 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeDeep Neural Approaches to Relation Triplets Extraction: A Comprehensive Survey
Mar 31, 2021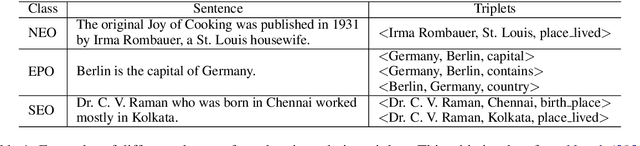
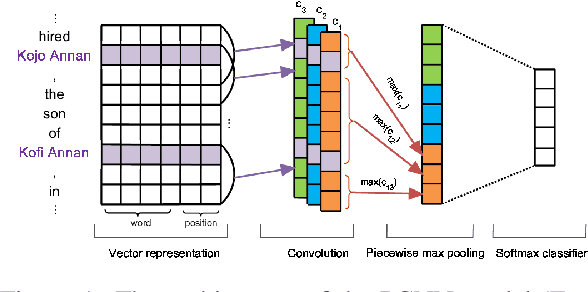
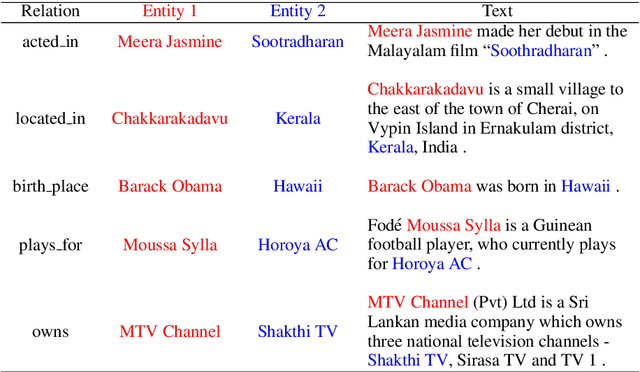
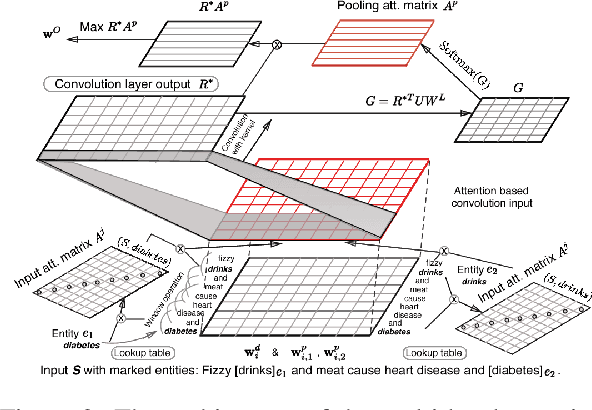
Recently, with the advances made in continuous representation of words (word embeddings) and deep neural architectures, many research works are published in the area of relation extraction and it is very difficult to keep track of so many papers. To help future research, we present a comprehensive review of the recently published research works in relation extraction. We mostly focus on relation extraction using deep neural networks which have achieved state-of-the-art performance on publicly available datasets. In this survey, we cover sentence-level relation extraction to document-level relation extraction, pipeline-based approaches to joint extraction approaches, annotated datasets to distantly supervised datasets along with few very recent research directions such as zero-shot or few-shot relation extraction, noise mitigation in distantly supervised datasets. Regarding neural architectures, we cover convolutional models, recurrent network models, attention network models, and graph convolutional models in this survey.
Recognizing Emotion Cause in Conversations
Dec 24, 2020
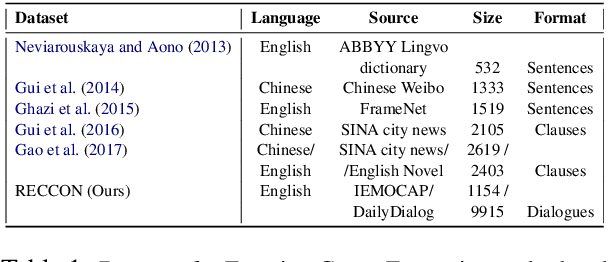
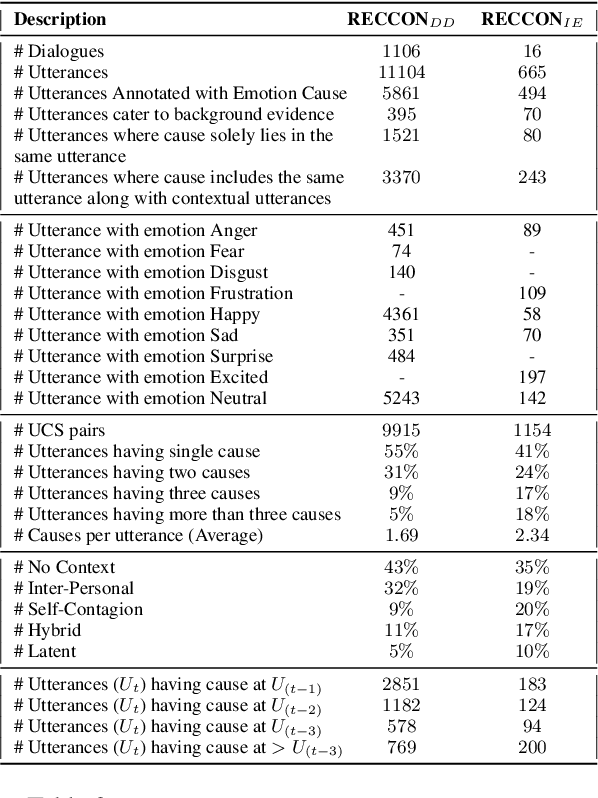

Recognizing the cause behind emotions in text is a fundamental yet under-explored area of research in NLP. Advances in this area hold the potential to improve interpretability and performance in affect-based models. Identifying emotion causes at the utterance level in conversations is particularly challenging due to the intermingling dynamic among the interlocutors. To this end, we introduce the task of recognizing emotion cause in conversations with an accompanying dataset named RECCON. Furthermore, we define different cause types based on the source of the causes and establish strong transformer-based baselines to address two different sub-tasks of RECCON: 1) Causal Span Extraction and 2) Causal Emotion Entailment. The dataset is available at https://github.com/declare-lab/RECCON.
Improving Zero Shot Learning Baselines with Commonsense Knowledge
Dec 11, 2020

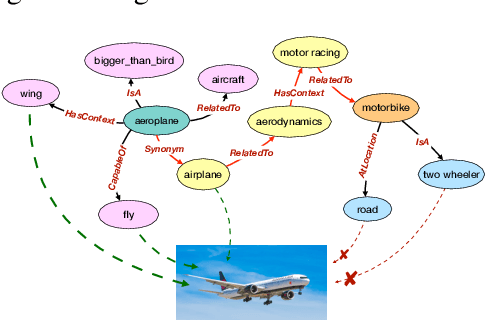

Zero shot learning -- the problem of training and testing on a completely disjoint set of classes -- relies greatly on its ability to transfer knowledge from train classes to test classes. Traditionally semantic embeddings consisting of human defined attributes (HA) or distributed word embeddings (DWE) are used to facilitate this transfer by improving the association between visual and semantic embeddings. In this paper, we take advantage of explicit relations between nodes defined in ConceptNet, a commonsense knowledge graph, to generate commonsense embeddings of the class labels by using a graph convolution network-based autoencoder. Our experiments performed on three standard benchmark datasets surpass the strong baselines when we fuse our commonsense embeddings with existing semantic embeddings i.e. HA and DWE.
Persuasive Dialogue Understanding: the Baselines and Negative Results
Nov 22, 2020
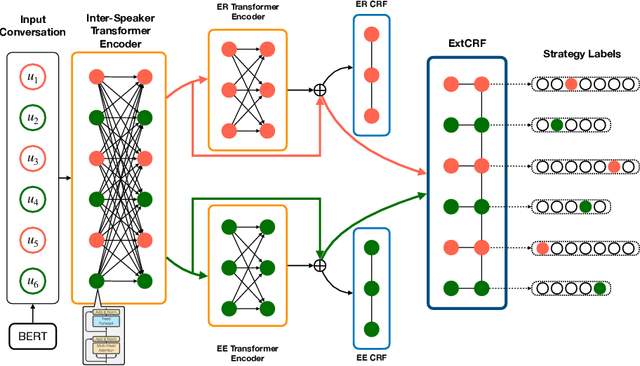
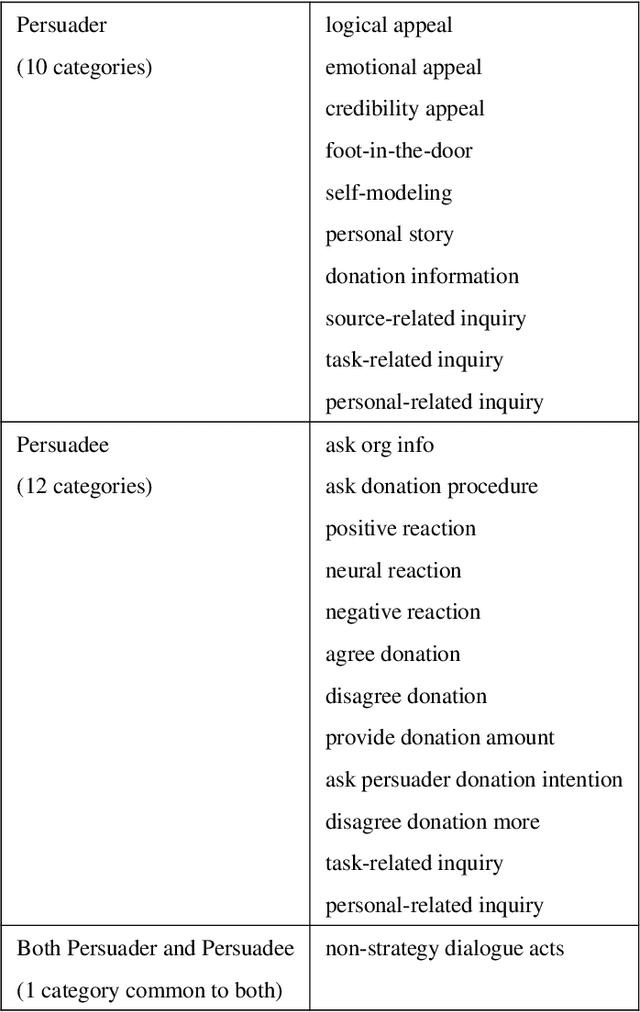
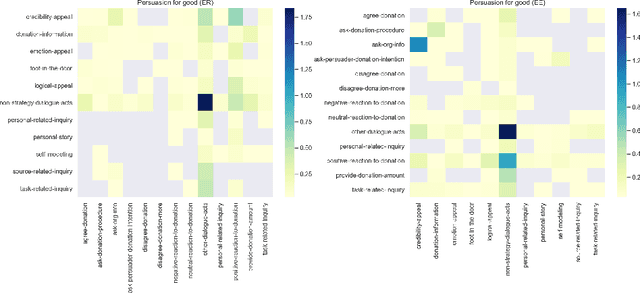
Persuasion aims at forming one's opinion and action via a series of persuasive messages containing persuader's strategies. Due to its potential application in persuasive dialogue systems, the task of persuasive strategy recognition has gained much attention lately. Previous methods on user intent recognition in dialogue systems adopt recurrent neural network (RNN) or convolutional neural network (CNN) to model context in conversational history, neglecting the tactic history and intra-speaker relation. In this paper, we demonstrate the limitations of a Transformer-based approach coupled with Conditional Random Field (CRF) for the task of persuasive strategy recognition. In this model, we leverage inter- and intra-speaker contextual semantic features, as well as label dependencies to improve the recognition. Despite extensive hyper-parameter optimizations, this architecture fails to outperform the baseline methods. We observe two negative results. Firstly, CRF cannot capture persuasive label dependencies, possibly as strategies in persuasive dialogues do not follow any strict grammar or rules as the cases in Named Entity Recognition (NER) or part-of-speech (POS) tagging. Secondly, the Transformer encoder trained from scratch is less capable of capturing sequential information in persuasive dialogues than Long Short-Term Memory (LSTM). We attribute this to the reason that the vanilla Transformer encoder does not efficiently consider relative position information of sequence elements.
Utterance-level Dialogue Understanding: An Empirical Study
Oct 22, 2020
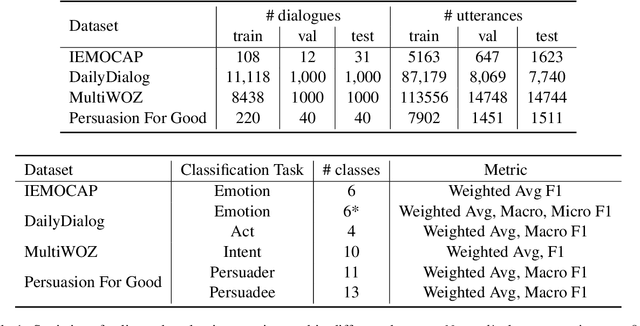
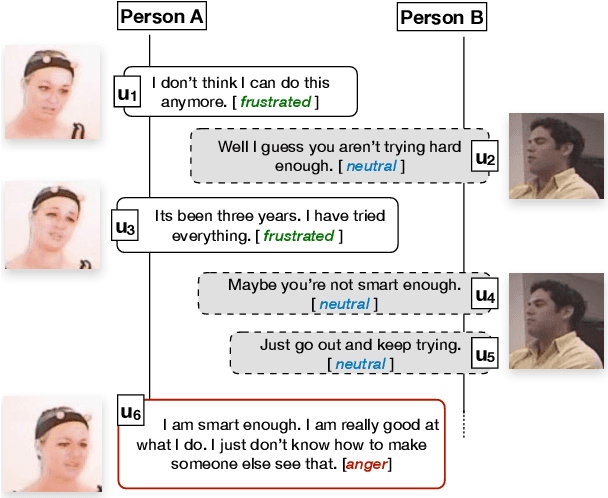

The recent abundance of conversational data on the Web and elsewhere calls for effective NLP systems for dialog understanding. Complete utterance-level understanding often requires context understanding, defined by nearby utterances. In recent years, a number of approaches have been proposed for various utterance-level dialogue understanding tasks. Most of these approaches account for the context for effective understanding. In this paper, we explore and quantify the role of context for different aspects of a dialogue, namely emotion, intent, and dialogue act identification, using state-of-the-art dialog understanding methods as baselines. Specifically, we employ various perturbations to distort the context of a given utterance and study its impact on the different tasks and baselines. This provides us with insights into the fundamental contextual controlling factors of different aspects of a dialogue. Such insights can inspire more effective dialogue understanding models, and provide support for future text generation approaches. The implementation pertaining to this work is available at https://github.com/declare-lab/dialogue-understanding.
COSMIC: COmmonSense knowledge for eMotion Identification in Conversations
Oct 06, 2020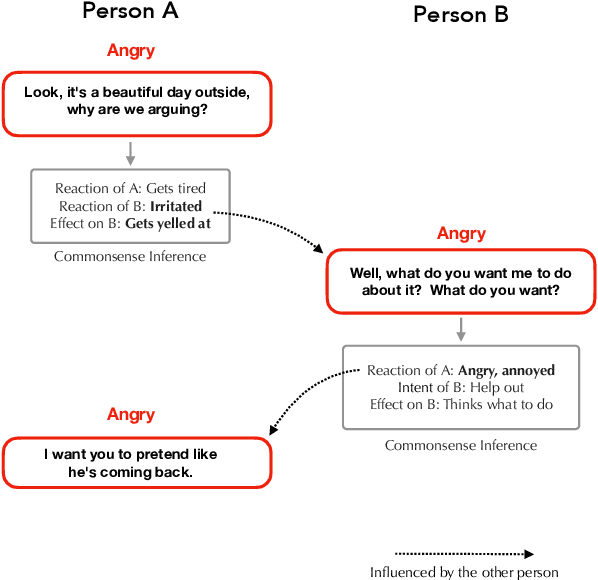
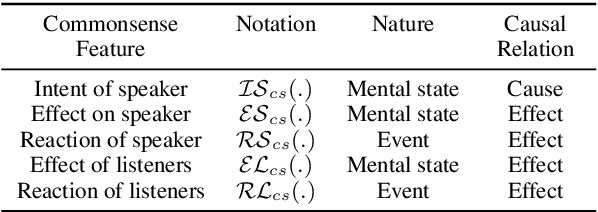
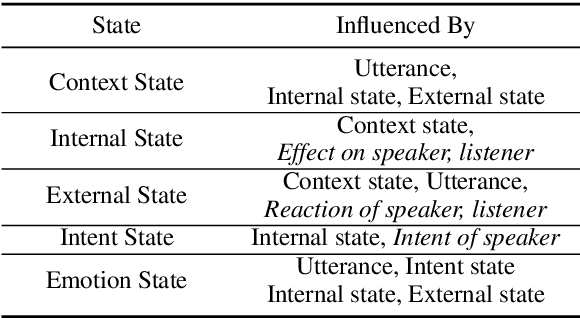
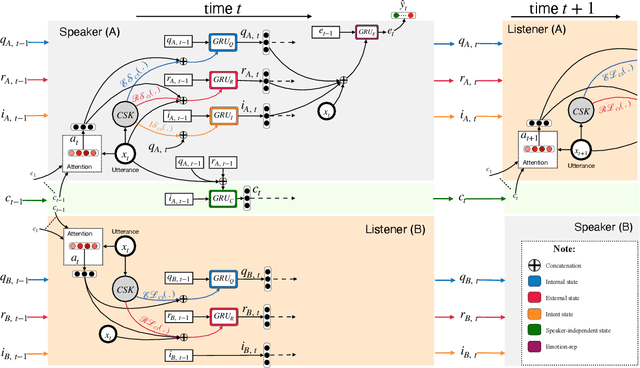
In this paper, we address the task of utterance level emotion recognition in conversations using commonsense knowledge. We propose COSMIC, a new framework that incorporates different elements of commonsense such as mental states, events, and causal relations, and build upon them to learn interactions between interlocutors participating in a conversation. Current state-of-the-art methods often encounter difficulties in context propagation, emotion shift detection, and differentiating between related emotion classes. By learning distinct commonsense representations, COSMIC addresses these challenges and achieves new state-of-the-art results for emotion recognition on four different benchmark conversational datasets. Our code is available at https://github.com/declare-lab/conv-emotion.
MIME: MIMicking Emotions for Empathetic Response Generation
Oct 04, 2020

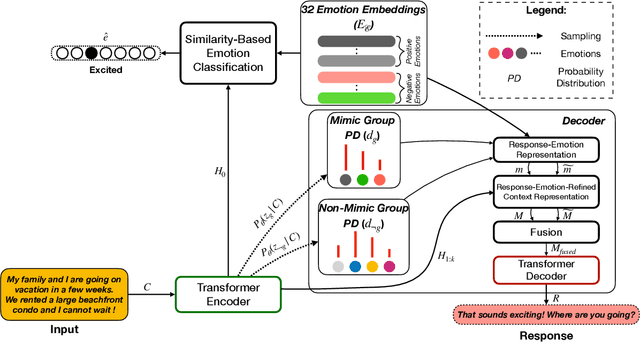
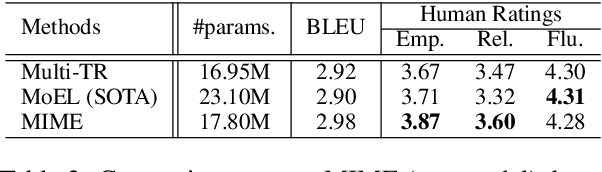
Current approaches to empathetic response generation view the set of emotions expressed in the input text as a flat structure, where all the emotions are treated uniformly. We argue that empathetic responses often mimic the emotion of the user to a varying degree, depending on its positivity or negativity and content. We show that the consideration of this polarity-based emotion clusters and emotional mimicry results in improved empathy and contextual relevance of the response as compared to the state-of-the-art. Also, we introduce stochasticity into the emotion mixture that yields emotionally more varied empathetic responses than the previous work. We demonstrate the importance of these factors to empathetic response generation using both automatic- and human-based evaluations. The implementation of MIME is publicly available at https://github.com/declare-lab/MIME.
Dialogue Relation Extraction with Document-level Heterogeneous Graph Attention Networks
Sep 14, 2020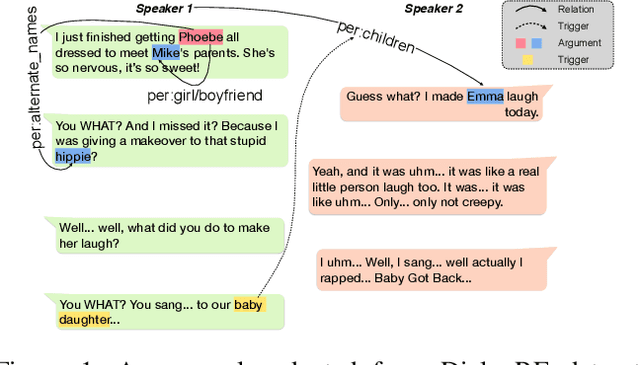

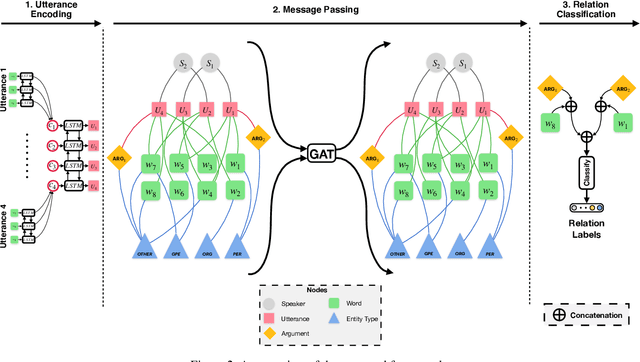

Dialogue relation extraction (DRE) aims to detect the relation between two entities mentioned in a multi-party dialogue. It plays an important role in constructing knowledge graphs from conversational data increasingly abundant on the internet and facilitating intelligent dialogue system development. The prior methods of DRE do not meaningfully leverage speaker information-they just prepend the utterances with the respective speaker names. Thus, they fail to model the crucial inter-speaker relations that may give additional context to relevant argument entities through pronouns and triggers. We, however, present a graph attention network-based method for DRE where a graph, that contains meaningfully connected speaker, entity, entity-type, and utterance nodes, is constructed. This graph is fed to a graph attention network for context propagation among relevant nodes, which effectively captures the dialogue context. We empirically show that this graph-based approach quite effectively captures the relations between different entity pairs in a dialogue as it outperforms the state-of-the-art approaches by a significant margin on the benchmark dataset DialogRE. Our code is released at: https://github.com/declare-lab/dialog-HGAT
Investigating Gender Bias in BERT
Sep 10, 2020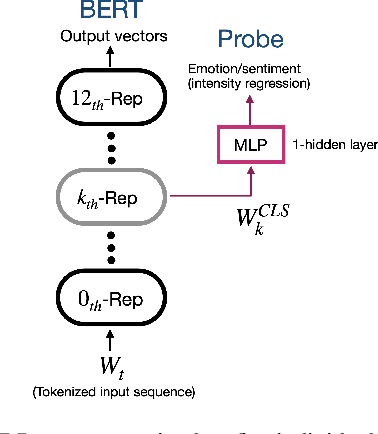

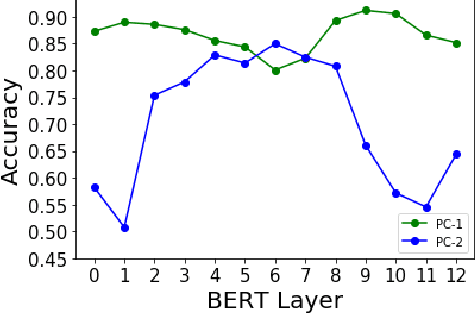

Contextual language models (CLMs) have pushed the NLP benchmarks to a new height. It has become a new norm to utilize CLM provided word embeddings in downstream tasks such as text classification. However, unless addressed, CLMs are prone to learn intrinsic gender-bias in the dataset. As a result, predictions of downstream NLP models can vary noticeably by varying gender words, such as replacing "he" to "she", or even gender-neutral words. In this paper, we focus our analysis on a popular CLM, i.e., BERT. We analyse the gender-bias it induces in five downstream tasks related to emotion and sentiment intensity prediction. For each task, we train a simple regressor utilizing BERT's word embeddings. We then evaluate the gender-bias in regressors using an equity evaluation corpus. Ideally and from the specific design, the models should discard gender informative features from the input. However, the results show a significant dependence of the system's predictions on gender-particular words and phrases. We claim that such biases can be reduced by removing genderspecific features from word embedding. Hence, for each layer in BERT, we identify directions that primarily encode gender information. The space formed by such directions is referred to as the gender subspace in the semantic space of word embeddings. We propose an algorithm that finds fine-grained gender directions, i.e., one primary direction for each BERT layer. This obviates the need of realizing gender subspace in multiple dimensions and prevents other crucial information from being omitted. Experiments show that removing embedding components in such directions achieves great success in reducing BERT-induced bias in the downstream tasks.
KinGDOM: Knowledge-Guided DOMain adaptation for sentiment analysis
May 11, 2020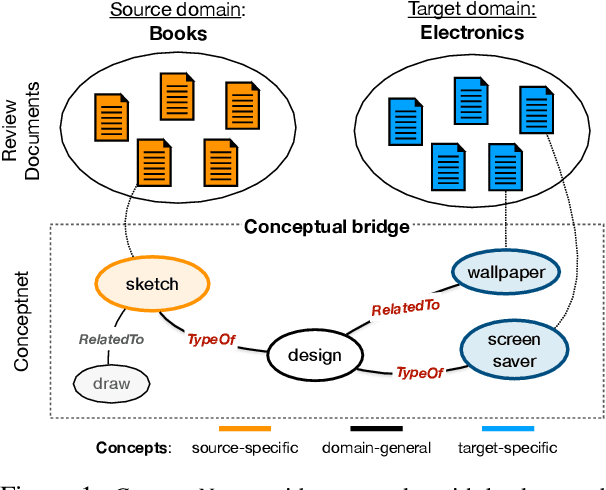
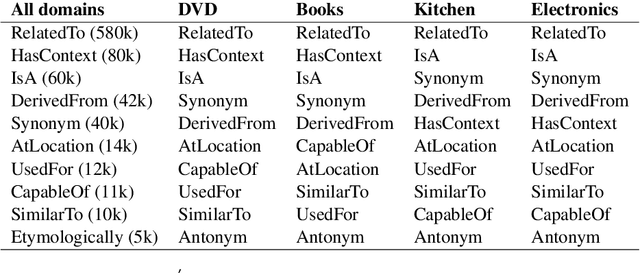
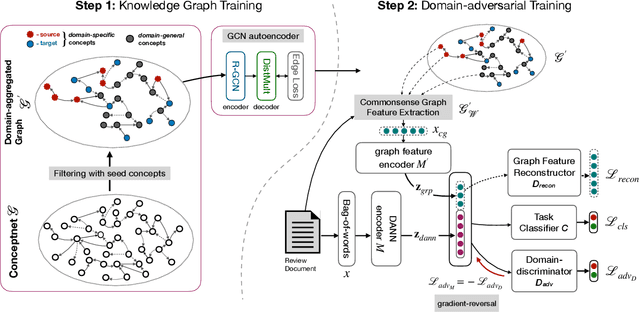
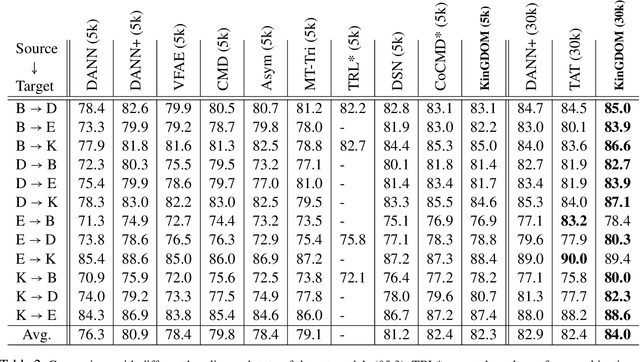
Cross-domain sentiment analysis has received significant attention in recent years, prompted by the need to combat the domain gap between different applications that make use of sentiment analysis. In this paper, we take a novel perspective on this task by exploring the role of external commonsense knowledge. We introduce a new framework, KinGDOM, which utilizes the ConceptNet knowledge graph to enrich the semantics of a document by providing both domain-specific and domain-general background concepts. These concepts are learned by training a graph convolutional autoencoder that leverages inter-domain concepts in a domain-invariant manner. Conditioning a popular domain-adversarial baseline method with these learned concepts helps improve its performance over state-of-the-art approaches, demonstrating the efficacy of our proposed framework.