 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeMore Embeddings, Better Sequence Labelers?
Oct 10, 2020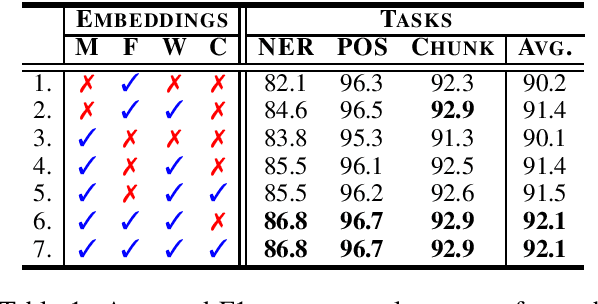
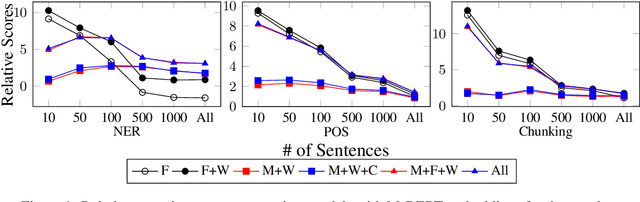

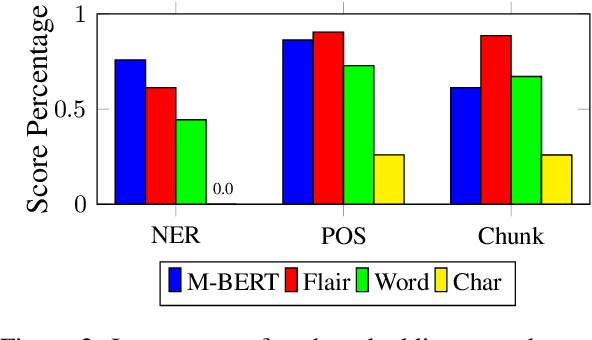
Recent work proposes a family of contextual embeddings that significantly improves the accuracy of sequence labelers over non-contextual embeddings. However, there is no definite conclusion on whether we can build better sequence labelers by combining different kinds of embeddings in various settings. In this paper, we conduct extensive experiments on 3 tasks over 18 datasets and 8 languages to study the accuracy of sequence labeling with various embedding concatenations and make three observations: (1) concatenating more embedding variants leads to better accuracy in rich-resource and cross-domain settings and some conditions of low-resource settings; (2) concatenating additional contextual sub-word embeddings with contextual character embeddings hurts the accuracy in extremely low-resource settings; (3) based on the conclusion of (1), concatenating additional similar contextual embeddings cannot lead to further improvements. We hope these conclusions can help people build stronger sequence labelers in various settings.
Structure-Level Knowledge Distillation For Multilingual Sequence Labeling
Apr 29, 2020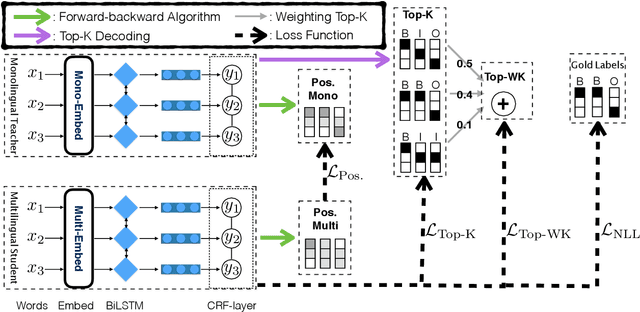
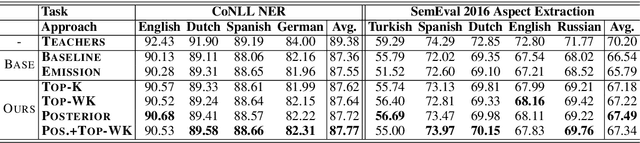
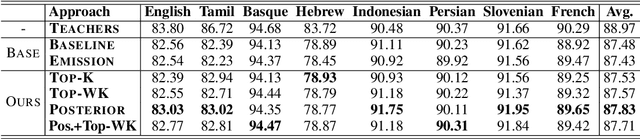
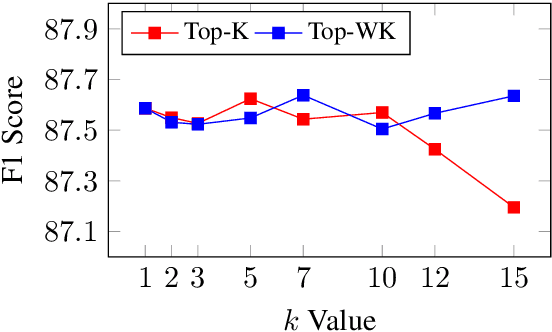
Multilingual sequence labeling is a task of predicting label sequences using a single unified model for multiple languages. Compared with relying on multiple monolingual models, using a multilingual model has the benefit of a smaller model size, easier in online serving, and generalizability to low-resource languages. However, current multilingual models still underperform individual monolingual models significantly due to model capacity limitations. In this paper, we propose to reduce the gap between monolingual models and the unified multilingual model by distilling the structural knowledge of several monolingual models (teachers) to the unified multilingual model (student). We propose two novel KD methods based on structure-level information: (1) approximately minimizes the distance between the student's and the teachers' structure level probability distributions, (2) aggregates the structure-level knowledge to local distributions and minimizes the distance between two local probability distributions. Our experiments on 4 multilingual tasks with 25 datasets show that our approaches outperform several strong baselines and have stronger zero-shot generalizability than both the baseline model and teacher models.
Unsupervised Multi-modal Neural Machine Translation
Nov 28, 2018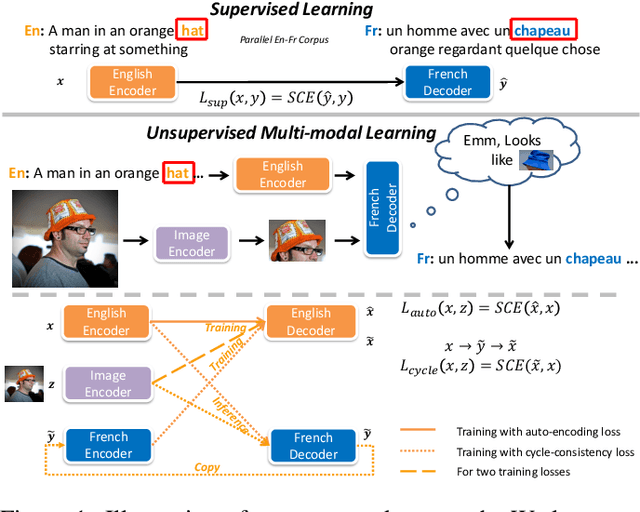
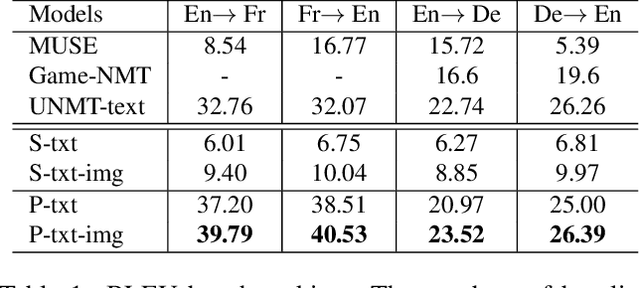
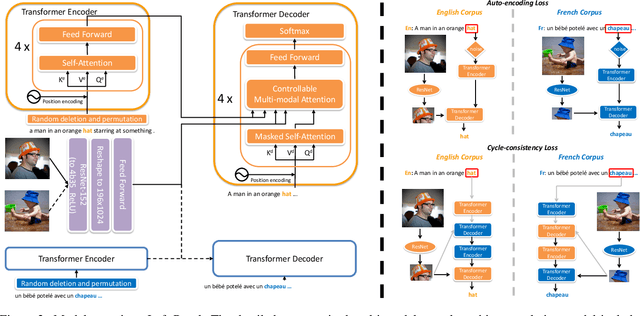

Unsupervised neural machine translation (UNMT) has recently achieved remarkable results with only large monolingual corpora in each language. However, the uncertainty of associating target with source sentences makes UNMT theoretically an ill-posed problem. This work investigates the possibility of utilizing images for disambiguation to improve the performance of UNMT. Our assumption is intuitively based on the invariant property of image, i.e., the description of the same visual content by different languages should be approximately similar. We propose an unsupervised multi-modal machine translation (UMNMT) framework based on the language translation cycle consistency loss conditional on the image, targeting to learn the bidirectional multi-modal translation simultaneously. Through an alternate training between multi-modal and uni-modal, our inference model can translate with or without the image. On the widely used Multi30K dataset, the experimental results of our approach are significantly better than those of the text-only UNMT on the 2016 test dataset.