 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeAn End-to-End Khmer Optical Character Recognition using Sequence-to-Sequence with Attention
Jun 21, 2021
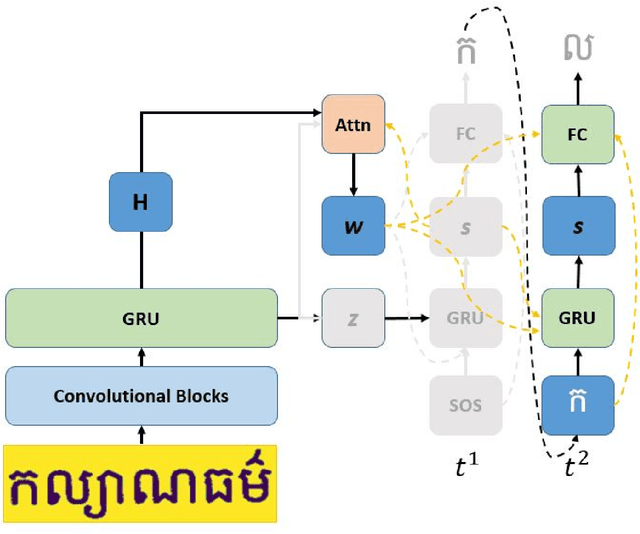
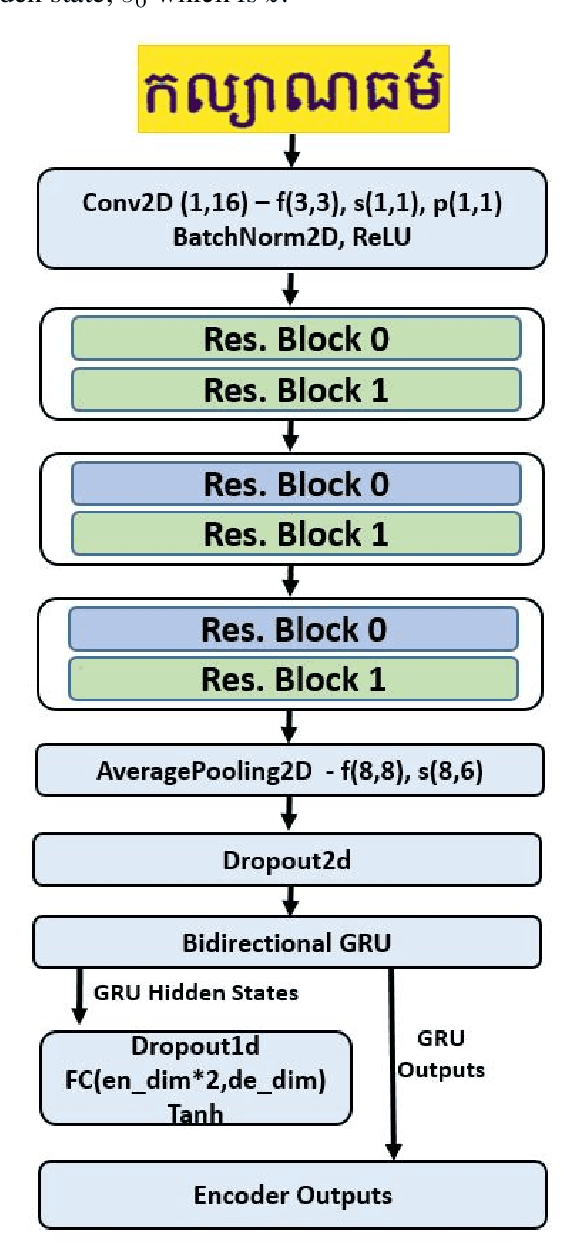
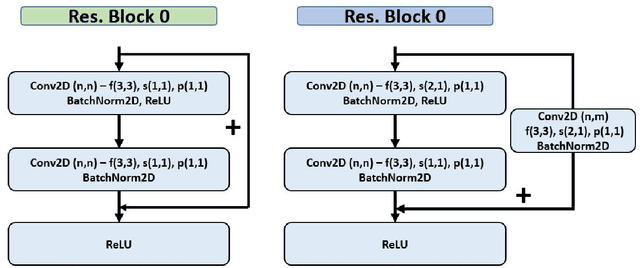
This paper presents an end-to-end deep convolutional recurrent neural network solution for Khmer optical character recognition (OCR) task. The proposed solution uses a sequence-to-sequence (Seq2Seq) architecture with attention mechanism. The encoder extracts visual features from an input text-line image via layers of residual convolutional blocks and a layer of gated recurrent units (GRU). The features are encoded in a single context vector and a sequence of hidden states which are fed to the decoder for decoding one character at a time until a special end-of-sentence (EOS) token is reached. The attention mechanism allows the decoder network to adaptively select parts of the input image while predicting a target character. The Seq2Seq Khmer OCR network was trained on a large collection of computer-generated text-line images for seven common Khmer fonts. The proposed model's performance outperformed the state-of-art Tesseract OCR engine for Khmer language on the 3000-images test set by achieving a character error rate (CER) of 1% vs 3%.
Joint Khmer Word Segmentation and Part-of-Speech Tagging Using Deep Learning
Mar 31, 2021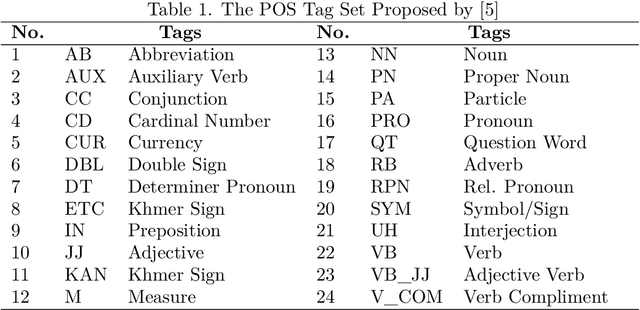
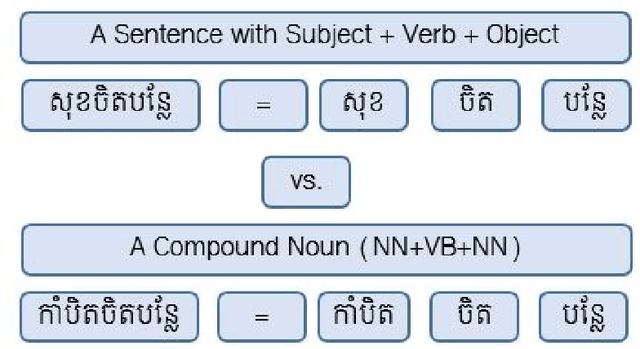
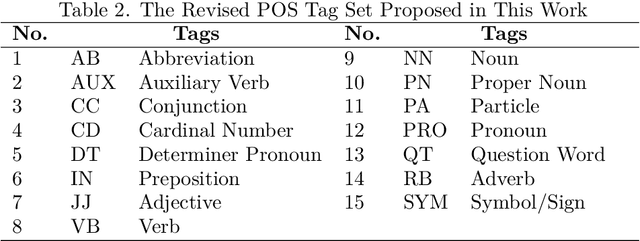
Khmer text is written from left to right with optional space. Space is not served as a word boundary but instead, it is used for readability or other functional purposes. Word segmentation is a prior step for downstream tasks such as part-of-speech (POS) tagging and thus, the robustness of POS tagging highly depends on word segmentation. The conventional Khmer POS tagging is a two-stage process that begins with word segmentation and then actual tagging of each word, afterward. In this work, a joint word segmentation and POS tagging approach using a single deep learning model is proposed so that word segmentation and POS tagging can be performed spontaneously. The proposed model was trained and tested using the publicly available Khmer POS dataset. The validation suggested that the performance of the joint model is on par with the conventional two-stage POS tagging.