 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeFlowMAC: Conditional Flow Matching for Audio Coding at Low Bit Rates
Sep 26, 2024This paper introduces FlowMAC, a novel neural audio codec for high-quality general audio compression at low bit rates based on conditional flow matching (CFM). FlowMAC jointly learns a mel spectrogram encoder, quantizer and decoder. At inference time the decoder integrates a continuous normalizing flow via an ODE solver to generate a high-quality mel spectrogram. This is the first time that a CFM-based approach is applied to general audio coding, enabling a scalable, simple and memory efficient training. Our subjective evaluations show that FlowMAC at 3 kbps achieves similar quality as state-of-the-art GAN-based and DDPM-based neural audio codecs at double the bit rate. Moreover, FlowMAC offers a tunable inference pipeline, which permits to trade off complexity and quality. This enables real-time coding on CPU, while maintaining high perceptual quality.
Inference-Adaptive Neural Steering for Real-Time Area-Based Sound Source Separation
Aug 23, 2024



We propose a novel Neural Steering technique that adapts the target area of a spatial-aware multi-microphone sound source separation algorithm during inference without the necessity of retraining the deep neural network (DNN). To achieve this, we first train a DNN aiming to retain speech within a target region, defined by an angular span, while suppressing sound sources stemming from other directions. Afterward, a phase shift is applied to the microphone signals, allowing us to shift the center of the target area during inference at negligible additional cost in computational complexity. Further, we show that the proposed approach performs well in a wide variety of acoustic scenarios, including several speakers inside and outside the target area and additional noise. More precisely, the proposed approach performs on par with DNNs trained explicitly for the steered target area in terms of DNSMOS and SI-SDR.
Efficient Area-based and Speaker-Agnostic Source Separation
Aug 19, 2024



This paper introduces an area-based source separation method designed for virtual meeting scenarios. The aim is to preserve speech signals from an unspecified number of sources within a defined spatial area in front of a linear microphone array, while suppressing all other sounds. Therefore, we employ an efficient neural network architecture adapted for multi-channel input to encompass the predefined target area. To evaluate the approach, training data and specific test scenarios including multiple target and interfering speakers, as well as background noise are simulated. All models are rated according to DNSMOS and scale-invariant signal-to-distortion ratio. Our experiments show that the proposed method separates speech from multiple speakers within the target area well, besides being of very low complexity, intended for real-time processing. In addition, a power reduction heatmap is used to demonstrate the networks' ability to identify sources located within the target area. We put our approach in context with a well-established baseline for speaker-speaker separation and discuss its strengths and challenges.
SEFGAN: Harvesting the Power of Normalizing Flows and GANs for Efficient High-Quality Speech Enhancement
Dec 04, 2023



This paper proposes SEFGAN, a Deep Neural Network (DNN) combining maximum likelihood training and Generative Adversarial Networks (GANs) for efficient speech enhancement (SE). For this, a DNN is trained to synthesize the enhanced speech conditioned on noisy speech using a Normalizing Flow (NF) as generator in a GAN framework. While the combination of likelihood models and GANs is not trivial, SEFGAN demonstrates that a hybrid adversarial and maximum likelihood training approach enables the model to maintain high quality audio generation and log-likelihood estimation. Our experiments indicate that this approach strongly outperforms the baseline NF-based model without introducing additional complexity to the enhancement network. A comparison using computational metrics and a listening experiment reveals that SEFGAN is competitive with other state-of-the-art models.
Predicting Preferred Dialogue-to-Background Loudness Difference in Dialogue-Separated Audio
May 31, 2023



Dialogue Enhancement (DE) enables the rebalancing of dialogue and background sounds to fit personal preferences and needs in the context of broadcast audio. When individual audio stems are unavailable from production, Dialogue Separation (DS) can be applied to the final audio mixture to obtain estimates of these stems. This work focuses on Preferred Loudness Differences (PLDs) between dialogue and background sounds. While previous studies determined the PLD through a listening test employing original stems from production, stems estimated by DS are used in the present study. In addition, a larger variety of signal classes is considered. PLDs vary substantially across individuals (average interquartile range: 5.7 LU). Despite this variability, PLDs are found to be highly dependent on the signal type under consideration, and it is shown that median PLDs can be predicted using objective intelligibility metrics. Two existing baseline prediction methods - intended for use with original stems - displayed a Mean Absolute Error (MAE) of 7.5 LU and 5 LU, respectively. A modified baseline (MAE: 3.2 LU) and an alternative approach (MAE: 2.5 LU) are proposed. Results support the viability of processing final broadcast mixtures with DS and offering an alternative remixing that accounts for median PLDs.
A Hands-on Comparison of DNNs for Dialog Separation Using Transfer Learning from Music Source Separation
Jun 22, 2021
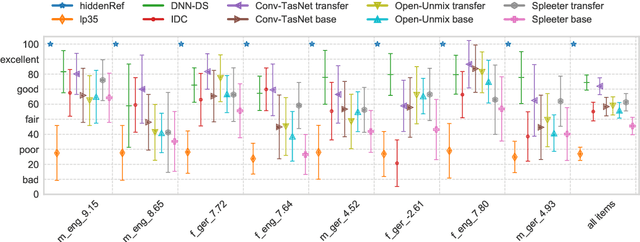
This paper describes a hands-on comparison on using state-of-the-art music source separation deep neural networks (DNNs) before and after task-specific fine-tuning for separating speech content from non-speech content in broadcast audio (i.e., dialog separation). The music separation models are selected as they share the number of channels (2) and sampling rate (44.1 kHz or higher) with the considered broadcast content, and vocals separation in music is considered as a parallel for dialog separation in the target application domain. These similarities are assumed to enable transfer learning between the tasks. Three models pre-trained on music (Open-Unmix, Spleeter, and Conv-TasNet) are considered in the experiments, and fine-tuned with real broadcast data. The performance of the models is evaluated before and after fine-tuning with computational evaluation metrics (SI-SIRi, SI-SDRi, 2f-model), as well as with a listening test simulating an application where the non-speech signal is partially attenuated, e.g., for better speech intelligibility. The evaluations include two reference systems specifically developed for dialog separation. The results indicate that pre-trained music source separation models can be used for dialog separation to some degree, and that they benefit from the fine-tuning, reaching a performance close to task-specific solutions.
A Flow-Based Neural Network for Time Domain Speech Enhancement
Jun 16, 2021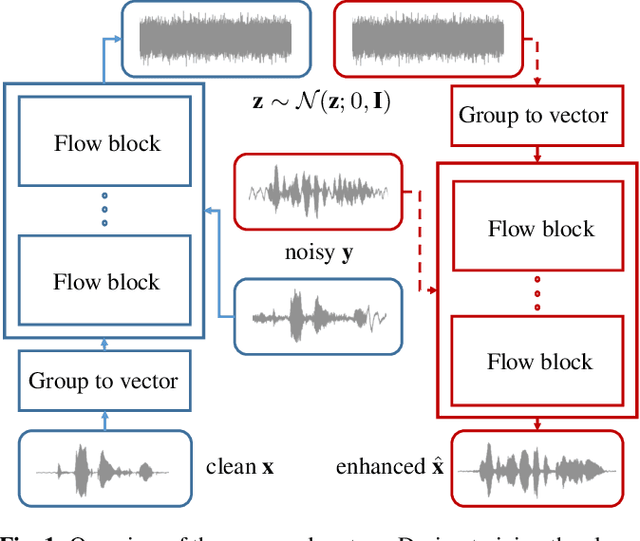
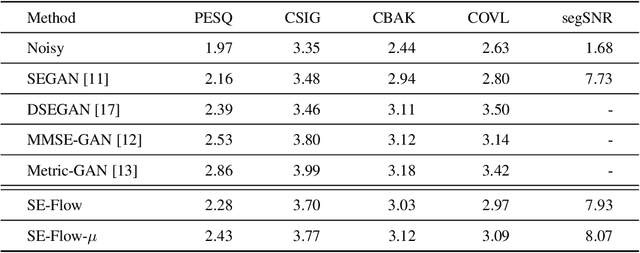
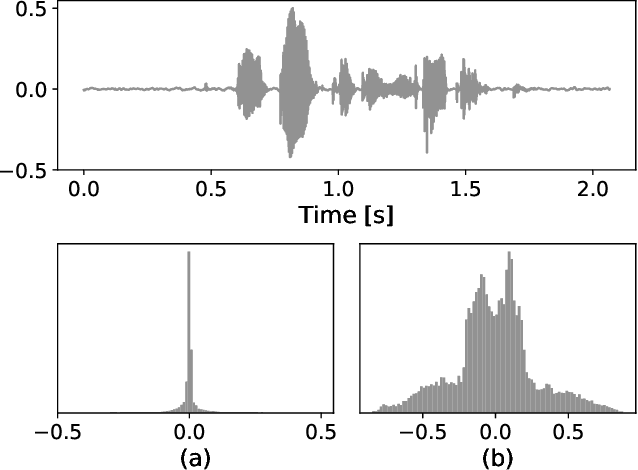
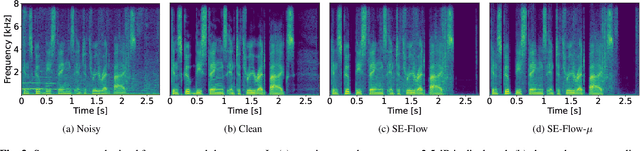
Speech enhancement involves the distinction of a target speech signal from an intrusive background. Although generative approaches using Variational Autoencoders or Generative Adversarial Networks (GANs) have increasingly been used in recent years, normalizing flow (NF) based systems are still scarse, despite their success in related fields. Thus, in this paper we propose a NF framework to directly model the enhancement process by density estimation of clean speech utterances conditioned on their noisy counterpart. The WaveGlow model from speech synthesis is adapted to enable direct enhancement of noisy utterances in time domain. In addition, we demonstrate that nonlinear input companding benefits the model performance by equalizing the distribution of input samples. Experimental evaluation on a publicly available dataset shows comparable results to current state-of-the-art GAN-based approaches, while surpassing the chosen baselines using objective evaluation metrics.