 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeRevisit Multimodal Meta-Learning through the Lens of Multi-Task Learning
Oct 27, 2021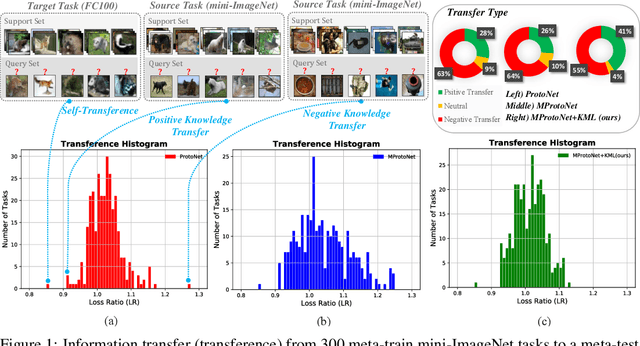
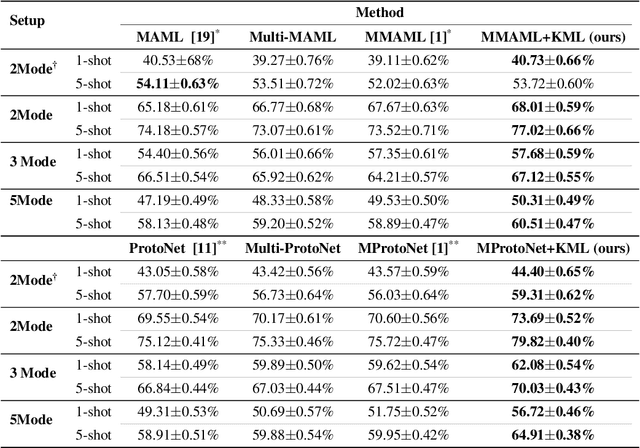
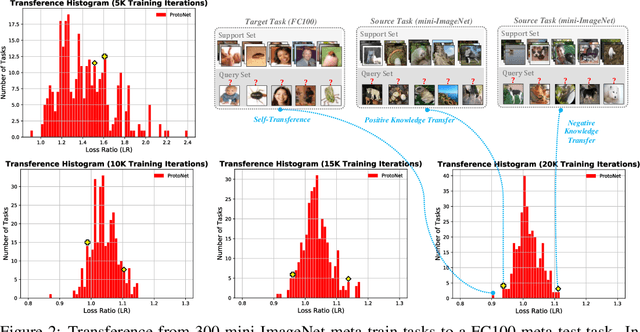
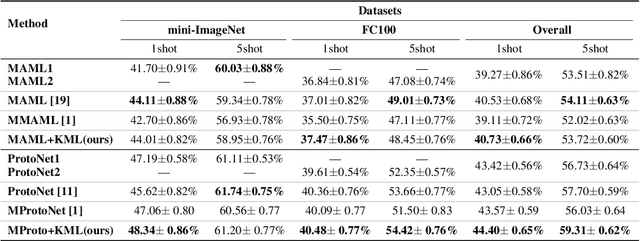
Multimodal meta-learning is a recent problem that extends conventional few-shot meta-learning by generalizing its setup to diverse multimodal task distributions. This setup makes a step towards mimicking how humans make use of a diverse set of prior skills to learn new skills. Previous work has achieved encouraging performance. In particular, in spite of the diversity of the multimodal tasks, previous work claims that a single meta-learner trained on a multimodal distribution can sometimes outperform multiple specialized meta-learners trained on individual unimodal distributions. The improvement is attributed to knowledge transfer between different modes of task distributions. However, there is no deep investigation to verify and understand the knowledge transfer between multimodal tasks. Our work makes two contributions to multimodal meta-learning. First, we propose a method to quantify knowledge transfer between tasks of different modes at a micro-level. Our quantitative, task-level analysis is inspired by the recent transference idea from multi-task learning. Second, inspired by hard parameter sharing in multi-task learning and a new interpretation of related work, we propose a new multimodal meta-learner that outperforms existing work by considerable margins. While the major focus is on multimodal meta-learning, our work also attempts to shed light on task interaction in conventional meta-learning. The code for this project is available at https://miladabd.github.io/KML.
Measuring Fairness in Generative Models
Jul 16, 2021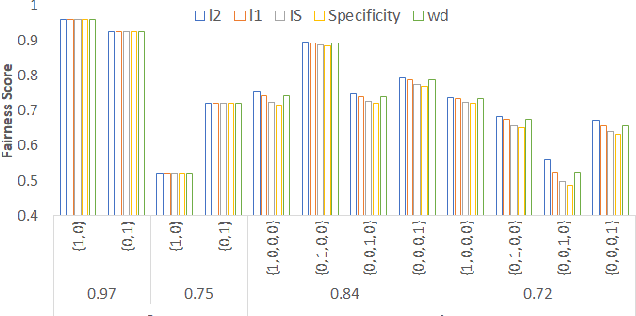
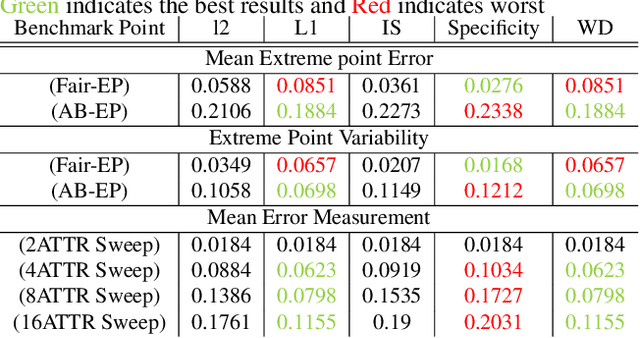
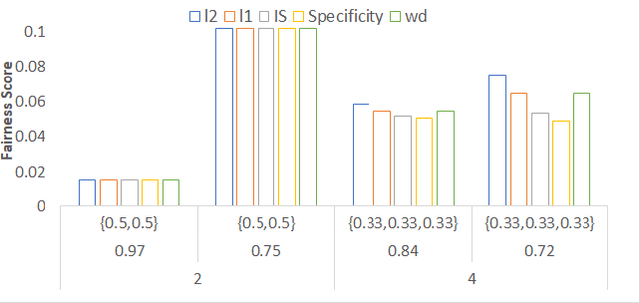
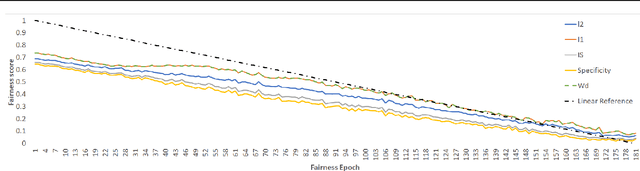
Deep generative models have made much progress in improving training stability and quality of generated data. Recently there has been increased interest in the fairness of deep-generated data. Fairness is important in many applications, e.g. law enforcement, as biases will affect efficacy. Central to fair data generation are the fairness metrics for the assessment and evaluation of different generative models. In this paper, we first review fairness metrics proposed in previous works and highlight potential weaknesses. We then discuss a performance benchmark framework along with the assessment of alternative metrics.
A Closer Look at Fourier Spectrum Discrepancies for CNN-generated Images Detection
Mar 31, 2021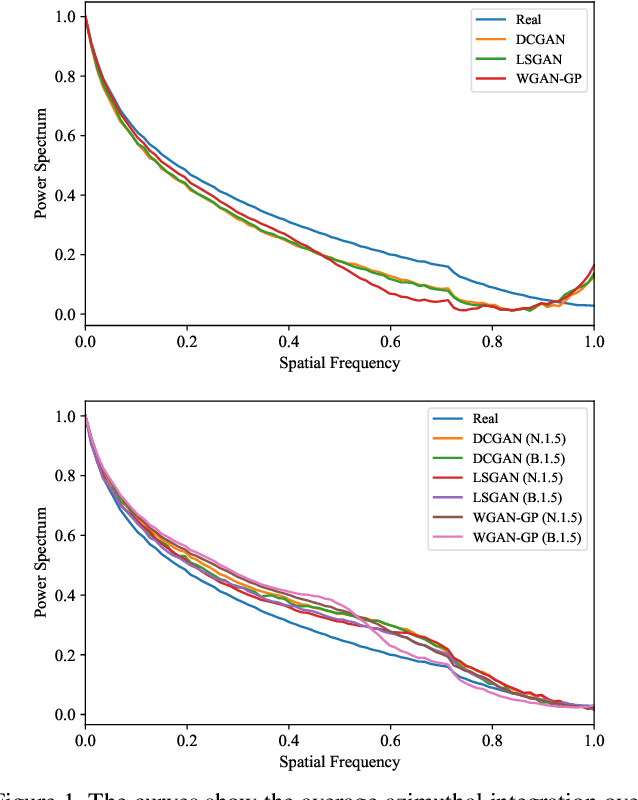
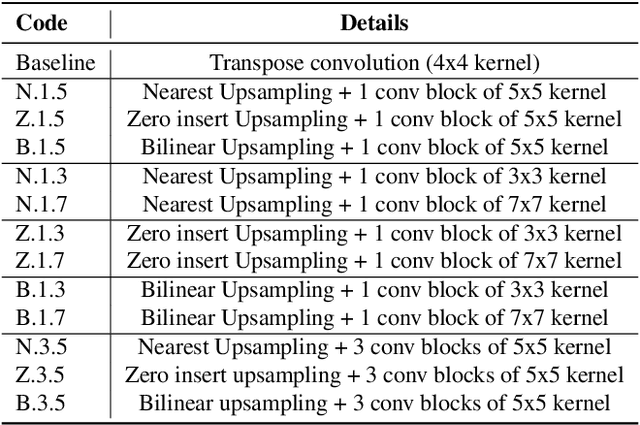
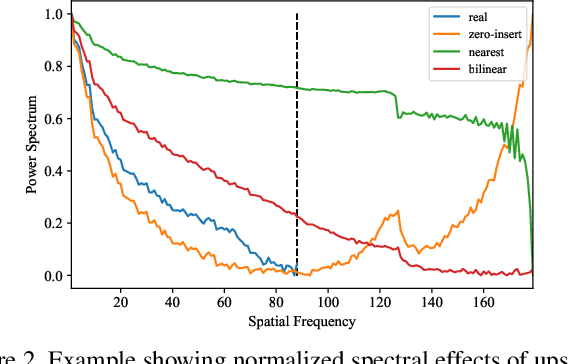
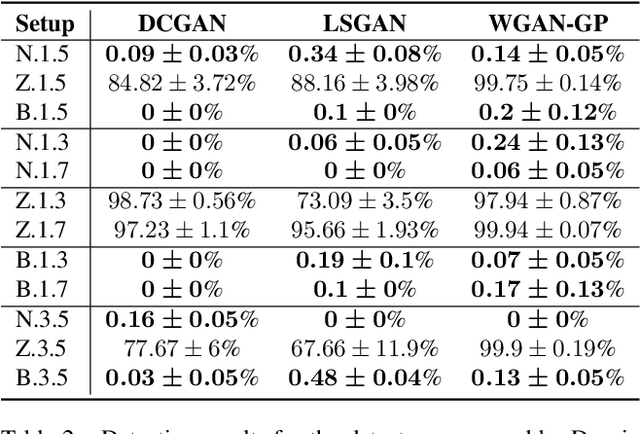
CNN-based generative modelling has evolved to produce synthetic images indistinguishable from real images in the RGB pixel space. Recent works have observed that CNN-generated images share a systematic shortcoming in replicating high frequency Fourier spectrum decay attributes. Furthermore, these works have successfully exploited this systematic shortcoming to detect CNN-generated images reporting up to 99% accuracy across multiple state-of-the-art GAN models. In this work, we investigate the validity of assertions claiming that CNN-generated images are unable to achieve high frequency spectral decay consistency. We meticulously construct a counterexample space of high frequency spectral decay consistent CNN-generated images emerging from our handcrafted experiments using DCGAN, LSGAN, WGAN-GP and StarGAN, where we empirically show that this frequency discrepancy can be avoided by a minor architecture change in the last upsampling operation. We subsequently use images from this counterexample space to successfully bypass the recently proposed forensics detector which leverages on high frequency Fourier spectrum decay attributes for CNN-generated image detection. Through this study, we show that high frequency Fourier spectrum decay discrepancies are not inherent characteristics for existing CNN-based generative models--contrary to the belief of some existing work--, and such features are not robust to perform synthetic image detection. Our results prompt re-thinking of using high frequency Fourier spectrum decay attributes for CNN-generated image detection. Code and models are available at https://keshik6.github.io/Fourier-Discrepancies-CNN-Detection/
Direct Quantization for Training Highly Accurate Low Bit-width Deep Neural Networks
Dec 26, 2020



This paper proposes two novel techniques to train deep convolutional neural networks with low bit-width weights and activations. First, to obtain low bit-width weights, most existing methods obtain the quantized weights by performing quantization on the full-precision network weights. However, this approach would result in some mismatch: the gradient descent updates full-precision weights, but it does not update the quantized weights. To address this issue, we propose a novel method that enables {direct} updating of quantized weights {with learnable quantization levels} to minimize the cost function using gradient descent. Second, to obtain low bit-width activations, existing works consider all channels equally. However, the activation quantizers could be biased toward a few channels with high-variance. To address this issue, we propose a method to take into account the quantization errors of individual channels. With this approach, we can learn activation quantizers that minimize the quantization errors in the majority of channels. Experimental results demonstrate that our proposed method achieves state-of-the-art performance on the image classification task, using AlexNet, ResNet and MobileNetV2 architectures on CIFAR-100 and ImageNet datasets.
Unsupervised Deep Cross-modality Spectral Hashing
Aug 18, 2020


This paper presents a novel framework, namely Deep Cross-modality Spectral Hashing (DCSH), to tackle the unsupervised learning problem of binary hash codes for efficient cross-modal retrieval. The framework is a two-step hashing approach which decouples the optimization into (1) binary optimization and (2) hashing function learning. In the first step, we propose a novel spectral embedding-based algorithm to simultaneously learn single-modality and binary cross-modality representations. While the former is capable of well preserving the local structure of each modality, the latter reveals the hidden patterns from all modalities. In the second step, to learn mapping functions from informative data inputs (images and word embeddings) to binary codes obtained from the first step, we leverage the powerful CNN for images and propose a CNN-based deep architecture to learn text modality. Quantitative evaluations on three standard benchmark datasets demonstrate that the proposed DCSH method consistently outperforms other state-of-the-art methods.
Explanation-Guided Training for Cross-Domain Few-Shot Classification
Jul 17, 2020
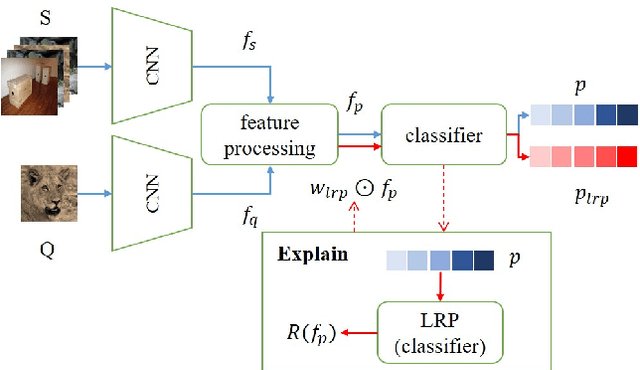
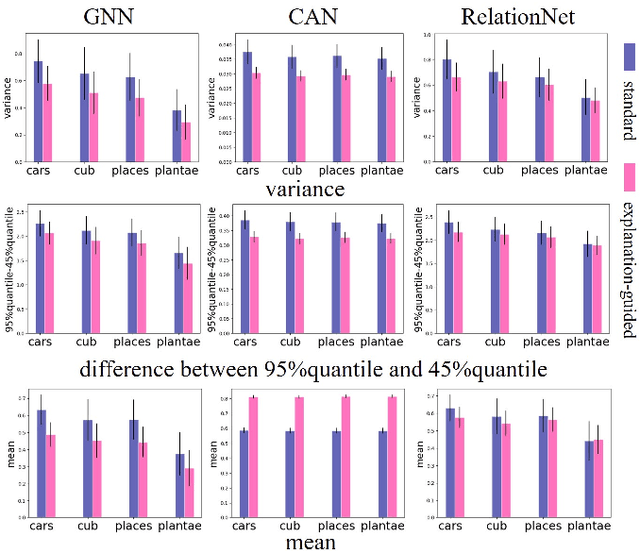
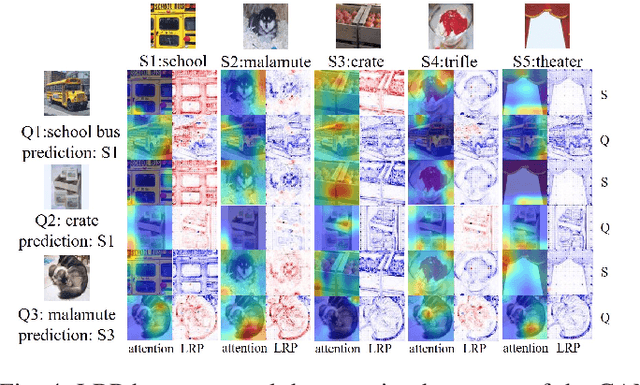
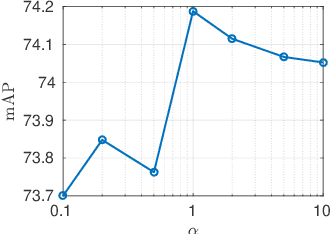
Cross-domain few-shot classification task (CD-FSC) combines few-shot classification with the requirement to generalize across domains represented by datasets. This setup faces challenges originating from the limited labeled data in each class and, additionally, from the domain shift between training and test sets. In this paper, we introduce a novel training approach for existing FSC models. It leverages on the explanation scores, obtained from existing explanation methods when applied to the predictions of FSC models, computed for intermediate feature maps of the models. Firstly, we tailor the layer-wise relevance propagation (LRP) method to explain the prediction outcomes of FSC models. Secondly, we develop a model-agnostic explanation-guided training strategy that dynamically finds and emphasizes the features which are important for the predictions. Our contribution does not target a novel explanation method but lies in a novel application of explanations for the training phase. We show that explanation-guided training effectively improves the model generalization. We observe improved accuracy for three different FSC models: RelationNet, cross attention network, and a graph neural network-based formulation, on five few-shot learning datasets: miniImagenet, CUB, Cars, Places, and Plantae.
InfoMax-GAN: Improved Adversarial Image Generation via Information Maximization and Contrastive Learning
Jul 09, 2020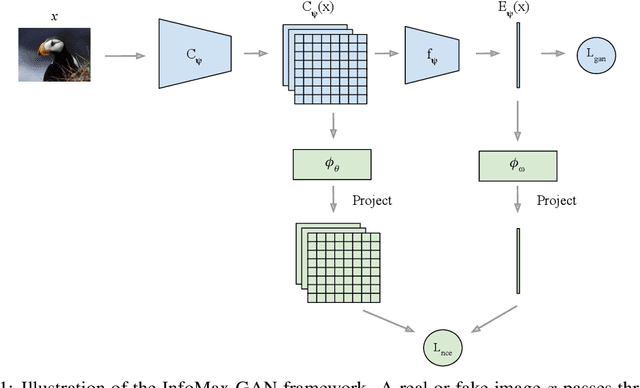
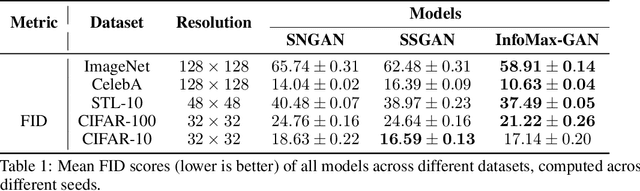
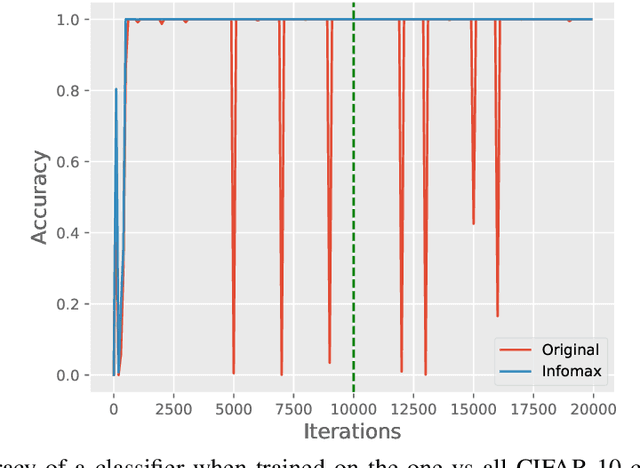
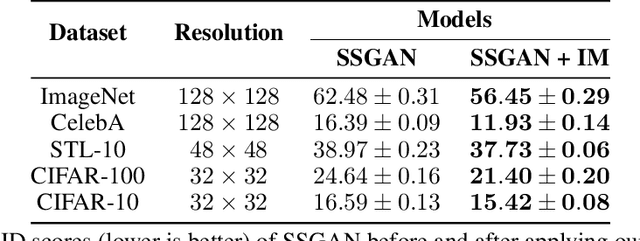
While Generative Adversarial Networks (GANs) are fundamental to many generative modelling applications, they suffer from numerous issues. In this work, we propose a principled framework to simultaneously address two fundamental issues in GANs: catastrophic forgetting of the discriminator and mode collapse of the generator. We achieve this by employing for GANs a contrastive learning and mutual information maximization approach, and perform extensive analyses to understand sources of improvements. Our approach significantly stabilises GAN training and improves GAN performance for image synthesis across five datasets under the same training and evaluation conditions against state-of-the-art works. Our approach is simple to implement and practical: it involves only one objective, is computationally inexpensive, and is robust across a wide range of hyperparameters without any tuning. For reproducibility, our code is available at https://github.com/kwotsin/mimicry.
Towards Good Practices for Data Augmentation in GAN Training
Jun 09, 2020


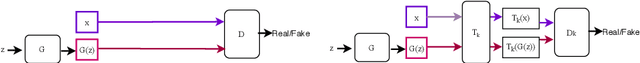
Recent successes in Generative Adversarial Networks (GAN) have affirmed the importance of using more data in GAN training. Yet it is expensive to collect data in many domains such as medical applications. Data Augmentation (DA) has been applied in these applications. In this work, we first argue that the classical DA approach could mislead the generator to learn the distribution of the augmented data, which could be different from that of the original data. We then propose a principled framework, termed Data Augmentation Optimized for GAN (DAG), to enable the use of augmented data in GAN training to improve the learning of the original distribution. We provide theoretical analysis to show that using our proposed DAG aligns with the original GAN in minimizing the JS divergence w.r.t. the original distribution and it leverages the augmented data to improve the learnings of discriminator and generator. The experiments show that DAG improves various GAN models. Furthermore, when DAG is used in some GAN models, the system establishes state-of-the-art Fr\'echet Inception Distance (FID) scores.
Self-supervised GAN: Analysis and Improvement with Multi-class Minimax Game
Nov 16, 2019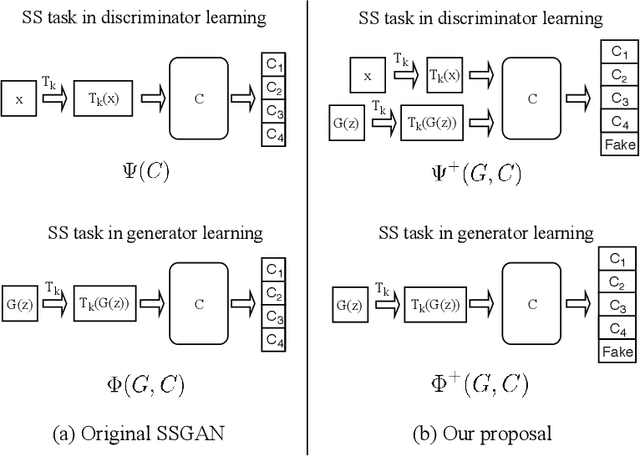
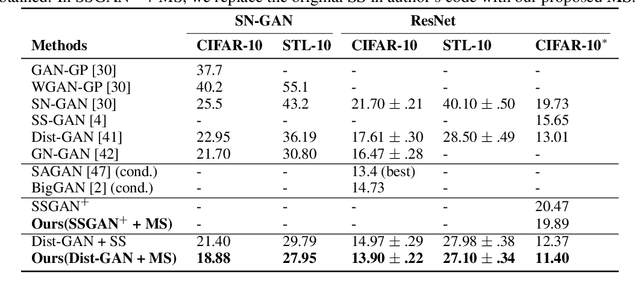


Self-supervised (SS) learning is a powerful approach for representation learning using unlabeled data. Recently, it has been applied to Generative Adversarial Networks (GAN) training. Specifically, SS tasks were proposed to address the catastrophic forgetting issue in the GAN discriminator. In this work, we perform an in-depth analysis to understand how SS tasks interact with learning of generator. From the analysis, we identify issues of SS tasks which allow a severely mode-collapsed generator to excel the SS tasks. To address the issues, we propose new SS tasks based on a multi-class minimax game. The competition between our proposed SS tasks in the game encourages the generator to learn the data distribution and generate diverse samples. We provide both theoretical and empirical analysis to support that our proposed SS tasks have better convergence property. We conduct experiments to incorporate our proposed SS tasks into two different GAN baseline models. Our approach establishes state-of-the-art FID scores on CIFAR-10, CIFAR-100, STL-10, CelebA, Imagenet $32\times32$ and Stacked-MNIST datasets, outperforming existing works by considerable margins in some cases. Our unconditional GAN model approaches performance of conditional GAN without using labeled data. Our code: \url{https://github.com/tntrung/msgan}
TEAGS: Time-aware Text Embedding Approach to Generate Subgraphs
Aug 21, 2019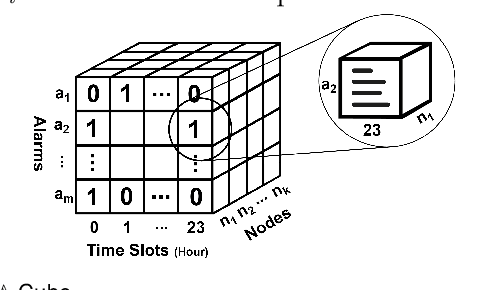
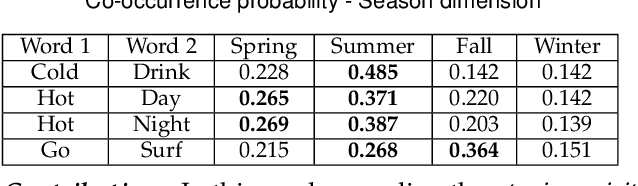
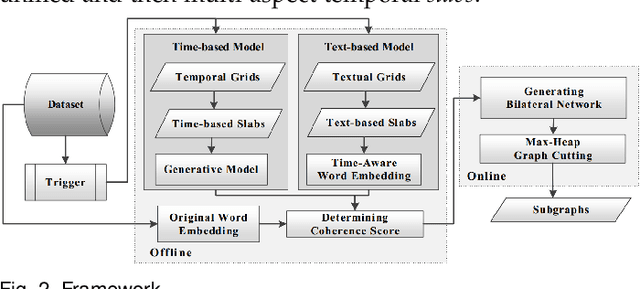
Contagions (e.g. virus, gossip) spread over the nodes in propagation graphs. We can use the temporal and textual data of the nodes to compute the edge weights and then generate subgraphs with highly relevant nodes. This is beneficial to many applications. Yet, challenges abound. First, the propagation pattern between each pair of nodes may change by time. Second, not always the same contagion propagates. Hence, the state-of-the-art text mining approaches including topic-modeling cannot effectively compute the edge weights. Third, since the propagation is affected by time, the word-word co-occurrence patterns may differ in various temporal dimensions, that can decrease the effectiveness of word embedding approaches. We argue that multi-aspect temporal dimensions (hour, day, etc) should be considered to better calculate the correlation weights between the nodes. In this work, we devise a novel framework that on the one hand, integrates a neural network based time-aware word embedding component to construct the word vectors through multiple temporal facets, and on the other hand, uses a temporal generative model to compute the weights. Subsequently, we propose a Max-Heap Graph cutting algorithm to generate subgraphs. We validate our model through comprehensive experiments on real-world datasets. The results show that our model can retrieve the subgraphs more effective than other rivals and the temporal dynamics should be noticed both in word embedding and propagation processes.