 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeTowards General-Purpose Representation Learning of Polygonal Geometries
Sep 29, 2022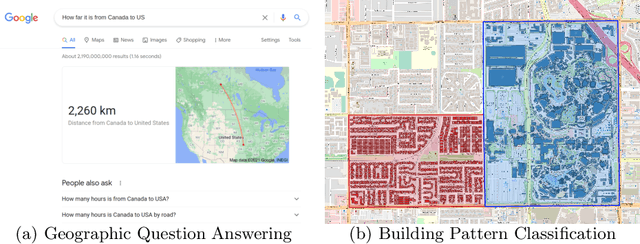
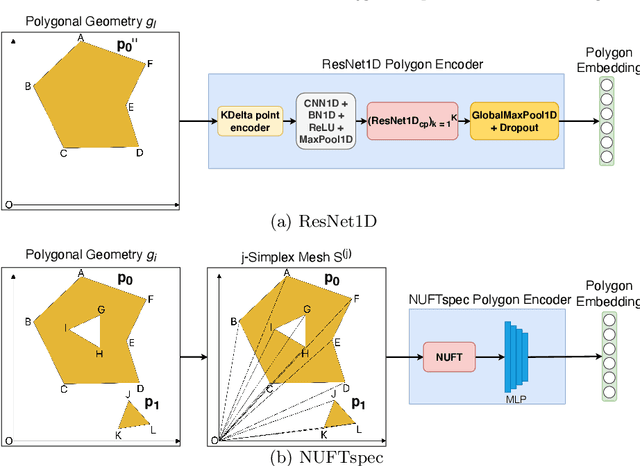

Neural network representation learning for spatial data is a common need for geographic artificial intelligence (GeoAI) problems. In recent years, many advancements have been made in representation learning for points, polylines, and networks, whereas little progress has been made for polygons, especially complex polygonal geometries. In this work, we focus on developing a general-purpose polygon encoding model, which can encode a polygonal geometry (with or without holes, single or multipolygons) into an embedding space. The result embeddings can be leveraged directly (or finetuned) for downstream tasks such as shape classification, spatial relation prediction, and so on. To achieve model generalizability guarantees, we identify a few desirable properties: loop origin invariance, trivial vertex invariance, part permutation invariance, and topology awareness. We explore two different designs for the encoder: one derives all representations in the spatial domain; the other leverages spectral domain representations. For the spatial domain approach, we propose ResNet1D, a 1D CNN-based polygon encoder, which uses circular padding to achieve loop origin invariance on simple polygons. For the spectral domain approach, we develop NUFTspec based on Non-Uniform Fourier Transformation (NUFT), which naturally satisfies all the desired properties. We conduct experiments on two tasks: 1) shape classification based on MNIST; 2) spatial relation prediction based on two new datasets - DBSR-46K and DBSR-cplx46K. Our results show that NUFTspec and ResNet1D outperform multiple existing baselines with significant margins. While ResNet1D suffers from model performance degradation after shape-invariance geometry modifications, NUFTspec is very robust to these modifications due to the nature of the NUFT.
Sphere2Vec: Multi-Scale Representation Learning over a Spherical Surface for Geospatial Predictions
Jan 25, 2022Generating learning-friendly representations for points in a 2D space is a fundamental and long-standing problem in machine learning. Recently, multi-scale encoding schemes (such as Space2Vec) were proposed to directly encode any point in 2D space as a high-dimensional vector, and has been successfully applied to various (geo)spatial prediction tasks. However, a map projection distortion problem rises when applying location encoding models to large-scale real-world GPS coordinate datasets (e.g., species images taken all over the world) - all current location encoding models are designed for encoding points in a 2D (Euclidean) space but not on a spherical surface, e.g., earth surface. To solve this problem, we propose a multi-scale location encoding model called Sphere2V ec which directly encodes point coordinates on a spherical surface while avoiding the mapprojection distortion problem. We provide theoretical proof that the Sphere2Vec encoding preserves the spherical surface distance between any two points. We also developed a unified view of distance-reserving encoding on spheres based on the Double Fourier Sphere (DFS). We apply Sphere2V ec to the geo-aware image classification task. Our analysis shows that Sphere2V ec outperforms other 2D space location encoder models especially on the polar regions and data-sparse areas for image classification tasks because of its nature for spherical surface distance preservation.
Narrative Cartography with Knowledge Graphs
Dec 02, 2021
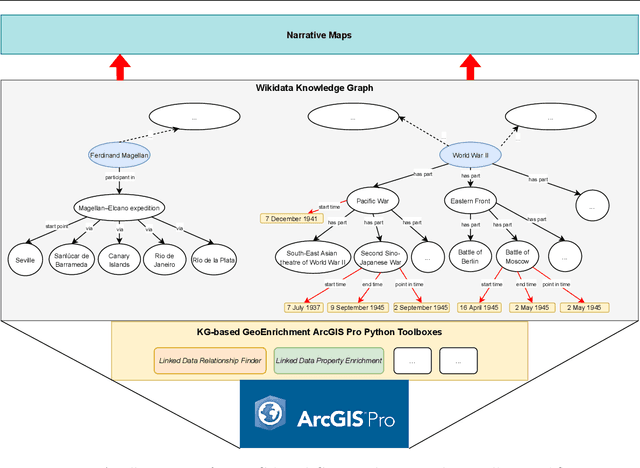
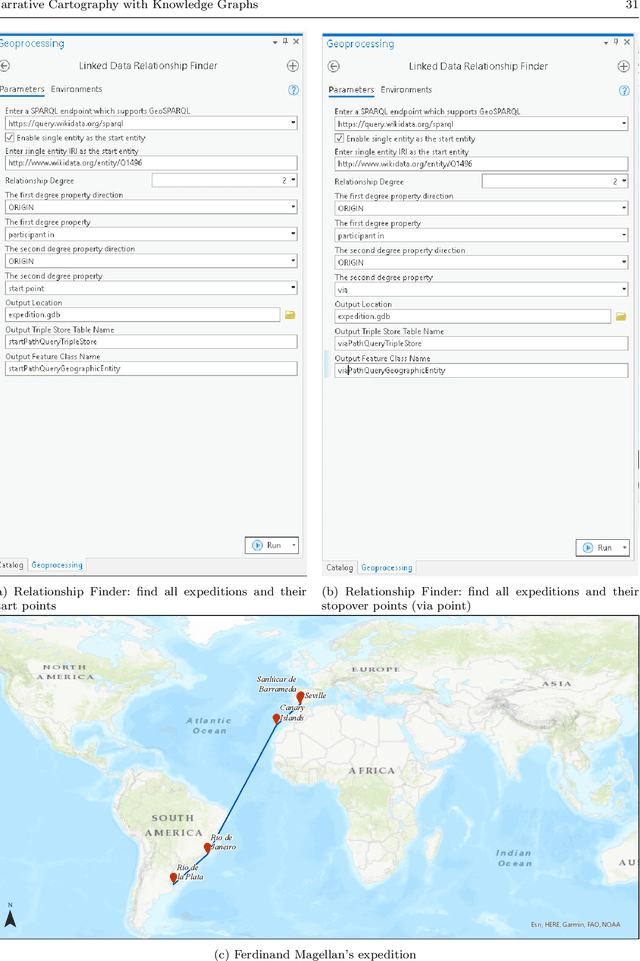
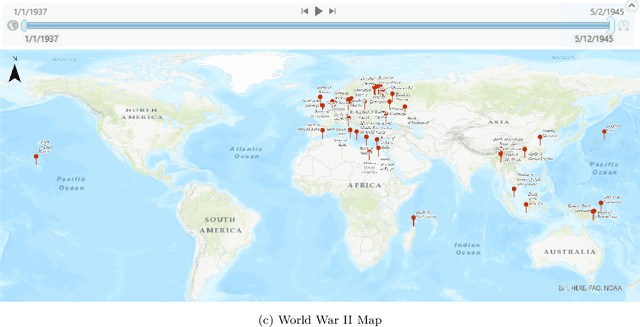
Narrative cartography is a discipline which studies the interwoven nature of stories and maps. However, conventional geovisualization techniques of narratives often encounter several prominent challenges, including the data acquisition & integration challenge and the semantic challenge. To tackle these challenges, in this paper, we propose the idea of narrative cartography with knowledge graphs (KGs). Firstly, to tackle the data acquisition & integration challenge, we develop a set of KG-based GeoEnrichment toolboxes to allow users to search and retrieve relevant data from integrated cross-domain knowledge graphs for narrative mapping from within a GISystem. With the help of this tool, the retrieved data from KGs are directly materialized in a GIS format which is ready for spatial analysis and mapping. Two use cases - Magellan's expedition and World War II - are presented to show the effectiveness of this approach. In the meantime, several limitations are identified from this approach, such as data incompleteness, semantic incompatibility, and the semantic challenge in geovisualization. For the later two limitations, we propose a modular ontology for narrative cartography, which formalizes both the map content (Map Content Module) and the geovisualization process (Cartography Module). We demonstrate that, by representing both the map content and the geovisualization process in KGs (an ontology), we can realize both data reusability and map reproducibility for narrative cartography.
A Review of Location Encoding for GeoAI: Methods and Applications
Nov 07, 2021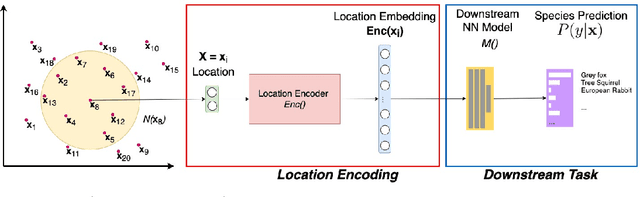
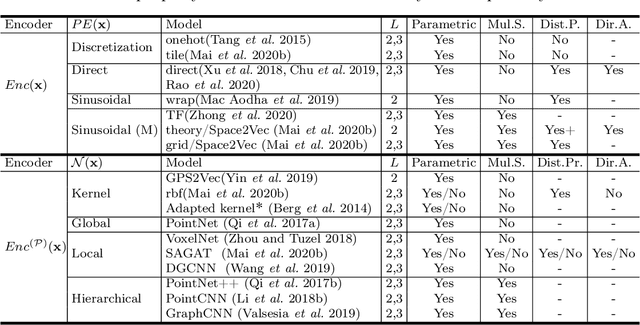
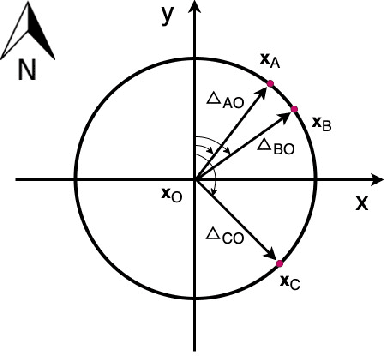
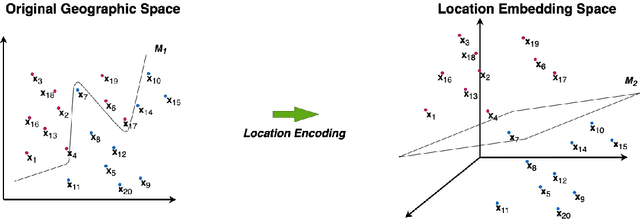
A common need for artificial intelligence models in the broader geoscience is to represent and encode various types of spatial data, such as points (e.g., points of interest), polylines (e.g., trajectories), polygons (e.g., administrative regions), graphs (e.g., transportation networks), or rasters (e.g., remote sensing images), in a hidden embedding space so that they can be readily incorporated into deep learning models. One fundamental step is to encode a single point location into an embedding space, such that this embedding is learning-friendly for downstream machine learning models such as support vector machines and neural networks. We call this process location encoding. However, there lacks a systematic review on the concept of location encoding, its potential applications, and key challenges that need to be addressed. This paper aims to fill this gap. We first provide a formal definition of location encoding, and discuss the necessity of location encoding for GeoAI research from a machine learning perspective. Next, we provide a comprehensive survey and discussion about the current landscape of location encoding research. We classify location encoding models into different categories based on their inputs and encoding methods, and compare them based on whether they are parametric, multi-scale, distance preserving, and direction aware. We demonstrate that existing location encoding models can be unified under a shared formulation framework. We also discuss the application of location encoding for different types of spatial data. Finally, we point out several challenges in location encoding research that need to be solved in the future.
* 32 Pages, 5 Figures, Accepted to International Journal of Geographical Information Science, 2021
Geographic Question Answering: Challenges, Uniqueness, Classification, and Future Directions
May 19, 2021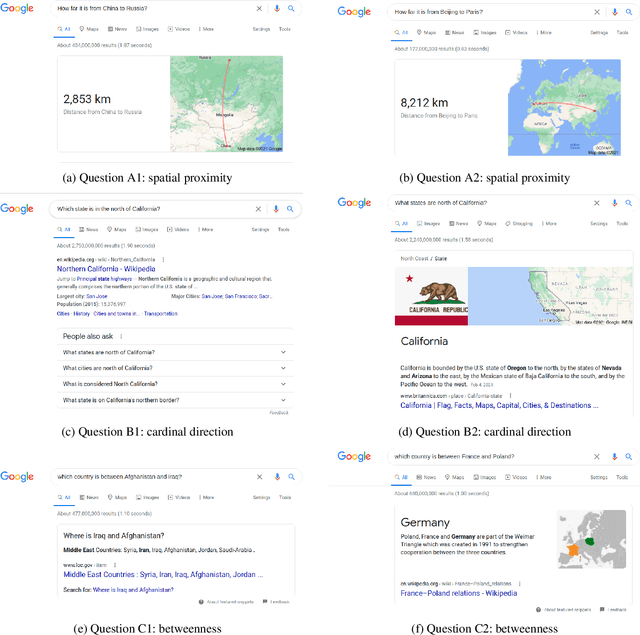
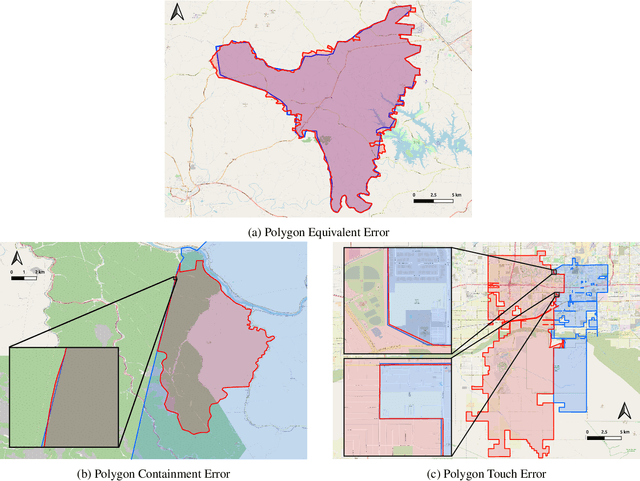
As an important part of Artificial Intelligence (AI), Question Answering (QA) aims at generating answers to questions phrased in natural language. While there has been substantial progress in open-domain question answering, QA systems are still struggling to answer questions which involve geographic entities or concepts and that require spatial operations. In this paper, we discuss the problem of geographic question answering (GeoQA). We first investigate the reasons why geographic questions are difficult to answer by analyzing challenges of geographic questions. We discuss the uniqueness of geographic questions compared to general QA. Then we review existing work on GeoQA and classify them by the types of questions they can address. Based on this survey, we provide a generic classification framework for geographic questions. Finally, we conclude our work by pointing out unique future research directions for GeoQA.
* 20 pages, 3 figure, Full paper accepted to AGILE 2021
Pivot Through English: Reliably Answering Multilingual Questions without Document Retrieval
Dec 28, 2020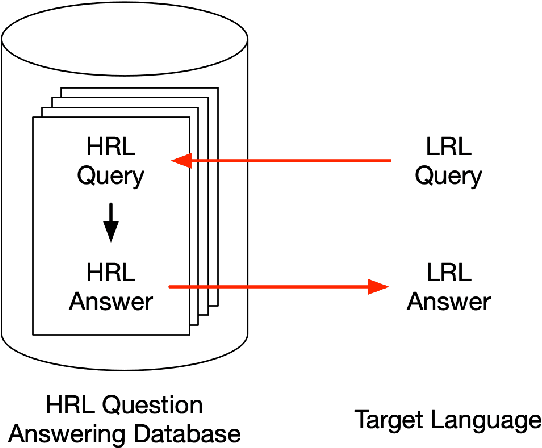

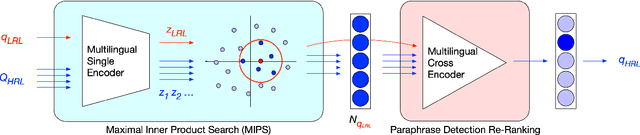
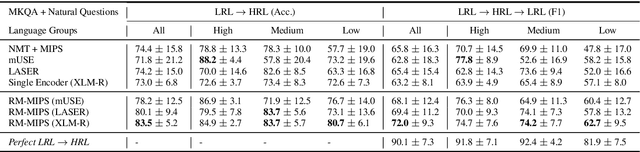
Existing methods for open-retrieval question answering in lower resource languages (LRLs) lag significantly behind English. They not only suffer from the shortcomings of non-English document retrieval, but are reliant on language-specific supervision for either the task or translation. We formulate a task setup more realistic to available resources, that circumvents document retrieval to reliably transfer knowledge from English to lower resource languages. Assuming a strong English question answering model or database, we compare and analyze methods that pivot through English: to map foreign queries to English and then English answers back to target language answers. Within this task setup we propose Reranked Multilingual Maximal Inner Product Search (RM-MIPS), akin to semantic similarity retrieval over the English training set with reranking, which outperforms the strongest baselines by 2.7% on XQuAD and 6.2% on MKQA. Analysis demonstrates the particular efficacy of this strategy over state-of-the-art alternatives in challenging settings: low-resource languages, with extensive distractor data and query distribution misalignment. Circumventing retrieval, our analysis shows this approach offers rapid answer generation to almost any language off-the-shelf, without the need for any additional training data in the target language.
SE-KGE: A Location-Aware Knowledge Graph Embedding Model for Geographic Question Answering and Spatial Semantic Lifting
Apr 25, 2020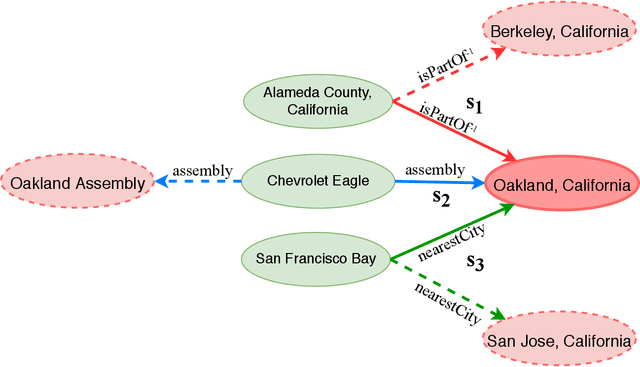


Learning knowledge graph (KG) embeddings is an emerging technique for a variety of downstream tasks such as summarization, link prediction, information retrieval, and question answering. However, most existing KG embedding models neglect space and, therefore, do not perform well when applied to (geo)spatial data and tasks. For those models that consider space, most of them primarily rely on some notions of distance. These models suffer from higher computational complexity during training while still losing information beyond the relative distance between entities. In this work, we propose a location-aware KG embedding model called SE-KGE. It directly encodes spatial information such as point coordinates or bounding boxes of geographic entities into the KG embedding space. The resulting model is capable of handling different types of spatial reasoning. We also construct a geographic knowledge graph as well as a set of geographic query-answer pairs called DBGeo to evaluate the performance of SE-KGE in comparison to multiple baselines. Evaluation results show that SE-KGE outperforms these baselines on the DBGeo dataset for geographic logic query answering task. This demonstrates the effectiveness of our spatially-explicit model and the importance of considering the scale of different geographic entities. Finally, we introduce a novel downstream task called spatial semantic lifting which links an arbitrary location in the study area to entities in the KG via some relations. Evaluation on DBGeo shows that our model outperforms the baseline by a substantial margin.
* Accepted to Transactions in GIS
Semantically-Enriched Search Engine for Geoportals: A Case Study with ArcGIS Online
Mar 14, 2020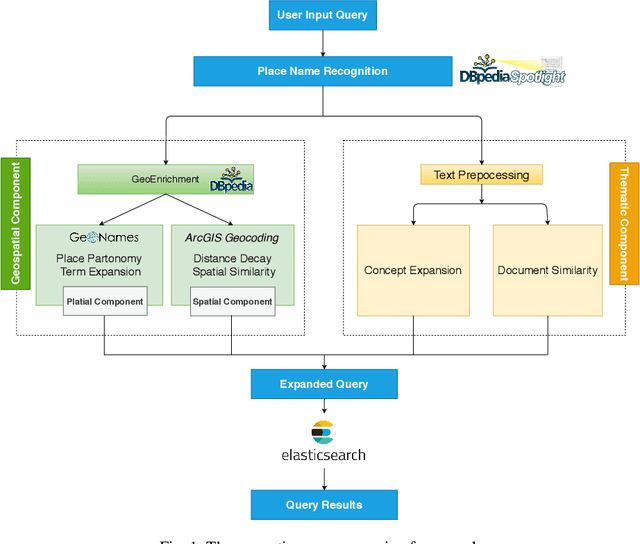
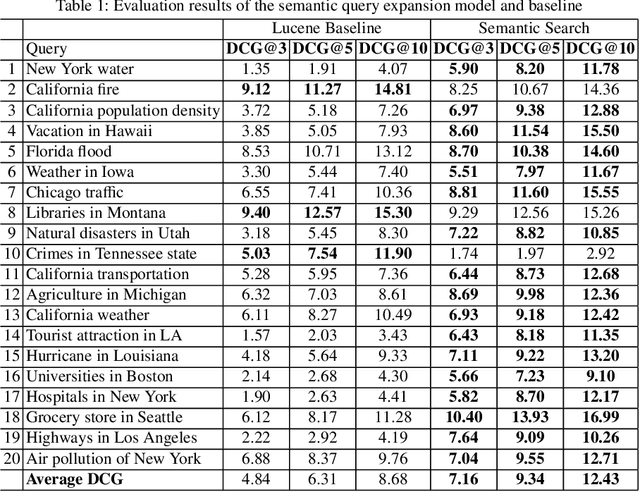

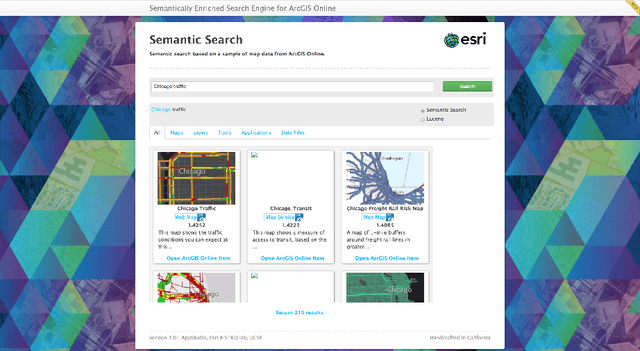
Many geoportals such as ArcGIS Online are established with the goal of improving geospatial data reusability and achieving intelligent knowledge discovery. However, according to previous research, most of the existing geoportals adopt Lucene-based techniques to achieve their core search functionality, which has a limited ability to capture the user's search intentions. To better understand a user's search intention, query expansion can be used to enrich the user's query by adding semantically similar terms. In the context of geoportals and geographic information retrieval, we advocate the idea of semantically enriching a user's query from both geospatial and thematic perspectives. In the geospatial aspect, we propose to enrich a query by using both place partonomy and distance decay. In terms of the thematic aspect, concept expansion and embedding-based document similarity are used to infer the implicit information hidden in a user's query. This semantic query expansion 1 2 G. Mai et al. framework is implemented as a semantically-enriched search engine using ArcGIS Online as a case study. A benchmark dataset is constructed to evaluate the proposed framework. Our evaluation results show that the proposed semantic query expansion framework is very effective in capturing a user's search intention and significantly outperforms a well-established baseline-Lucene's practical scoring function-with more than 3.0 increments in DCG@K (K=3,5,10).
* 18 pages; Accepted to AGILE 2020 as a full paper GitHub Code Repository: https://github.com/gengchenmai/arcgis-online-search-engine
Multi-Scale Representation Learning for Spatial Feature Distributions using Grid Cells
Feb 16, 2020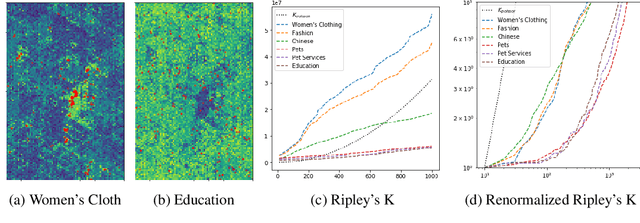
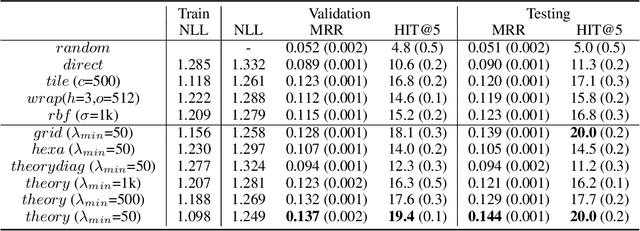

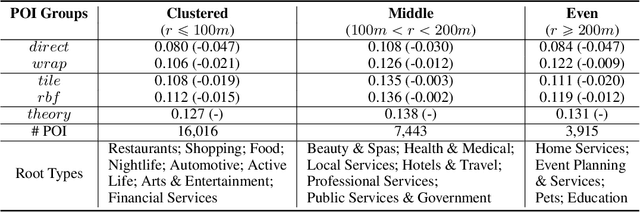
Unsupervised text encoding models have recently fueled substantial progress in NLP. The key idea is to use neural networks to convert words in texts to vector space representations based on word positions in a sentence and their contexts, which are suitable for end-to-end training of downstream tasks. We see a strikingly similar situation in spatial analysis, which focuses on incorporating both absolute positions and spatial contexts of geographic objects such as POIs into models. A general-purpose representation model for space is valuable for a multitude of tasks. However, no such general model exists to date beyond simply applying discretization or feed-forward nets to coordinates, and little effort has been put into jointly modeling distributions with vastly different characteristics, which commonly emerges from GIS data. Meanwhile, Nobel Prize-winning Neuroscience research shows that grid cells in mammals provide a multi-scale periodic representation that functions as a metric for location encoding and is critical for recognizing places and for path-integration. Therefore, we propose a representation learning model called Space2Vec to encode the absolute positions and spatial relationships of places. We conduct experiments on two real-world geographic data for two different tasks: 1) predicting types of POIs given their positions and context, 2) image classification leveraging their geo-locations. Results show that because of its multi-scale representations, Space2Vec outperforms well-established ML approaches such as RBF kernels, multi-layer feed-forward nets, and tile embedding approaches for location modeling and image classification tasks. Detailed analysis shows that all baselines can at most well handle distribution at one scale but show poor performances in other scales. In contrast, Space2Vec's multi-scale representation can handle distributions at different scales.
* 15 pages; Accepted to ICLR 2020 as a spotlight paper
Contextual Graph Attention for Answering Logical Queries over Incomplete Knowledge Graphs
Sep 30, 2019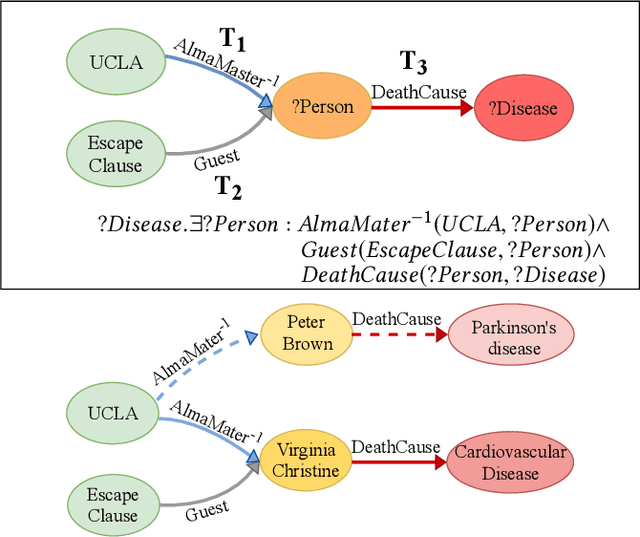

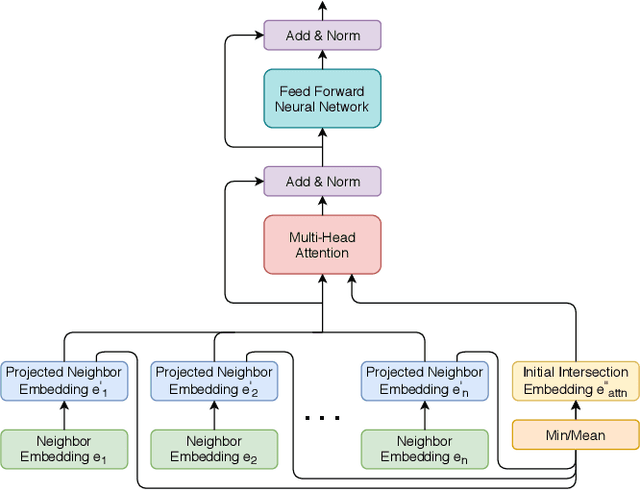
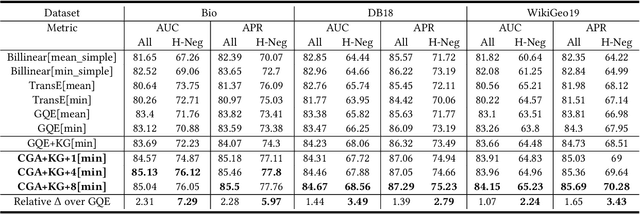
Recently, several studies have explored methods for using KG embedding to answer logical queries. These approaches either treat embedding learning and query answering as two separated learning tasks, or fail to deal with the variability of contributions from different query paths. We proposed to leverage a graph attention mechanism to handle the unequal contribution of different query paths. However, commonly used graph attention assumes that the center node embedding is provided, which is unavailable in this task since the center node is to be predicted. To solve this problem we propose a multi-head attention-based end-to-end logical query answering model, called Contextual Graph Attention model(CGA), which uses an initial neighborhood aggregation layer to generate the center embedding, and the whole model is trained jointly on the original KG structure as well as the sampled query-answer pairs. We also introduce two new datasets, DB18 and WikiGeo19, which are rather large in size compared to the existing datasets and contain many more relation types, and use them to evaluate the performance of the proposed model. Our result shows that the proposed CGA with fewer learnable parameters consistently outperforms the baseline models on both datasets as well as Bio dataset.
* 8 pages, 3 figures, camera ready version of article accepted to K-CAP 2019, Marina del Rey, California, United States