 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeThinking Fast and Slow in AI
Oct 12, 2020This paper proposes a research direction to advance AI which draws inspiration from cognitive theories of human decision making. The premise is that if we gain insights about the causes of some human capabilities that are still lacking in AI (for instance, adaptability, generalizability, common sense, and causal reasoning), we may obtain similar capabilities in an AI system by embedding these causal components. We hope that the high-level description of our vision included in this paper, as well as the several research questions that we propose to consider, can stimulate the AI research community to define, try and evaluate new methodologies, frameworks, and evaluation metrics, in the spirit of achieving a better understanding of both human and machine intelligence.
"And the Winner Is": Dynamic Lotteries for Multi-group Fairness-Aware Recommendation
Sep 05, 2020
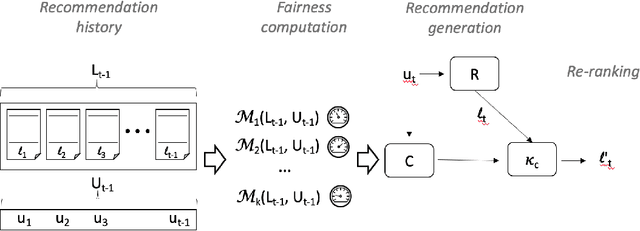

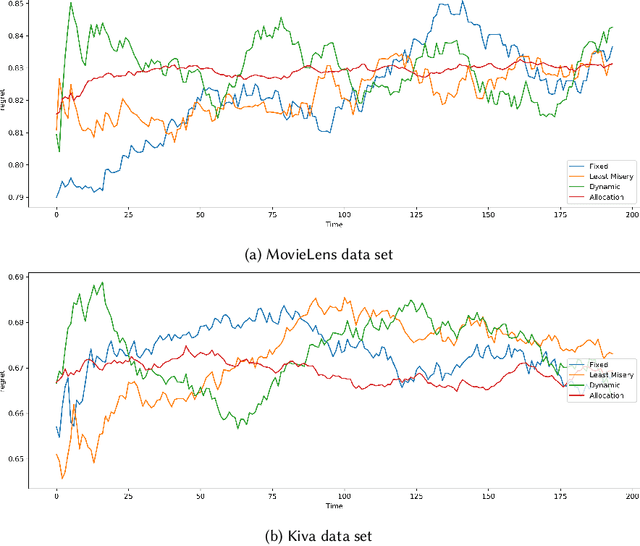
As recommender systems are being designed and deployed for an increasing number of socially-consequential applications, it has become important to consider what properties of fairness these systems exhibit. There has been considerable research on recommendation fairness. However, we argue that the previous literature has been based on simple, uniform and often uni-dimensional notions of fairness assumptions that do not recognize the real-world complexities of fairness-aware applications. In this paper, we explicitly represent the design decisions that enter into the trade-off between accuracy and fairness across multiply-defined and intersecting protected groups, supporting multiple fairness metrics. The framework also allows the recommender to adjust its performance based on the historical view of recommendations that have been delivered over a time horizon, dynamically rebalancing between fairness concerns. Within this framework, we formulate lottery-based mechanisms for choosing between fairness concerns, and demonstrate their performance in two recommendation domains.
PeerNomination: Relaxing Exactness for Increased Accuracy in Peer Selection
Apr 30, 2020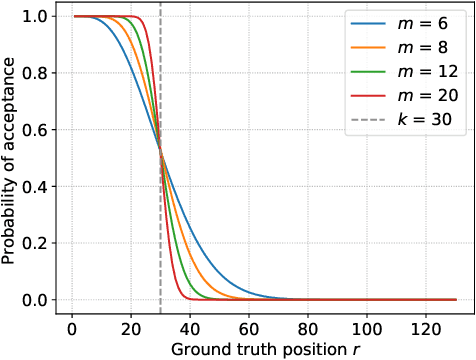
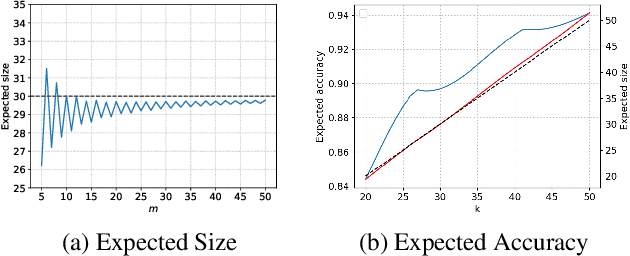
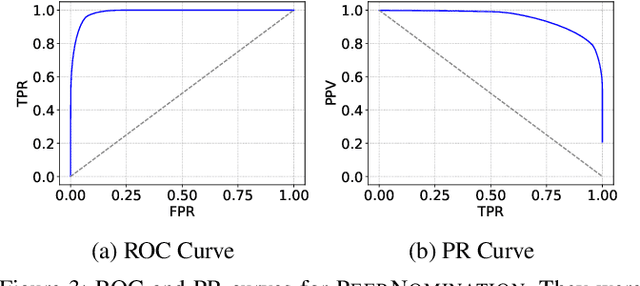
In peer selection agents must choose a subset of themselves for an award or a prize. As agents are self-interested, we want to design algorithms that are impartial, so that an individual agent cannot affect their own chance of being selected. This problem has broad application in resource allocation and mechanism design and has received substantial attention in the artificial intelligence literature. Here, we present a novel algorithm for impartial peer selection, PeerNomination, and provide a theoretical analysis of its accuracy. Our algorithm possesses various desirable features. In particular, it does not require an explicit partitioning of the agents, as previous algorithms in the literature. We show empirically that it achieves higher accuracy than the exiting algorithms over several metrics.
A Multi-Channel Neural Graphical Event Model with Negative Evidence
Feb 21, 2020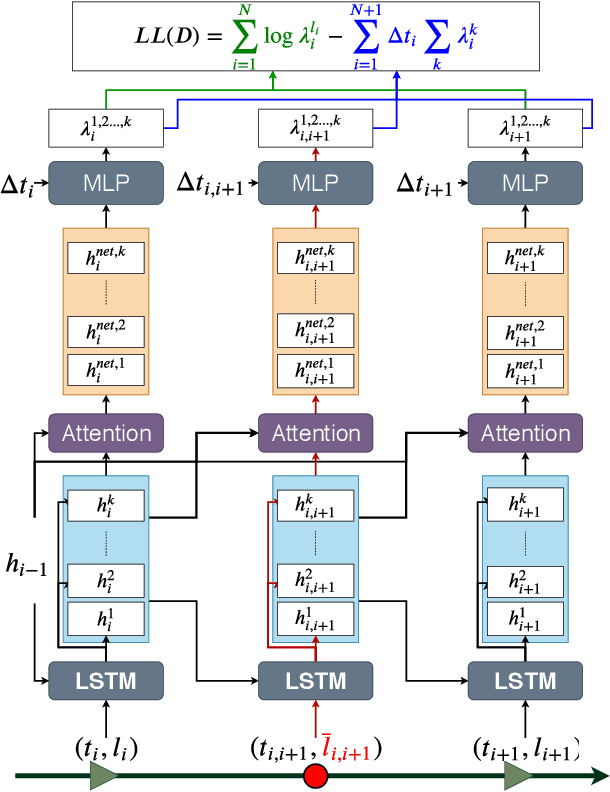
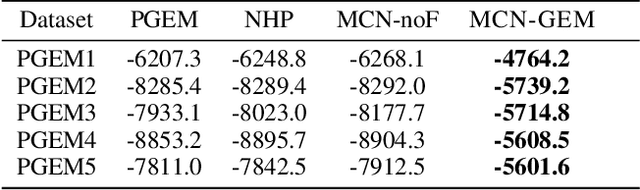
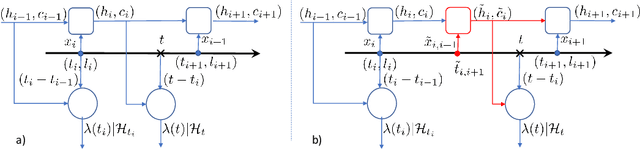
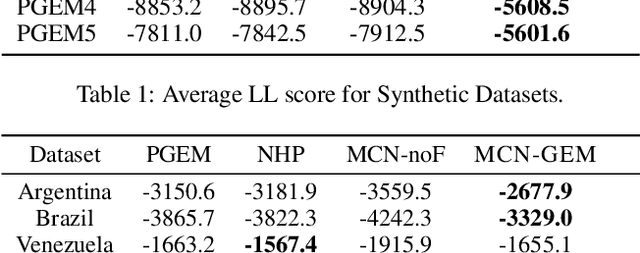
Event datasets are sequences of events of various types occurring irregularly over the time-line, and they are increasingly prevalent in numerous domains. Existing work for modeling events using conditional intensities rely on either using some underlying parametric form to capture historical dependencies, or on non-parametric models that focus primarily on tasks such as prediction. We propose a non-parametric deep neural network approach in order to estimate the underlying intensity functions. We use a novel multi-channel RNN that optimally reinforces the negative evidence of no observable events with the introduction of fake event epochs within each consecutive inter-event interval. We evaluate our method against state-of-the-art baselines on model fitting tasks as gauged by log-likelihood. Through experiments on both synthetic and real-world datasets, we find that our proposed approach outperforms existing baselines on most of the datasets studied.
Group Fairness in Bandit Arm Selection
Dec 09, 2019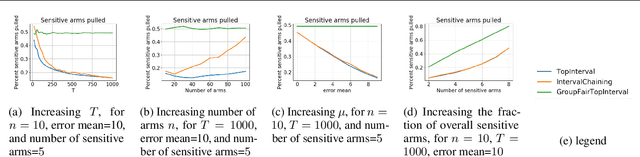
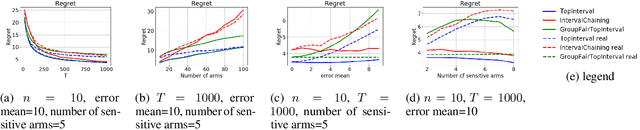
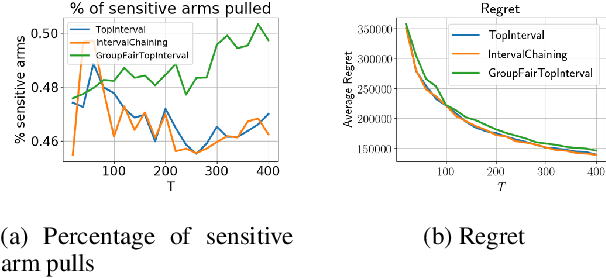
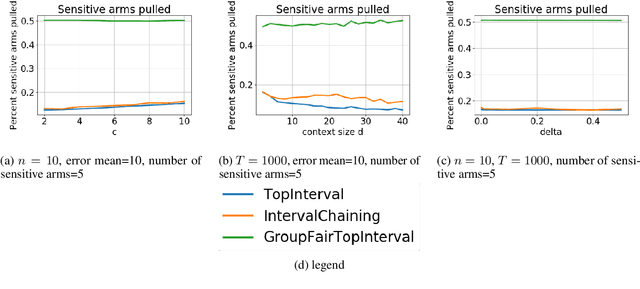
We consider group fairness in the contextual bandit setting. Here, a sequential decision maker must choose at each time step an arm to pull from a finite set of arms, after observing some context for each of the potential arm pulls. Additionally, arms are partitioned into m sensitive groups based on some protected feature (e.g., age, race, or socio-economic status). Despite the fact that there may be differences in expected payout between the groups, we may wish to ensure some form of fairness between picking arms from the various groups. In this work, we explore two definitions of fairness: equal group probability, wherein the probability of pulling an arm from any of the protected groups is the same; and proportional parity, wherein the probability of choosing an arm from a particular group is proportional to the size of that group. We provide a novel algorithm that can accommodate these notions of fairness and provide bounds on the regret for our algorithm. We test our algorithms on a hypothetical intervention setting wherein we want to allocate resources across protected groups.
Heuristic Strategies in Uncertain Approval Voting Environments
Nov 29, 2019
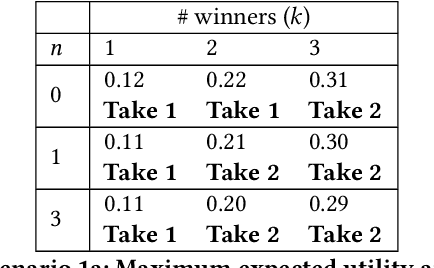
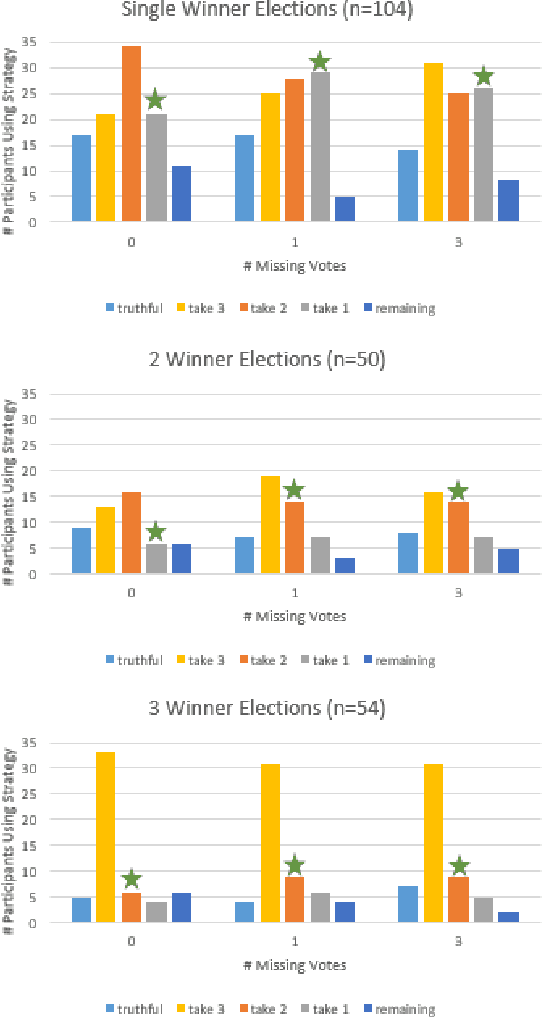
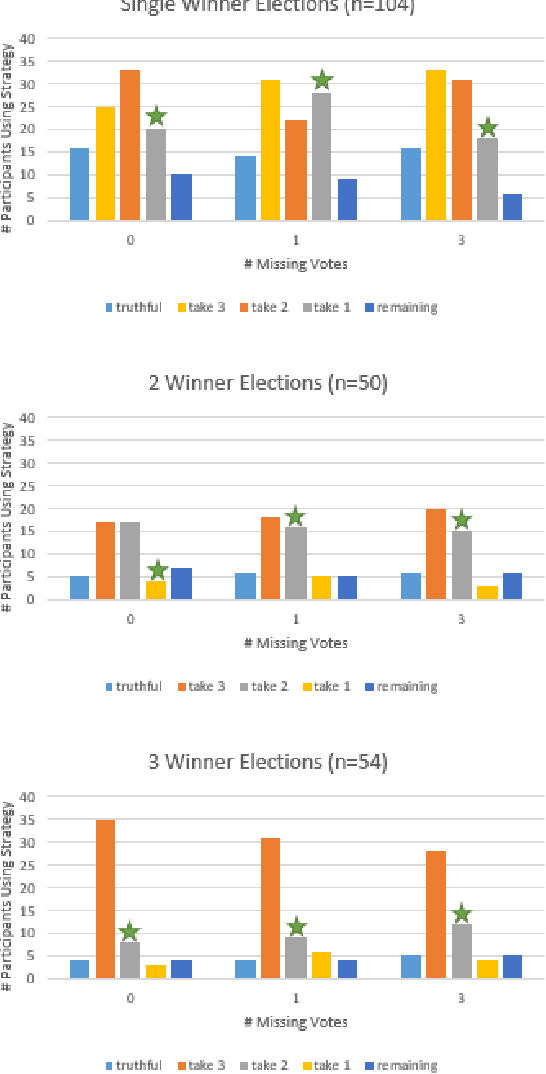
In many collective decision making situations, agents vote to choose an alternative that best represents the preferences of the group. Agents may manipulate the vote to achieve a better outcome by voting in a way that does not reflect their true preferences. In real world voting scenarios, people often do not have complete information about other voter preferences and it can be computationally complex to identify a strategy that will maximize their expected utility. In such situations, it is often assumed that voters will vote truthfully rather than expending the effort to strategize. However, being truthful is just one possible heuristic that may be used. In this paper, we examine the effectiveness of heuristics in single winner and multi-winner approval voting scenarios with missing votes. In particular, we look at heuristics where a voter ignores information about other voting profiles and makes their decisions based solely on how much they like each candidate. In a behavioral experiment, we show that people vote truthfully in some situations and prioritize high utility candidates in others. We examine when these behaviors maximize expected utility and show how the structure of the voting environment affects both how well each heuristic performs and how humans employ these heuristics.
Infusing Knowledge into the Textual Entailment Task Using Graph Convolutional Networks
Nov 22, 2019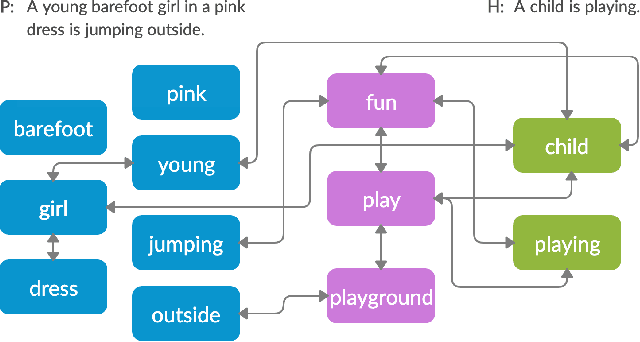

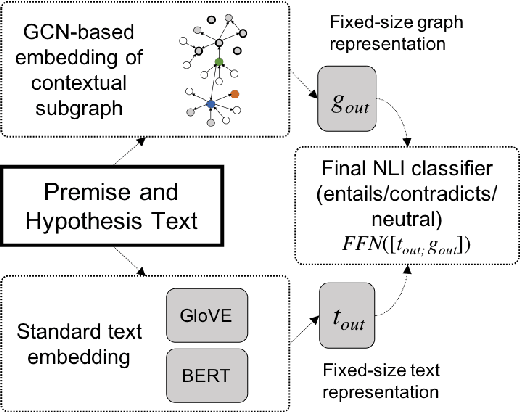
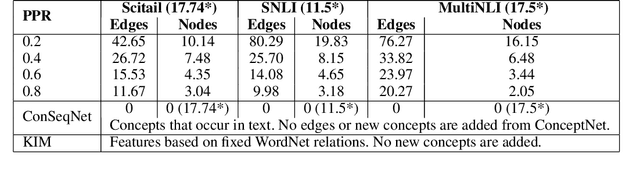
Textual entailment is a fundamental task in natural language processing. Most approaches for solving the problem use only the textual content present in training data. A few approaches have shown that information from external knowledge sources like knowledge graphs (KGs) can add value, in addition to the textual content, by providing background knowledge that may be critical for a task. However, the proposed models do not fully exploit the information in the usually large and noisy KGs, and it is not clear how it can be effectively encoded to be useful for entailment. We present an approach that complements text-based entailment models with information from KGs by (1) using Personalized PageR- ank to generate contextual subgraphs with reduced noise and (2) encoding these subgraphs using graph convolutional networks to capture KG structure. Our technique extends the capability of text models exploiting structural and semantic information found in KGs. We evaluate our approach on multiple textual entailment datasets and show that the use of external knowledge helps improve prediction accuracy. This is particularly evident in the challenging BreakingNLI dataset, where we see an absolute improvement of 5-20% over multiple text-based entailment models.
Heuristics in Multi-Winner Approval Voting
May 30, 2019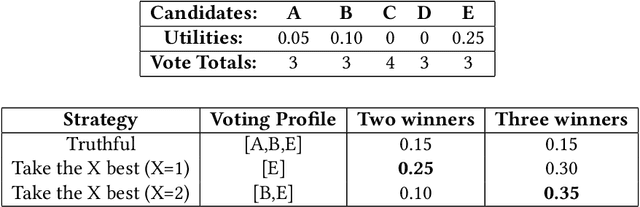
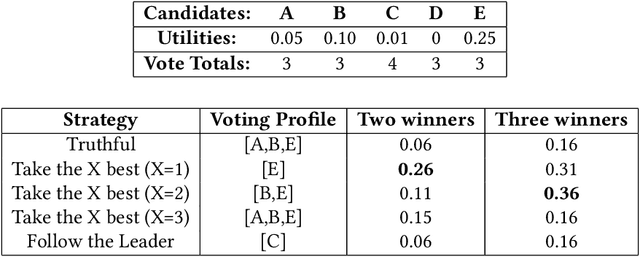
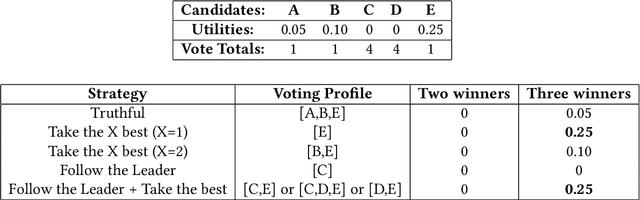
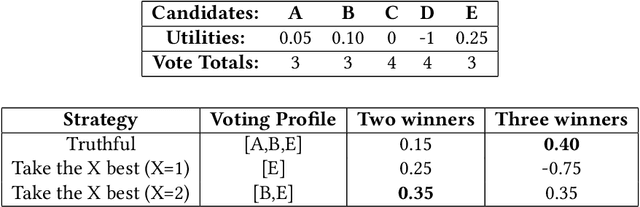
In many real world situations, collective decisions are made using voting. Moreover, scenarios such as committee or board elections require voting rules that return multiple winners. In multi-winner approval voting (AV), an agent may vote for as many candidates as they wish. Winners are chosen by tallying up the votes and choosing the top-$k$ candidates receiving the most votes. An agent may manipulate the vote to achieve a better outcome by voting in a way that does not reflect their true preferences. In complex and uncertain situations, agents may use heuristics to strategize, instead of incurring the additional effort required to compute the manipulation which most favors them. In this paper, we examine voting behavior in multi-winner approval voting scenarios with complete information. We show that people generally manipulate their vote to obtain a better outcome, but often do not identify the optimal manipulation. Instead, voters tend to prioritize the candidates with the highest utilities. Using simulations, we demonstrate the effectiveness of these heuristics in situations where agents only have access to partial information.
Building Ethically Bounded AI
Dec 10, 2018The more AI agents are deployed in scenarios with possibly unexpected situations, the more they need to be flexible, adaptive, and creative in achieving the goal we have given them. Thus, a certain level of freedom to choose the best path to the goal is inherent in making AI robust and flexible enough. At the same time, however, the pervasive deployment of AI in our life, whether AI is autonomous or collaborating with humans, raises several ethical challenges. AI agents should be aware and follow appropriate ethical principles and should thus exhibit properties such as fairness or other virtues. These ethical principles should define the boundaries of AI's freedom and creativity. However, it is still a challenge to understand how to specify and reason with ethical boundaries in AI agents and how to combine them appropriately with subjective preferences and goal specifications. Some initial attempts employ either a data-driven example-based approach for both, or a symbolic rule-based approach for both. We envision a modular approach where any AI technique can be used for any of these essential ingredients in decision making or decision support systems, paired with a contextual approach to define their combination and relative weight. In a world where neither humans nor AI systems work in isolation, but are tightly interconnected, e.g., the Internet of Things, we also envision a compositional approach to building ethically bounded AI, where the ethical properties of each component can be fruitfully exploited to derive those of the overall system. In this paper we define and motivate the notion of ethically-bounded AI, we describe two concrete examples, and we outline some outstanding challenges.
CPDist: Deep Siamese Networks for Learning Distances Between Structured Preferences
Sep 21, 2018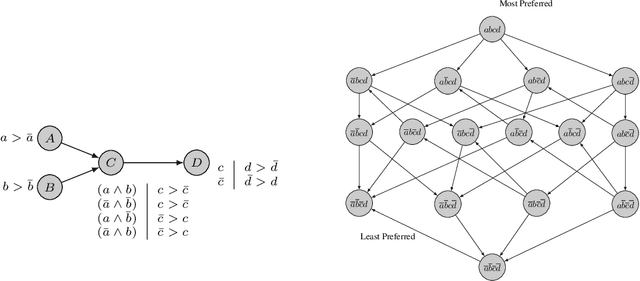
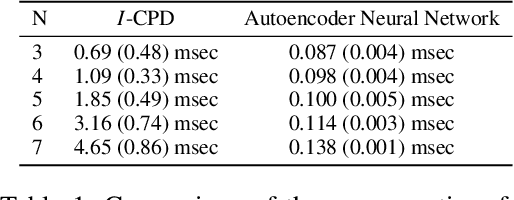
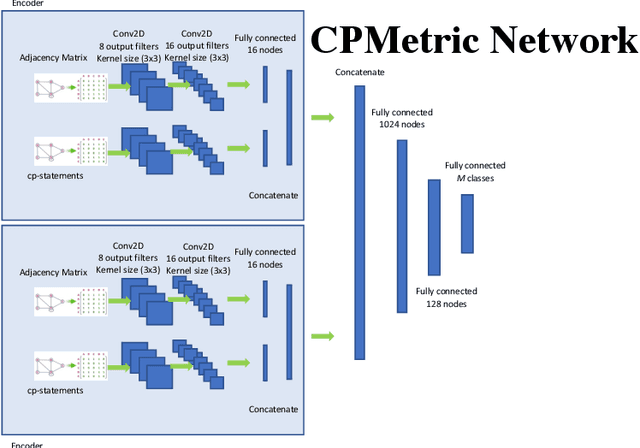
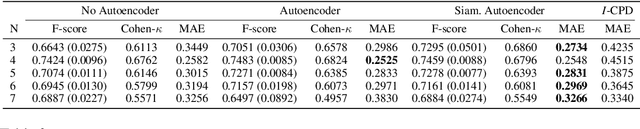
Preference are central to decision making by both machines and humans. Representing, learning, and reasoning with preferences is an important area of study both within computer science and across the sciences. When working with preferences it is necessary to understand and compute the distance between sets of objects, e.g., the preferences of a user and a the descriptions of objects to be recommended. We present CPDist, a novel neural network to address the problem of learning to measure the distance between structured preference representations. We use the popular CP-net formalism to represent preferences and then leverage deep neural networks to learn a recently proposed metric function that is computationally hard to compute directly. CPDist is a novel metric learning approach based on the use of deep siamese networks which learn the Kendal Tau distance between partial orders that are induced by compact preference representations. We find that CPDist is able to learn the distance function with high accuracy and outperform existing approximation algorithms on both the regression and classification task using less computation time. Performance remains good even when CPDist is trained with only a small number of samples compared to the dimension of the solution space, indicating the network generalizes well.