 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeCataractSAM-2: A Domain-Adapted Model for Anterior Segment Surgery Segmentation and Scalable Ground-Truth Annotation
Mar 23, 2026We present CataractSAM-2, a domain-adapted extension of Meta's Segment Anything Model 2, designed for real-time semantic segmentation of cataract ophthalmic surgery videos with high accuracy. Positioned at the intersection of computer vision and medical robotics, CataractSAM-2 enables precise intraoperative perception crucial for robotic-assisted and computer-guided surgical systems. Furthermore, to alleviate the burden of manual labeling, we introduce an interactive annotation framework that combines sparse prompts with video-based mask propagation. This tool significantly reduces annotation time and facilitates the scalable creation of high-quality ground-truth masks, accelerating dataset development for ocular anterior segment surgeries. We also demonstrate the model's strong zero-shot generalization to glaucoma trabeculectomy procedures, confirming its cross-procedural utility and potential for broader surgical applications. The trained model and annotation toolkit are released as open-source resources, establishing CataractSAM-2 as a foundation for expanding anterior ophthalmic surgical datasets and advancing real-time AI-driven solutions in medical robotics, as well as surgical video understanding.
Artifact-Tolerant Clustering-Guided Contrastive Embedding Learning for Ophthalmic Images
Sep 02, 2022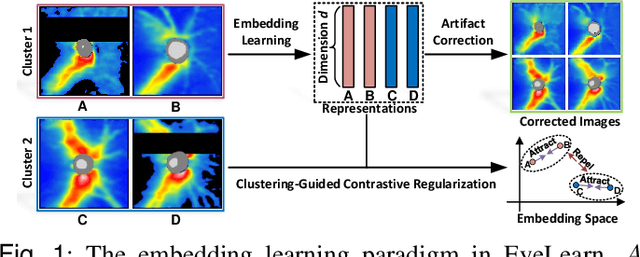
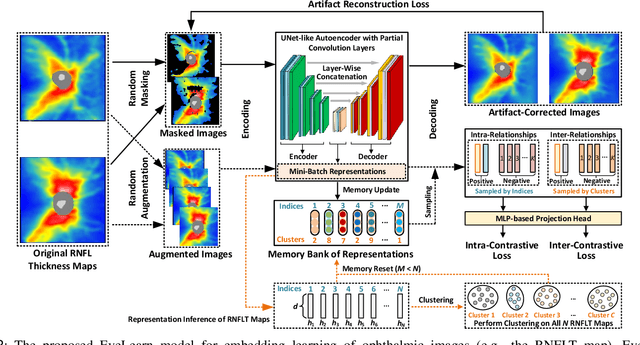
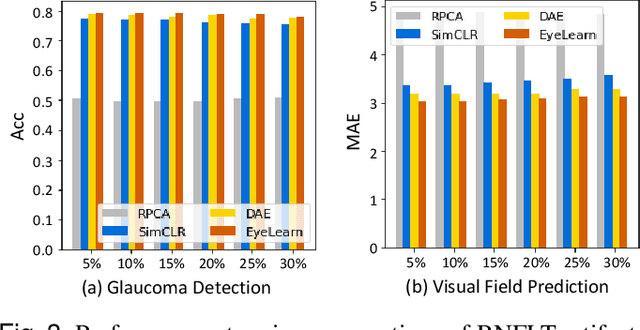
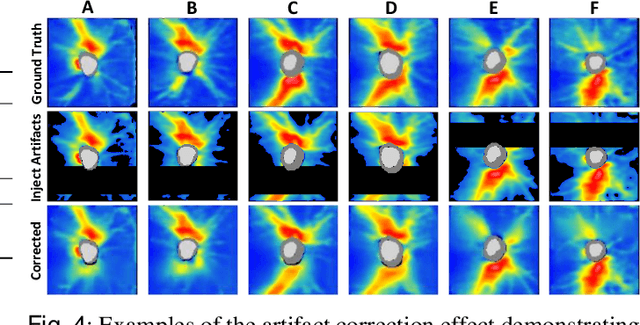
Ophthalmic images and derivatives such as the retinal nerve fiber layer (RNFL) thickness map are crucial for detecting and monitoring ophthalmic diseases (e.g., glaucoma). For computer-aided diagnosis of eye diseases, the key technique is to automatically extract meaningful features from ophthalmic images that can reveal the biomarkers (e.g., RNFL thinning patterns) linked to functional vision loss. However, representation learning from ophthalmic images that links structural retinal damage with human vision loss is non-trivial mostly due to large anatomical variations between patients. The task becomes even more challenging in the presence of image artifacts, which are common due to issues with image acquisition and automated segmentation. In this paper, we propose an artifact-tolerant unsupervised learning framework termed EyeLearn for learning representations of ophthalmic images. EyeLearn has an artifact correction module to learn representations that can best predict artifact-free ophthalmic images. In addition, EyeLearn adopts a clustering-guided contrastive learning strategy to explicitly capture the intra- and inter-image affinities. During training, images are dynamically organized in clusters to form contrastive samples in which images in the same or different clusters are encouraged to learn similar or dissimilar representations, respectively. To evaluate EyeLearn, we use the learned representations for visual field prediction and glaucoma detection using a real-world ophthalmic image dataset of glaucoma patients. Extensive experiments and comparisons with state-of-the-art methods verified the effectiveness of EyeLearn for learning optimal feature representations from ophthalmic images.
Affective Medical Estimation and Decision Making via Visualized Learning and Deep Learning
May 09, 2022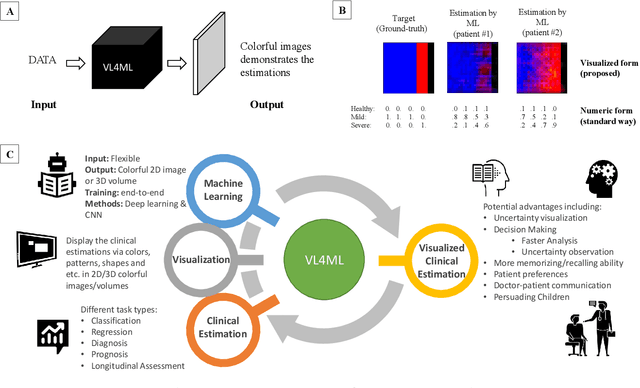
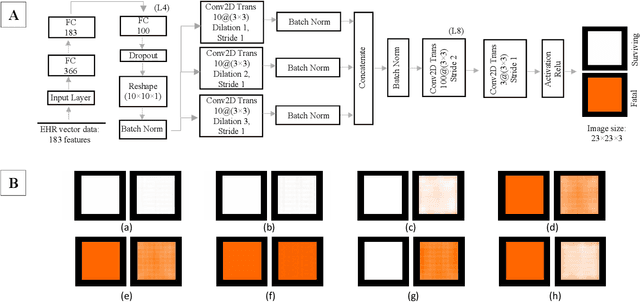
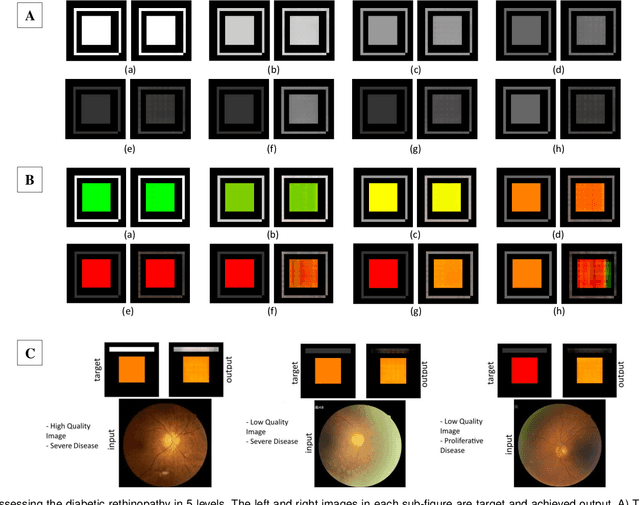
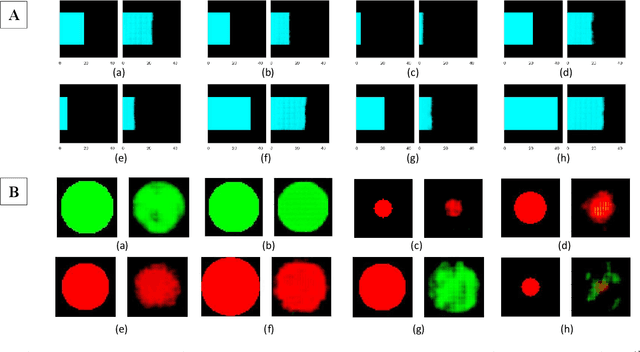
With the advent of sophisticated machine learning (ML) techniques and the promising results they yield, especially in medical applications, where they have been investigated for different tasks to enhance the decision-making process. Since visualization is such an effective tool for human comprehension, memorization, and judgment, we have presented a first-of-its-kind estimation approach we refer to as Visualized Learning for Machine Learning (VL4ML) that not only can serve to assist physicians and clinicians in making reasoned medical decisions, but it also allows to appreciate the uncertainty visualization, which could raise incertitude in making the appropriate classification or prediction. For the proof of concept, and to demonstrate the generalized nature of this visualized estimation approach, five different case studies are examined for different types of tasks including classification, regression, and longitudinal prediction. A survey analysis with more than 100 individuals is also conducted to assess users' feedback on this visualized estimation method. The experiments and the survey demonstrate the practical merits of the VL4ML that include: (1) appreciating visually clinical/medical estimations; (2) getting closer to the patients' preferences; (3) improving doctor-patient communication, and (4) visualizing the uncertainty introduced through the black box effect of the deployed ML algorithm. All the source codes are shared via a GitHub repository.