. The standard nonnegativity and sum-to-one constraints inherent to spectral unmixing are coupled with a group-sparse constraint imposed on the nonlinearity component. This results in a new form of robust nonnegative matrix factorization. The data fidelity term is expressed as a beta-divergence, a continuous family of dissimilarity measures that takes the squared Euclidean distance and the generalized Kullback-Leibler divergence as special cases. The penalized objective is minimized with a block-coordinate descent that involves majorization-minimization updates. Simulation results obtained on synthetic and real data show that the proposed strategy competes with state-of-the-art linear and nonlinear unmixing methods.
Joint Bayesian estimation of close subspaces from noisy measurements
Oct 01, 2013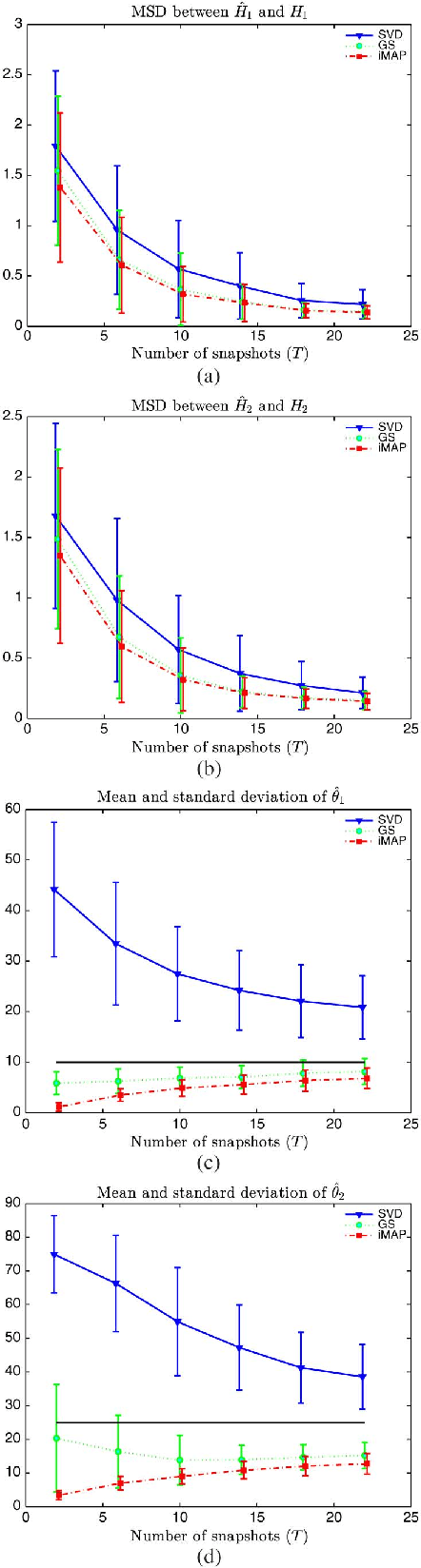
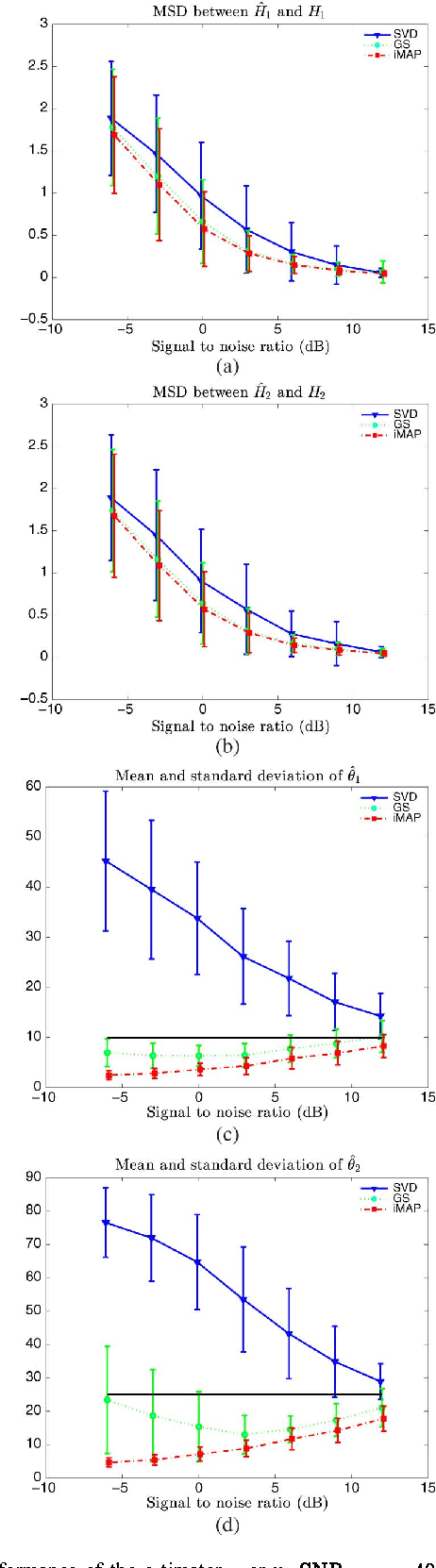
In this letter, we consider two sets of observations defined as subspace signals embedded in noise and we wish to analyze the distance between these two subspaces. The latter entails evaluating the angles between the subspaces, an issue reminiscent of the well-known Procrustes problem. A Bayesian approach is investigated where the subspaces of interest are considered as random with a joint prior distribution (namely a Bingham distribution), which allows the closeness of the two subspaces to be adjusted. Within this framework, the minimum mean-square distance estimator of both subspaces is formulated and implemented via a Gibbs sampler. A simpler scheme based on alternative maximum a posteriori estimation is also presented. The new schemes are shown to provide more accurate estimates of the angles between the subspaces, compared to singular value decomposition based independent estimation of the two subspaces.
Nonlinear unmixing of hyperspectral images: models and algorithms
Jul 18, 2013



When considering the problem of unmixing hyperspectral images, most of the literature in the geoscience and image processing areas relies on the widely used linear mixing model (LMM). However, the LMM may be not valid and other nonlinear models need to be considered, for instance, when there are multi-scattering effects or intimate interactions. Consequently, over the last few years, several significant contributions have been proposed to overcome the limitations inherent in the LMM. In this paper, we present an overview of recent advances in nonlinear unmixing modeling.
Variational Semi-blind Sparse Deconvolution with Orthogonal Kernel Bases and its Application to MRFM
Mar 15, 2013

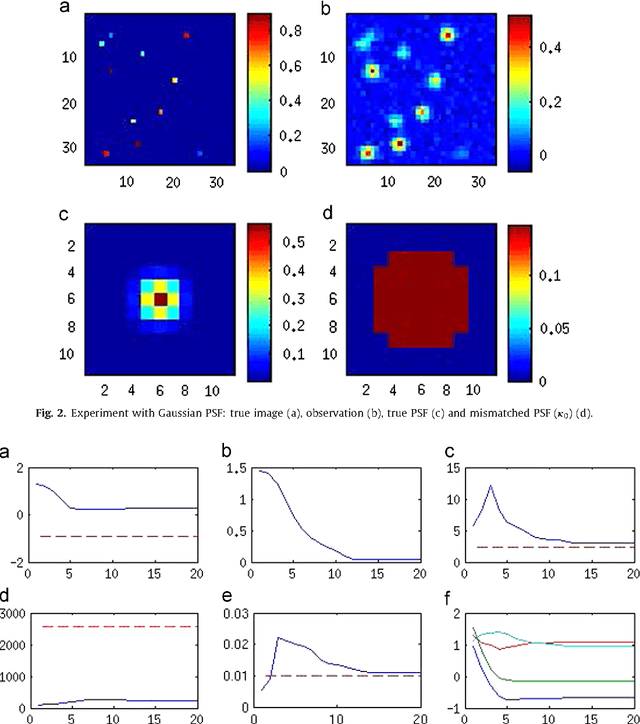
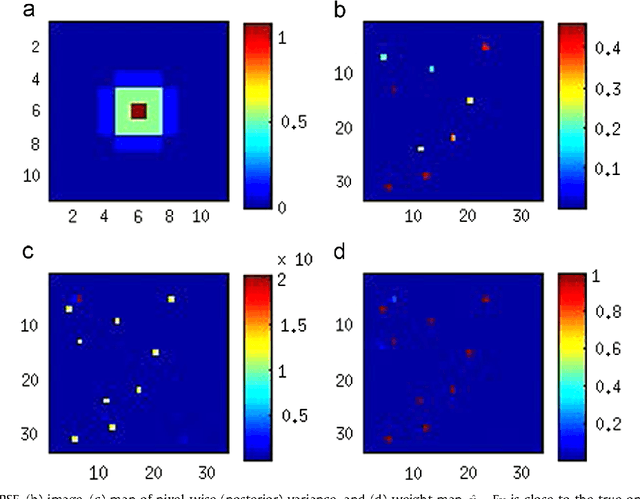
We present a variational Bayesian method of joint image reconstruction and point spread function (PSF) estimation when the PSF of the imaging device is only partially known. To solve this semi-blind deconvolution problem, prior distributions are specified for the PSF and the 3D image. Joint image reconstruction and PSF estimation is then performed within a Bayesian framework, using a variational algorithm to estimate the posterior distribution. The image prior distribution imposes an explicit atomic measure that corresponds to image sparsity. Importantly, the proposed Bayesian deconvolution algorithm does not require hand tuning. Simulation results clearly demonstrate that the semi-blind deconvolution algorithm compares favorably with previous Markov chain Monte Carlo (MCMC) version of myopic sparse reconstruction. It significantly outperforms mismatched non-blind algorithms that rely on the assumption of the perfect knowledge of the PSF. The algorithm is illustrated on real data from magnetic resonance force microscopy (MRFM).
Nonlinear spectral unmixing of hyperspectral images using Gaussian processes
Jul 23, 2012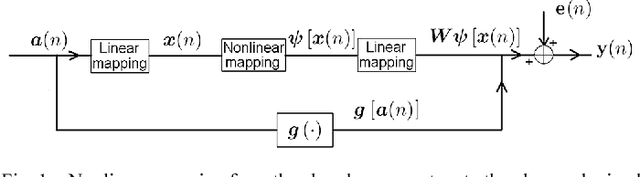
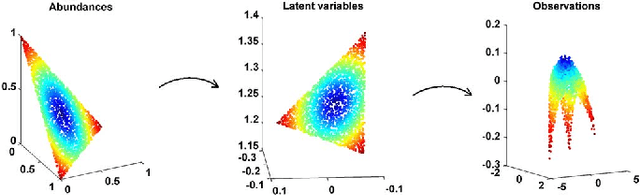
This paper presents an unsupervised algorithm for nonlinear unmixing of hyperspectral images. The proposed model assumes that the pixel reflectances result from a nonlinear function of the abundance vectors associated with the pure spectral components. We assume that the spectral signatures of the pure components and the nonlinear function are unknown. The first step of the proposed method consists of the Bayesian estimation of the abundance vectors for all the image pixels and the nonlinear function relating the abundance vectors to the observations. The endmembers are subsequently estimated using Gaussian process regression. The performance of the unmixing strategy is evaluated with simulations conducted on synthetic and real data.