 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeDeepStack: Expert-Level Artificial Intelligence in No-Limit Poker
Mar 03, 2017Artificial intelligence has seen several breakthroughs in recent years, with games often serving as milestones. A common feature of these games is that players have perfect information. Poker is the quintessential game of imperfect information, and a longstanding challenge problem in artificial intelligence. We introduce DeepStack, an algorithm for imperfect information settings. It combines recursive reasoning to handle information asymmetry, decomposition to focus computation on the relevant decision, and a form of intuition that is automatically learned from self-play using deep learning. In a study involving 44,000 hands of poker, DeepStack defeated with statistical significance professional poker players in heads-up no-limit Texas hold'em. The approach is theoretically sound and is shown to produce more difficult to exploit strategies than prior approaches.
AIVAT: A New Variance Reduction Technique for Agent Evaluation in Imperfect Information Games
Jan 19, 2017



Evaluating agent performance when outcomes are stochastic and agents use randomized strategies can be challenging when there is limited data available. The variance of sampled outcomes may make the simple approach of Monte Carlo sampling inadequate. This is the case for agents playing heads-up no-limit Texas hold'em poker, where man-machine competitions have involved multiple days of consistent play and still not resulted in statistically significant conclusions even when the winner's margin is substantial. In this paper, we introduce AIVAT, a low variance, provably unbiased value assessment tool that uses an arbitrary heuristic estimate of state value, as well as the explicit strategy of a subset of the agents. Unlike existing techniques which reduce the variance from chance events, or only consider game ending actions, AIVAT reduces the variance both from choices by nature and by players with a known strategy. The resulting estimator in no-limit poker can reduce the number of hands needed to draw statistical conclusions by more than a factor of 10.
Predicting the Performance of IDA* using Conditional Distributions
Jan 15, 2014
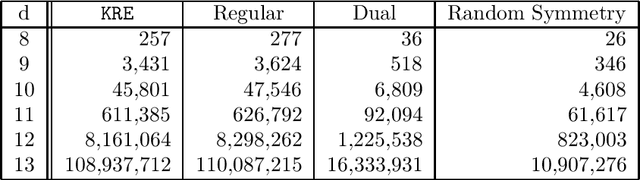
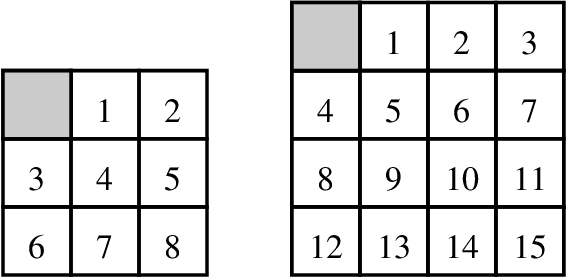
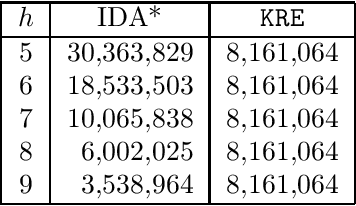
Korf, Reid, and Edelkamp introduced a formula to predict the number of nodes IDA* will expand on a single iteration for a given consistent heuristic, and experimentally demonstrated that it could make very accurate predictions. In this paper we show that, in addition to requiring the heuristic to be consistent, their formulas predictions are accurate only at levels of the brute-force search tree where the heuristic values obey the unconditional distribution that they defined and then used in their formula. We then propose a new formula that works well without these requirements, i.e., it can make accurate predictions of IDA*s performance for inconsistent heuristics and if the heuristic values in any level do not obey the unconditional distribution. In order to achieve this we introduce the conditional distribution of heuristic values which is a generalization of their unconditional heuristic distribution. We also provide extensions of our formula that handle individual start states and the augmentation of IDA* with bidirectional pathmax (BPMX), a technique for propagating heuristic values when inconsistent heuristics are used. Experimental results demonstrate the accuracy of our new method and all its variations.
Bayes' Bluff: Opponent Modelling in Poker
Jul 04, 2012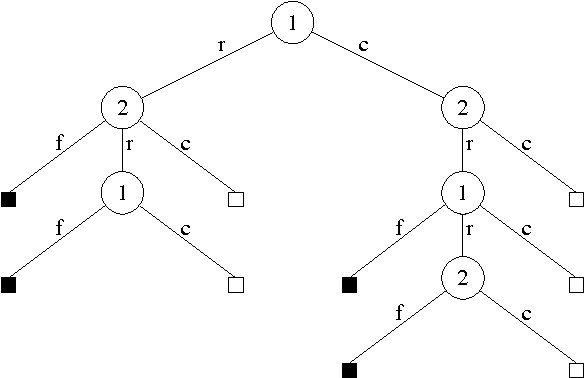
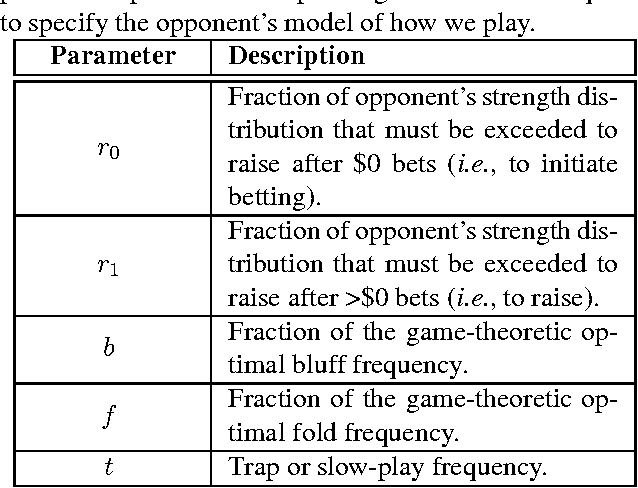
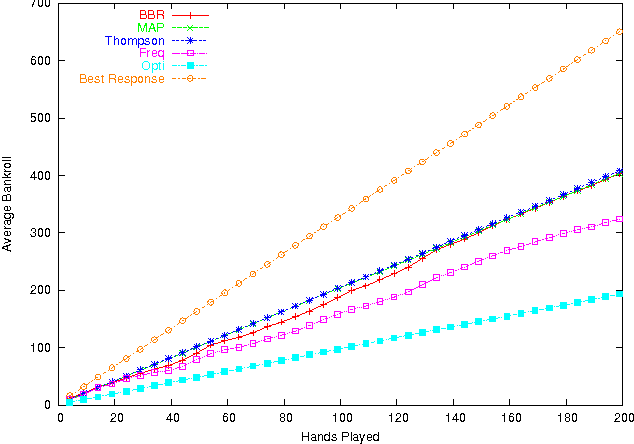
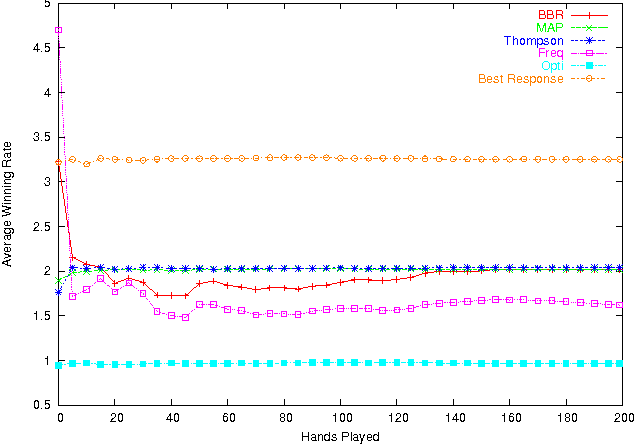
Poker is a challenging problem for artificial intelligence, with non-deterministic dynamics, partial observability, and the added difficulty of unknown adversaries. Modelling all of the uncertainties in this domain is not an easy task. In this paper we present a Bayesian probabilistic model for a broad class of poker games, separating the uncertainty in the game dynamics from the uncertainty of the opponent's strategy. We then describe approaches to two key subproblems: (i) inferring a posterior over opponent strategies given a prior distribution and observations of their play, and (ii) playing an appropriate response to that distribution. We demonstrate the overall approach on a reduced version of poker using Dirichlet priors and then on the full game of Texas hold'em using a more informed prior. We demonstrate methods for playing effective responses to the opponent, based on the posterior.
No-Regret Learning in Extensive-Form Games with Imperfect Recall
May 03, 2012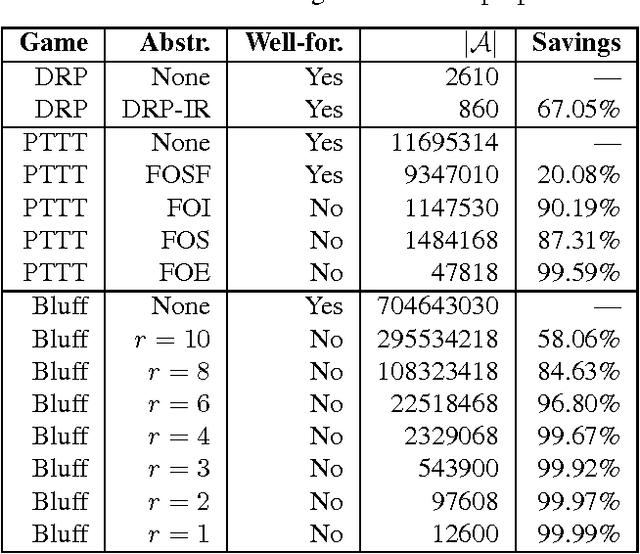
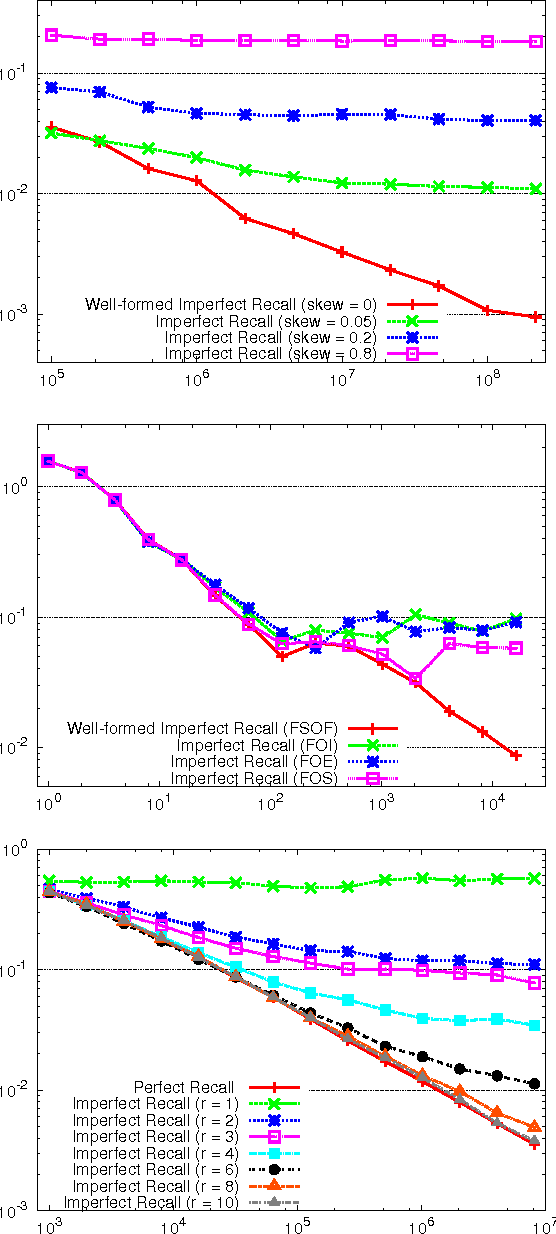
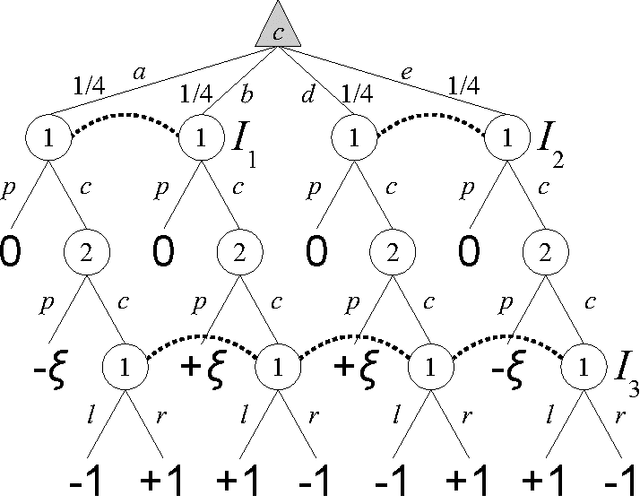
Counterfactual Regret Minimization (CFR) is an efficient no-regret learning algorithm for decision problems modeled as extensive games. CFR's regret bounds depend on the requirement of perfect recall: players always remember information that was revealed to them and the order in which it was revealed. In games without perfect recall, however, CFR's guarantees do not apply. In this paper, we present the first regret bound for CFR when applied to a general class of games with imperfect recall. In addition, we show that CFR applied to any abstraction belonging to our general class results in a regret bound not just for the abstract game, but for the full game as well. We verify our theory and show how imperfect recall can be used to trade a small increase in regret for a significant reduction in memory in three domains: die-roll poker, phantom tic-tac-toe, and Bluff.