 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeNear-Optimal Non-Parametric Sequential Tests and Confidence Sequences with Possibly Dependent Observations
Dec 29, 2022Sequential testing, always-valid $p$-values, and confidence sequences promise flexible statistical inference and on-the-fly decision making. However, unlike fixed-$n$ inference based on asymptotic normality, existing sequential tests either make parametric assumptions and end up under-covering/over-rejecting when these fail or use non-parametric but conservative concentration inequalities and end up over-covering/under-rejecting. To circumvent these issues, we sidestep exact at-least-$\alpha$ coverage and focus on asymptotically exact coverage and asymptotic optimality. That is, we seek sequential tests whose probability of ever rejecting a true hypothesis asymptotically approaches $\alpha$ and whose expected time to reject a false hypothesis approaches a lower bound on all tests with asymptotic coverage at least $\alpha$, both under an appropriate asymptotic regime. We permit observations to be both non-parametric and dependent and focus on testing whether the observations form a martingale difference sequence. We propose the universal sequential probability ratio test (uSPRT), a slight modification to the normal-mixture sequential probability ratio test, where we add a burn-in period and adjust thresholds accordingly. We show that even in this very general setting, the uSPRT is asymptotically optimal under mild generic conditions. We apply the results to stabilized estimating equations to test means, treatment effects, etc. Our results also provide corresponding guarantees for the implied confidence sequences. Numerical simulations verify our guarantees and the benefits of the uSPRT over alternatives.
A Review of Off-Policy Evaluation in Reinforcement Learning
Dec 13, 2022Reinforcement learning (RL) is one of the most vibrant research frontiers in machine learning and has been recently applied to solve a number of challenging problems. In this paper, we primarily focus on off-policy evaluation (OPE), one of the most fundamental topics in RL. In recent years, a number of OPE methods have been developed in the statistics and computer science literature. We provide a discussion on the efficiency bound of OPE, some of the existing state-of-the-art OPE methods, their statistical properties and some other related research directions that are currently actively explored.
The Implicit Delta Method
Nov 11, 2022Epistemic uncertainty quantification is a crucial part of drawing credible conclusions from predictive models, whether concerned about the prediction at a given point or any downstream evaluation that uses the model as input. When the predictive model is simple and its evaluation differentiable, this task is solved by the delta method, where we propagate the asymptotically-normal uncertainty in the predictive model through the evaluation to compute standard errors and Wald confidence intervals. However, this becomes difficult when the model and/or evaluation becomes more complex. Remedies include the bootstrap, but it can be computationally infeasible when training the model even once is costly. In this paper, we propose an alternative, the implicit delta method, which works by infinitesimally regularizing the training loss of the predictive model to automatically assess downstream uncertainty. We show that the change in the evaluation due to regularization is consistent for the asymptotic variance of the evaluation estimator, even when the infinitesimal change is approximated by a finite difference. This provides both a reliable quantification of uncertainty in terms of standard errors as well as permits the construction of calibrated confidence intervals. We discuss connections to other approaches to uncertainty quantification, both Bayesian and frequentist, and demonstrate our approach empirically.
Provable Safe Reinforcement Learning with Binary Feedback
Oct 26, 2022
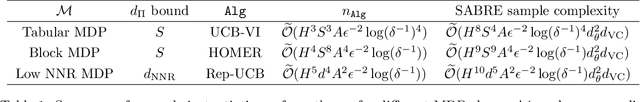
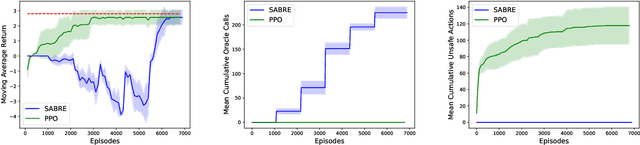

Safety is a crucial necessity in many applications of reinforcement learning (RL), whether robotic, automotive, or medical. Many existing approaches to safe RL rely on receiving numeric safety feedback, but in many cases this feedback can only take binary values; that is, whether an action in a given state is safe or unsafe. This is particularly true when feedback comes from human experts. We therefore consider the problem of provable safe RL when given access to an offline oracle providing binary feedback on the safety of state, action pairs. We provide a novel meta algorithm, SABRE, which can be applied to any MDP setting given access to a blackbox PAC RL algorithm for that setting. SABRE applies concepts from active learning to reinforcement learning to provably control the number of queries to the safety oracle. SABRE works by iteratively exploring the state space to find regions where the agent is currently uncertain about safety. Our main theoretical results shows that, under appropriate technical assumptions, SABRE never takes unsafe actions during training, and is guaranteed to return a near-optimal safe policy with high probability. We provide a discussion of how our meta-algorithm may be applied to various settings studied in both theoretical and empirical frameworks.
Debiased Inference on Identified Linear Functionals of Underidentified Nuisances via Penalized Minimax Estimation
Aug 17, 2022


We study generic inference on identified linear functionals of nonunique nuisances defined as solutions to underidentified conditional moment restrictions. This problem appears in a variety of applications, including nonparametric instrumental variable models, proximal causal inference under unmeasured confounding, and missing-not-at-random data with shadow variables. Although the linear functionals of interest, such as average treatment effect, are identifiable under suitable conditions, nonuniqueness of nuisances pose serious challenges to statistical inference, since in this setting common nuisance estimators can be unstable and lack fixed limits. In this paper, we propose penalized minimax estimators for the nuisance functions and show they enable valid inference in this challenging setting. The proposed nuisance estimators can accommodate flexible function classes, and importantly, they can converge to fixed limits determined by the penalization, regardless of whether the nuisances are unique or not. We use the penalized nuisance estimators to form a debiased estimator for the linear functional of interest and prove its asymptotic normality under generic high-level conditions, which provide for asymptotically valid confidence intervals.
Future-Dependent Value-Based Off-Policy Evaluation in POMDPs
Jul 26, 2022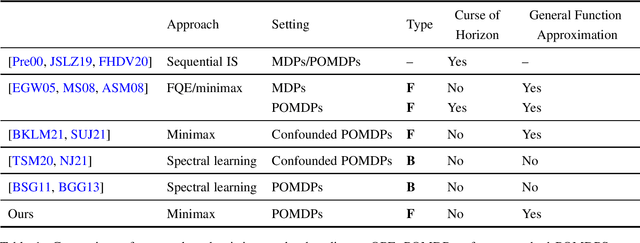
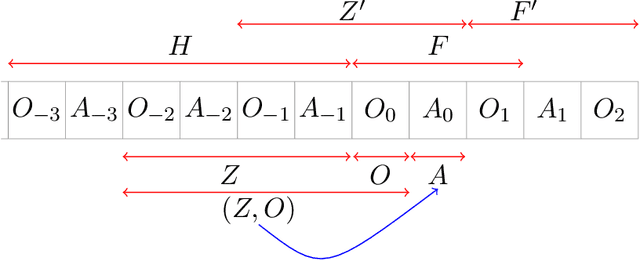
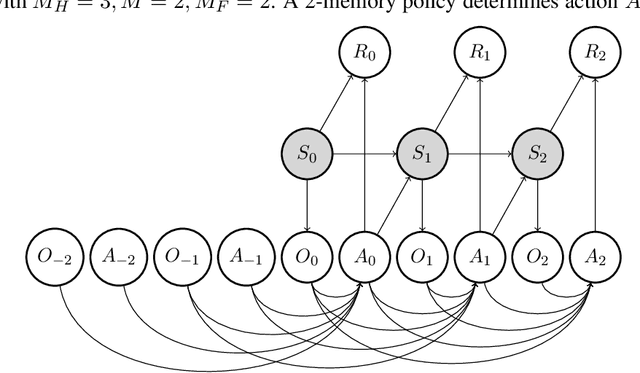
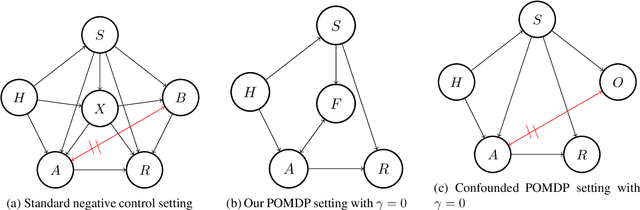
We study off-policy evaluation (OPE) for partially observable MDPs (POMDPs) with general function approximation. Existing methods such as sequential importance sampling estimators and fitted-Q evaluation suffer from the curse of horizon in POMDPs. To circumvent this problem, we develop a novel model-free OPE method by introducing future-dependent value functions that take future proxies as inputs. Future-dependent value functions play similar roles as classical value functions in fully-observable MDPs. We derive a new Bellman equation for future-dependent value functions as conditional moment equations that use history proxies as instrumental variables. We further propose a minimax learning method to learn future-dependent value functions using the new Bellman equation. We obtain the PAC result, which implies our OPE estimator is consistent as long as futures and histories contain sufficient information about latent states, and the Bellman completeness. Finally, we extend our methods to learning of dynamics and establish the connection between our approach and the well-known spectral learning methods in POMDPs.
Learning Bellman Complete Representations for Offline Policy Evaluation
Jul 12, 2022
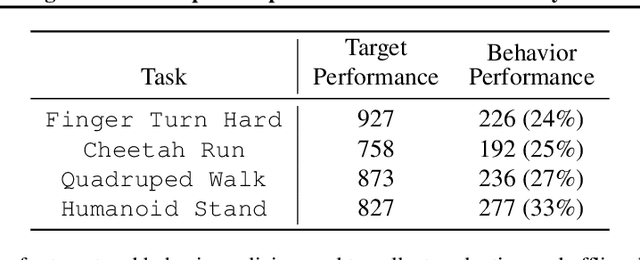

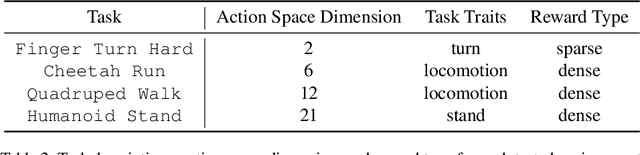
We study representation learning for Offline Reinforcement Learning (RL), focusing on the important task of Offline Policy Evaluation (OPE). Recent work shows that, in contrast to supervised learning, realizability of the Q-function is not enough for learning it. Two sufficient conditions for sample-efficient OPE are Bellman completeness and coverage. Prior work often assumes that representations satisfying these conditions are given, with results being mostly theoretical in nature. In this work, we propose BCRL, which directly learns from data an approximately linear Bellman complete representation with good coverage. With this learned representation, we perform OPE using Least Square Policy Evaluation (LSPE) with linear functions in our learned representation. We present an end-to-end theoretical analysis, showing that our two-stage algorithm enjoys polynomial sample complexity provided some representation in the rich class considered is linear Bellman complete. Empirically, we extensively evaluate our algorithm on challenging, image-based continuous control tasks from the Deepmind Control Suite. We show our representation enables better OPE compared to previous representation learning methods developed for off-policy RL (e.g., CURL, SPR). BCRL achieve competitive OPE error with the state-of-the-art method Fitted Q-Evaluation (FQE), and beats FQE when evaluating beyond the initial state distribution. Our ablations show that both linear Bellman complete and coverage components of our method are crucial.
* Accepted for Long Talk at ICML 2022
Computationally Efficient PAC RL in POMDPs with Latent Determinism and Conditional Embeddings
Jun 24, 2022
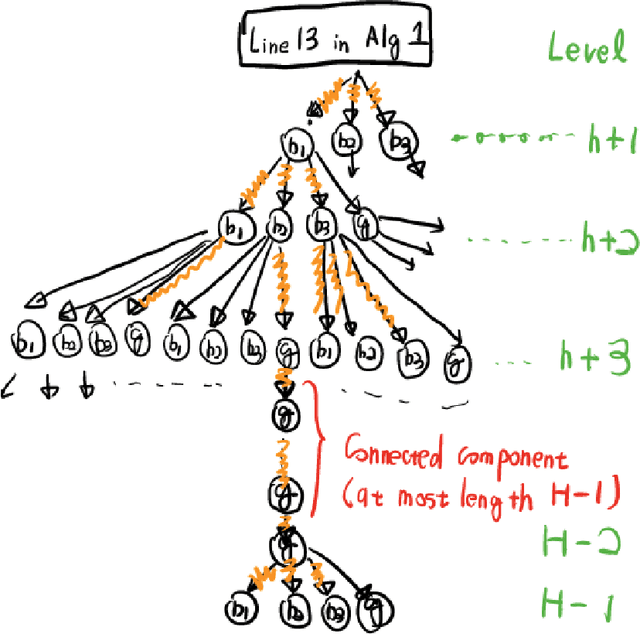
We study reinforcement learning with function approximation for large-scale Partially Observable Markov Decision Processes (POMDPs) where the state space and observation space are large or even continuous. Particularly, we consider Hilbert space embeddings of POMDP where the feature of latent states and the feature of observations admit a conditional Hilbert space embedding of the observation emission process, and the latent state transition is deterministic. Under the function approximation setup where the optimal latent state-action $Q$-function is linear in the state feature, and the optimal $Q$-function has a gap in actions, we provide a \emph{computationally and statistically efficient} algorithm for finding the \emph{exact optimal} policy. We show our algorithm's computational and statistical complexities scale polynomially with respect to the horizon and the intrinsic dimension of the feature on the observation space. Furthermore, we show both the deterministic latent transitions and gap assumptions are necessary to avoid statistical complexity exponential in horizon or dimension. Since our guarantee does not have an explicit dependence on the size of the state and observation spaces, our algorithm provably scales to large-scale POMDPs.
Provably Efficient Reinforcement Learning in Partially Observable Dynamical Systems
Jun 24, 2022
We study Reinforcement Learning for partially observable dynamical systems using function approximation. We propose a new \textit{Partially Observable Bilinear Actor-Critic framework}, that is general enough to include models such as observable tabular Partially Observable Markov Decision Processes (POMDPs), observable Linear-Quadratic-Gaussian (LQG), Predictive State Representations (PSRs), as well as a newly introduced model Hilbert Space Embeddings of POMDPs and observable POMDPs with latent low-rank transition. Under this framework, we propose an actor-critic style algorithm that is capable of performing agnostic policy learning. Given a policy class that consists of memory based policies (that look at a fixed-length window of recent observations), and a value function class that consists of functions taking both memory and future observations as inputs, our algorithm learns to compete against the best memory-based policy in the given policy class. For certain examples such as undercomplete observable tabular POMDPs, observable LQGs and observable POMDPs with latent low-rank transition, by implicitly leveraging their special properties, our algorithm is even capable of competing against the globally optimal policy without paying an exponential dependence on the horizon in its sample complexity.
Robust and Agnostic Learning of Conditional Distributional Treatment Effects
May 23, 2022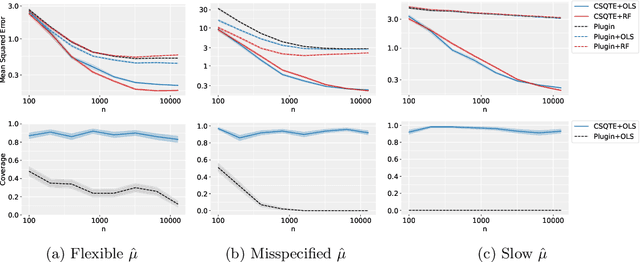
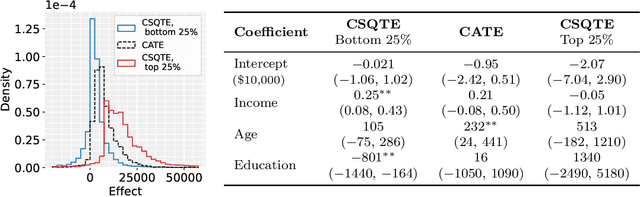
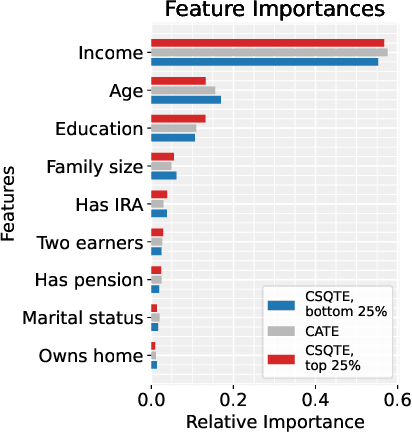
The conditional average treatment effect (CATE) is the best point prediction of individual causal effects given individual baseline covariates and can help personalize treatments. However, as CATE only reflects the (conditional) average, it can wash out potential risks and tail events, which are crucially relevant to treatment choice. In aggregate analyses, this is usually addressed by measuring distributional treatment effect (DTE), such as differences in quantiles or tail expectations between treatment groups. Hypothetically, one can similarly fit covariate-conditional quantile regressions in each treatment group and take their difference, but this would not be robust to misspecification or provide agnostic best-in-class predictions. We provide a new robust and model-agnostic methodology for learning the conditional DTE (CDTE) for a wide class of problems that includes conditional quantile treatment effects, conditional super-quantile treatment effects, and conditional treatment effects on coherent risk measures given by $f$-divergences. Our method is based on constructing a special pseudo-outcome and regressing it on baseline covariates using any given regression learner. Our method is model-agnostic in the sense that it can provide the best projection of CDTE onto the regression model class. Our method is robust in the sense that even if we learn these nuisances nonparametrically at very slow rates, we can still learn CDTEs at rates that depend on the class complexity and even conduct inferences on linear projections of CDTEs. We investigate the performance of our proposal in simulation studies, and we demonstrate its use in a case study of 401(k) eligibility effects on wealth.