 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSEFGAN: Harvesting the Power of Normalizing Flows and GANs for Efficient High-Quality Speech Enhancement
Dec 04, 2023



This paper proposes SEFGAN, a Deep Neural Network (DNN) combining maximum likelihood training and Generative Adversarial Networks (GANs) for efficient speech enhancement (SE). For this, a DNN is trained to synthesize the enhanced speech conditioned on noisy speech using a Normalizing Flow (NF) as generator in a GAN framework. While the combination of likelihood models and GANs is not trivial, SEFGAN demonstrates that a hybrid adversarial and maximum likelihood training approach enables the model to maintain high quality audio generation and log-likelihood estimation. Our experiments indicate that this approach strongly outperforms the baseline NF-based model without introducing additional complexity to the enhancement network. A comparison using computational metrics and a listening experiment reveals that SEFGAN is competitive with other state-of-the-art models.
On The Effect Of Coding Artifacts On Acoustic Scene Classification
Dec 09, 2021
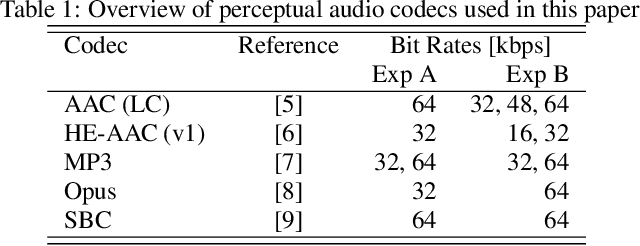
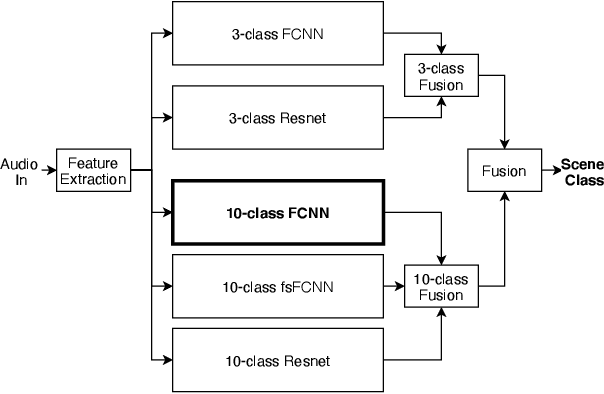
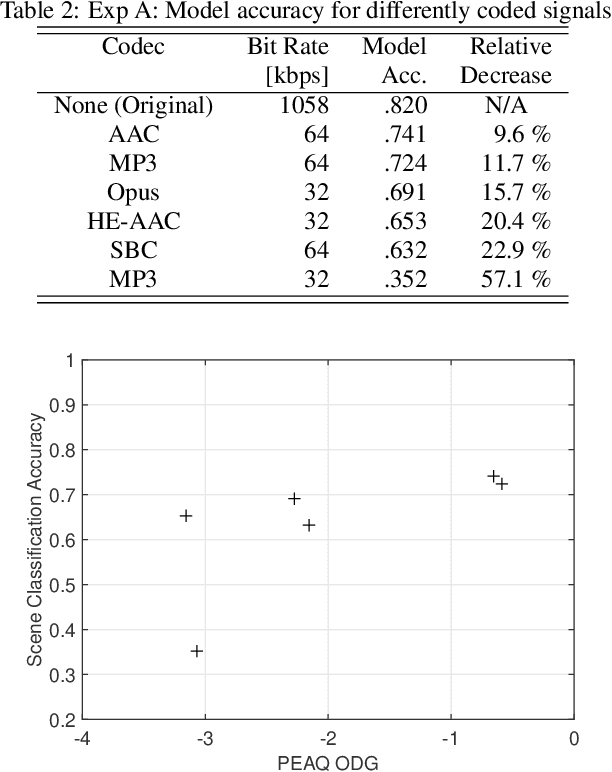
Previous DCASE challenges contributed to an increase in the performance of acoustic scene classification systems. State-of-the-art classifiers demand significant processing capabilities and memory which is challenging for resource-constrained mobile or IoT edge devices. Thus, it is more likely to deploy these models on more powerful hardware and classify audio recordings previously uploaded (or streamed) from low-power edge devices. In such scenario, the edge device may apply perceptual audio coding to reduce the transmission data rate. This paper explores the effect of perceptual audio coding on the classification performance using a DCASE 2020 challenge contribution [1]. We found that classification accuracy can degrade by up to 57% compared to classifying original (uncompressed) audio. We further demonstrate how lossy audio compression techniques during model training can improve classification accuracy of compressed audio signals even for audio codecs and codec bitrates not included in the training process.