 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeIntermediate Layers Matter in Momentum Contrastive Self Supervised Learning
Oct 27, 2021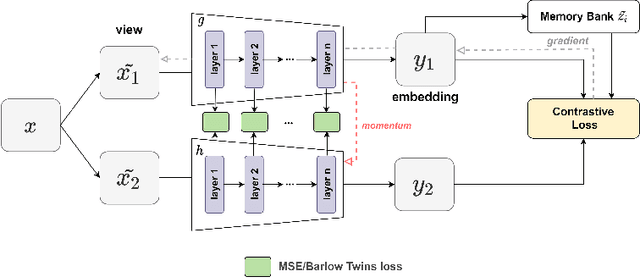
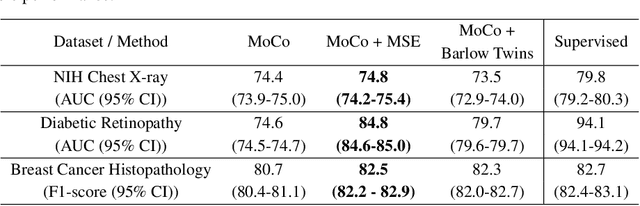
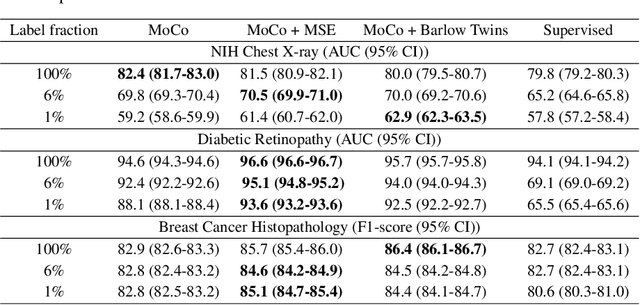
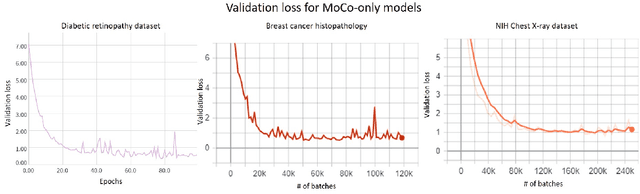
We show that bringing intermediate layers' representations of two augmented versions of an image closer together in self-supervised learning helps to improve the momentum contrastive (MoCo) method. To this end, in addition to the contrastive loss, we minimize the mean squared error between the intermediate layer representations or make their cross-correlation matrix closer to an identity matrix. Both loss objectives either outperform standard MoCo, or achieve similar performances on three diverse medical imaging datasets: NIH-Chest Xrays, Breast Cancer Histopathology, and Diabetic Retinopathy. The gains of the improved MoCo are especially large in a low-labeled data regime (e.g. 1% labeled data) with an average gain of 5% across three datasets. We analyze the models trained using our novel approach via feature similarity analysis and layer-wise probing. Our analysis reveals that models trained via our approach have higher feature reuse compared to a standard MoCo and learn informative features earlier in the network. Finally, by comparing the output probability distribution of models fine-tuned on small versus large labeled data, we conclude that our proposed method of pre-training leads to lower Kolmogorov-Smirnov distance, as compared to a standard MoCo. This provides additional evidence that our proposed method learns more informative features in the pre-training phase which could be leveraged in a low-labeled data regime.
An artificial intelligence system for predicting the deterioration of COVID-19 patients in the emergency department
Aug 04, 2020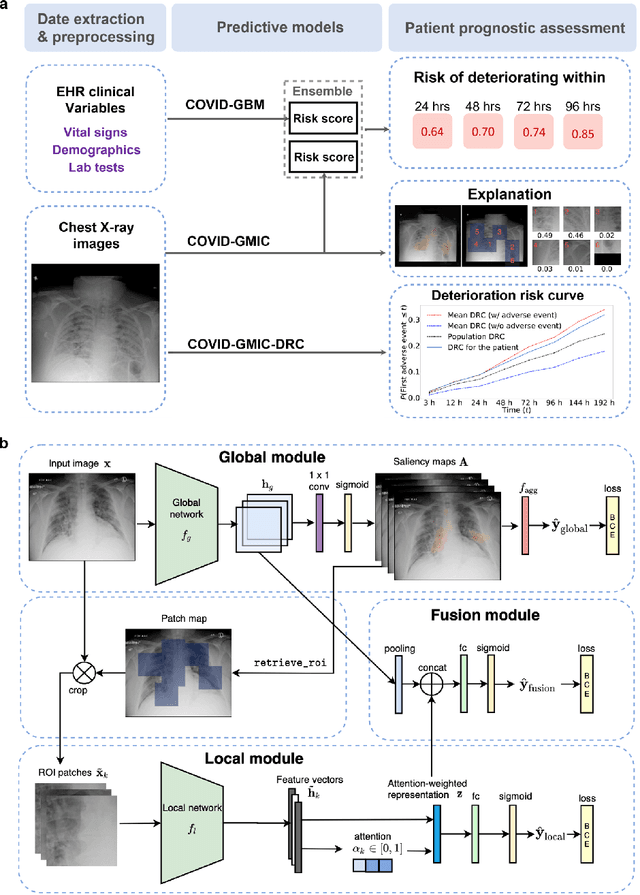
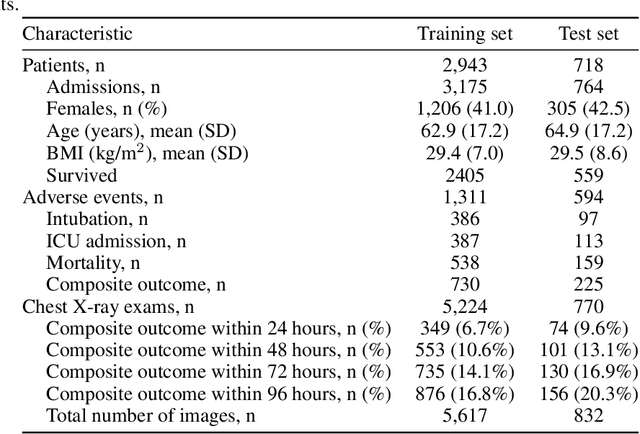
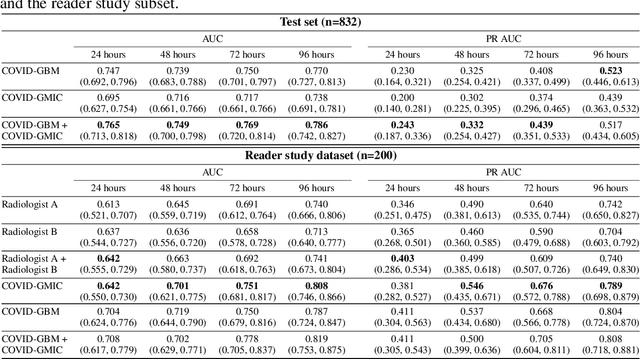
During the COVID-19 pandemic, rapid and accurate triage of patients at the emergency department is critical to inform decision-making. We propose a data-driven approach for automatic prediction of deterioration risk using a deep neural network that learns from chest X-ray images, and a gradient boosting model that learns from routine clinical variables. Our AI prognosis system, trained using data from 3,661 patients, achieves an AUC of 0.786 (95% CI: 0.742-0.827) when predicting deterioration within 96 hours. The deep neural network extracts informative areas of chest X-ray images to assist clinicians in interpreting the predictions, and performs comparably to two radiologists in a reader study. In order to verify performance in a real clinical setting, we silently deployed a preliminary version of the deep neural network at NYU Langone Health during the first wave of the pandemic, which produced accurate predictions in real-time. In summary, our findings demonstrate the potential of the proposed system for assisting front-line physicians in the triage of COVID-19 patients.
Early-Learning Regularization Prevents Memorization of Noisy Labels
Jun 30, 2020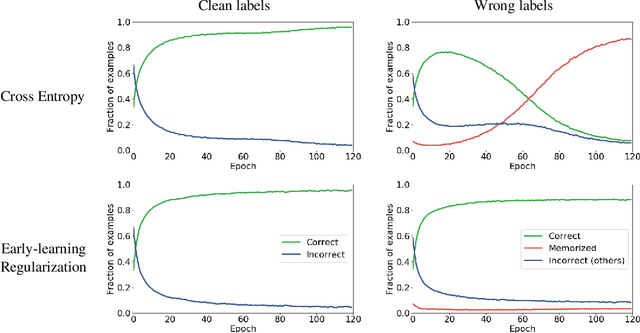
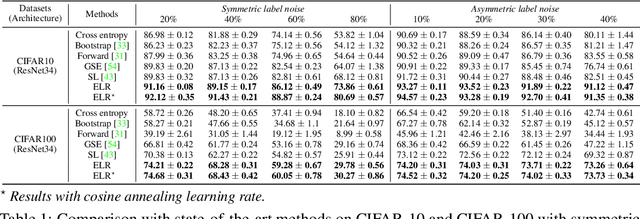
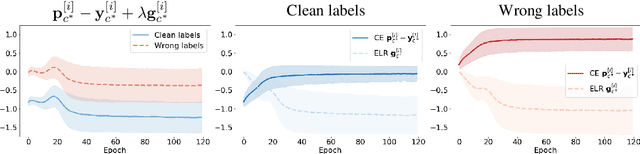
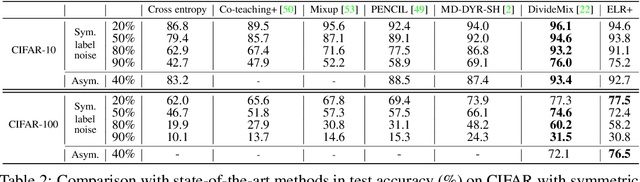
We propose a novel framework to perform classification via deep learning in the presence of noisy annotations. When trained on noisy labels, deep neural networks have been observed to first fit the training data with clean labels during an "early learning" phase, before eventually memorizing the examples with false labels. We prove that early learning and memorization are fundamental phenomena in high-dimensional classification tasks, even in simple linear models, and give a theoretical explanation in this setting. Motivated by these findings, we develop a new technique for noisy classification tasks, which exploits the progress of the early learning phase. In contrast with existing approaches, which use the model output during early learning to detect the examples with clean labels, and either ignore or attempt to correct the false labels, we take a different route and instead capitalize on early learning via regularization. There are two key elements to our approach. First, we leverage semi-supervised learning techniques to produce target probabilities based on the model outputs. Second, we design a regularization term that steers the model towards these targets, implicitly preventing memorization of the false labels. The resulting framework is shown to provide robustness to noisy annotations on several standard benchmarks and real-world datasets, where it achieves results comparable to the state of the art.
BERT-XML: Large Scale Automated ICD Coding Using BERT Pretraining
May 26, 2020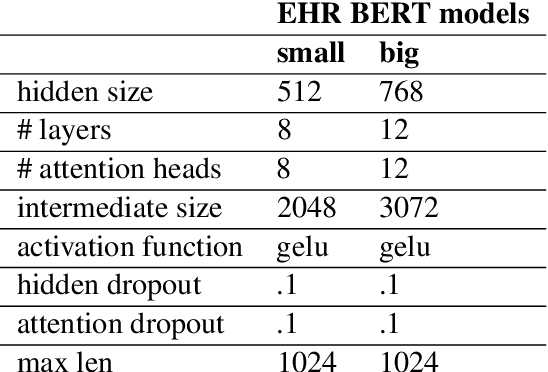
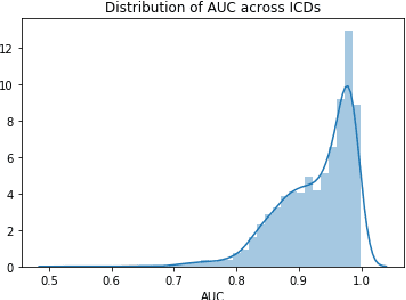
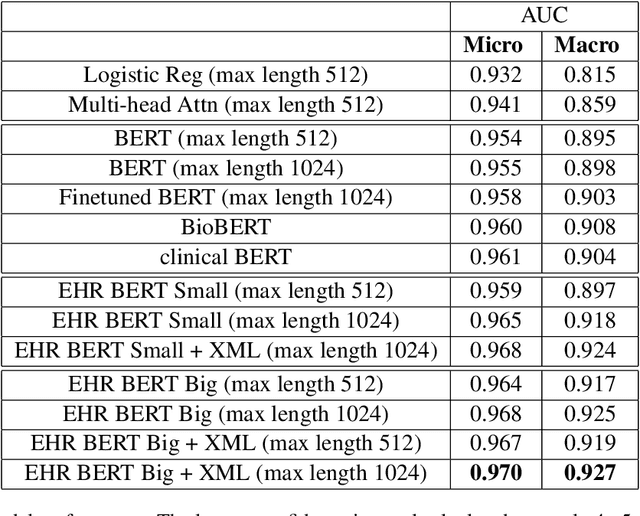

Clinical interactions are initially recorded and documented in free text medical notes. ICD coding is the task of classifying and coding all diagnoses, symptoms and procedures associated with a patient's visit. The process is often manual and extremely time-consuming and expensive for hospitals. In this paper, we propose a machine learning model, BERT-XML, for large scale automated ICD coding from EHR notes, utilizing recently developed unsupervised pretraining that have achieved state of the art performance on a variety of NLP tasks. We train a BERT model from scratch on EHR notes, learning with vocabulary better suited for EHR tasks and thus outperform off-the-shelf models. We adapt the BERT architecture for ICD coding with multi-label attention. While other works focus on small public medical datasets, we have produced the first large scale ICD-10 classification model using millions of EHR notes to predict thousands of unique ICD codes.
Graph Neural Network on Electronic Health Records for Predicting Alzheimer's Disease
Dec 08, 2019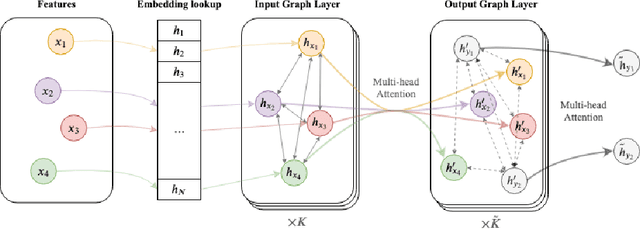
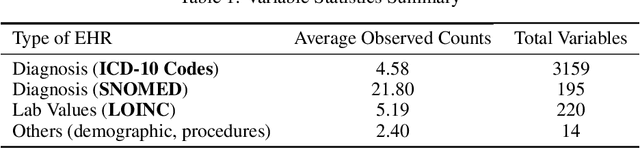
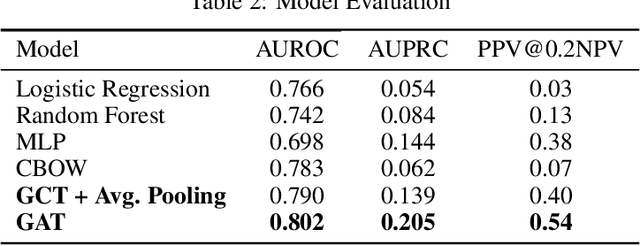

The cause of Alzheimer's disease (AD) is poorly understood, so forecasting AD remains a hard task in population health. Failure of clinical trials for AD treatments indicates that AD should be intervened at the earlier, pre-symptomatic stages. Developing an explainable method for predicting AD is critical for providing better treatment targets, better clinical trial recruitment, and better clinical care for the AD patients. In this paper, we present a novel approach for disease (AD) prediction based on Electronic Health Records (EHR) and graph neural network. Our method improves the performance on sparse data which is common in EHR, and obtains state-of-art results in predicting AD 12 to 24 months in advance on real-world EHR data, compared to other baseline results. Our approach also provides an insight into the structural relationship among different diagnosis, Lab values, and procedures from EHR as per graph structures learned by our model.
Tracing State-Level Obesity Prevalence from Sentence Embeddings of Tweets: A Feasibility Study
Dec 02, 2019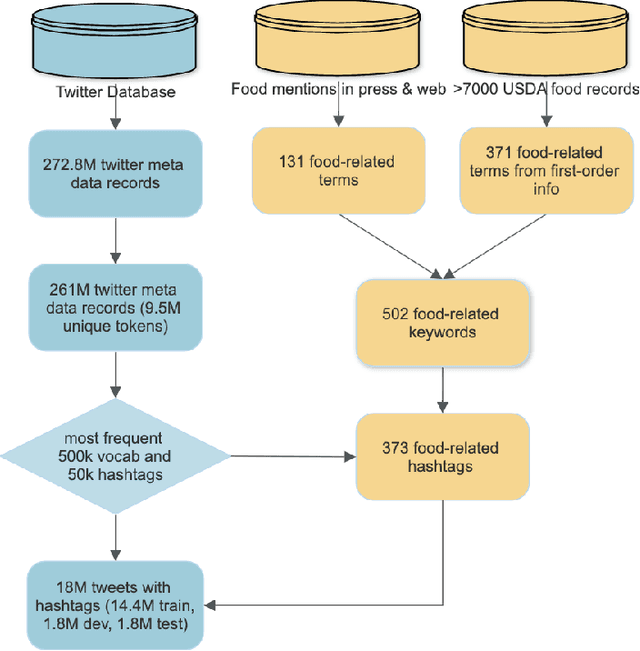

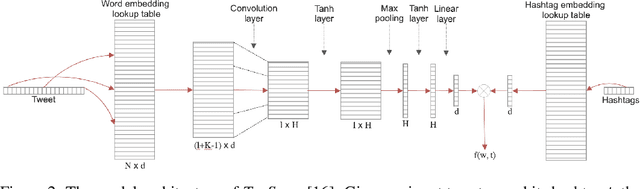
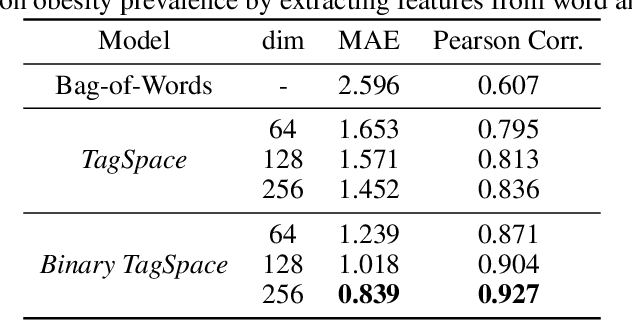
Twitter data has been shown broadly applicable for public health surveillance. Previous public health studies based on Twitter data have largely relied on keyword-matching or topic models for clustering relevant tweets. However, both methods suffer from the short-length of texts and unpredictable noise that naturally occurs in user-generated contexts. In response, we introduce a deep learning approach that uses hashtags as a form of supervision and learns tweet embeddings for extracting informative textual features. In this case study, we address the specific task of estimating state-level obesity from dietary-related textual features. Our approach yields an estimation that strongly correlates the textual features to government data and outperforms the keyword-matching baseline. The results also demonstrate the potential of discovering risk factors using the textual features. This method is general-purpose and can be applied to a wide range of Twitter-based public health studies.
Towards Quantification of Bias in Machine Learning for Healthcare: A Case Study of Renal Failure Prediction
Nov 18, 2019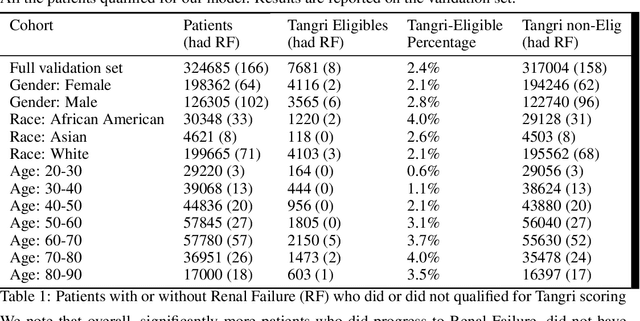
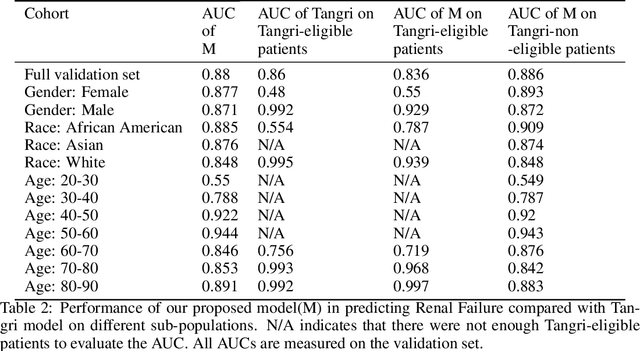
As machine learning (ML) models, trained on real-world datasets, become common practice, it is critical to measure and quantify their potential biases. In this paper, we focus on renal failure and compare a commonly used traditional risk score, Tangri, with a more powerful machine learning model, which has access to a larger variable set and trained on 1.6 million patients' EHR data. We will compare and discuss the generalization and applicability of these two models, in an attempt to quantify biases of status quo clinical practice, compared to ML-driven models.
DARTS: DenseUnet-based Automatic Rapid Tool for brain Segmentation
Nov 14, 2019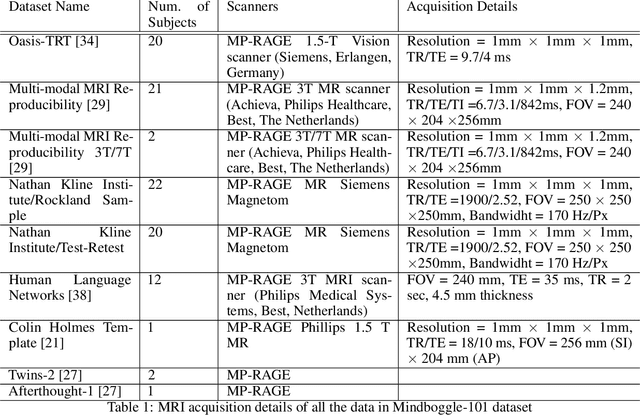
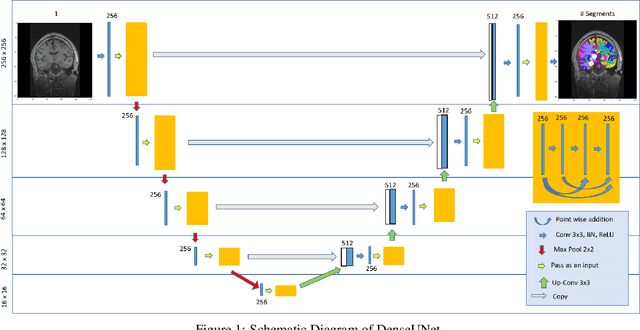
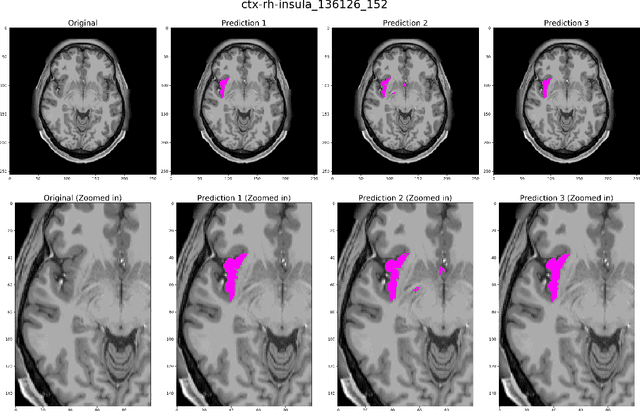
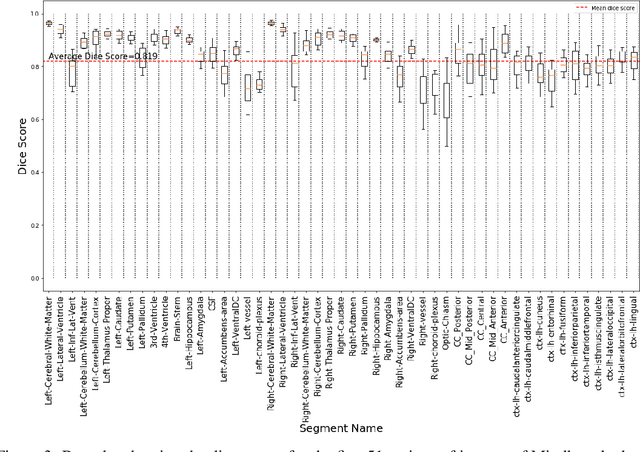
Quantitative, volumetric analysis of Magnetic Resonance Imaging (MRI) is a fundamental way researchers study the brain in a host of neurological conditions including normal maturation and aging. Despite the availability of open-source brain segmentation software, widespread clinical adoption of volumetric analysis has been hindered due to processing times and reliance on manual corrections. Here, we extend the use of deep learning models from proof-of-concept, as previously reported, to present a comprehensive segmentation of cortical and deep gray matter brain structures matching the standard regions of aseg+aparc included in the commonly used open-source tool, Freesurfer. The work presented here provides a real-life, rapid deep learning-based brain segmentation tool to enable clinical translation as well as research application of quantitative brain segmentation. The advantages of the presented tool include short (~1 minute) processing time and improved segmentation quality. This is the first study to perform quick and accurate segmentation of 102 brain regions based on the surface-based protocol (DMK protocol), widely used by experts in the field. This is also the first work to include an expert reader study to assess the quality of the segmentation obtained using a deep-learning-based model. We show the superior performance of our deep-learning-based models over the traditional segmentation tool, Freesurfer. We refer to the proposed deep learning-based tool as DARTS (DenseUnet-based Automatic Rapid Tool for brain Segmentation). Our tool and trained models are available at https://github.com/NYUMedML/DARTS
On the design of convolutional neural networks for automatic detection of Alzheimer's disease
Nov 12, 2019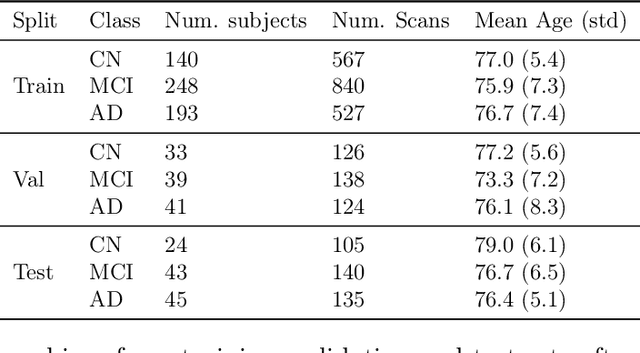
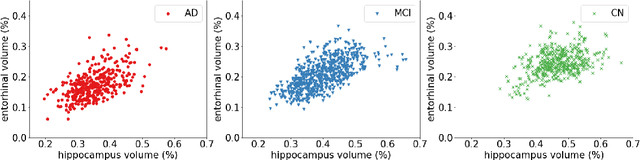
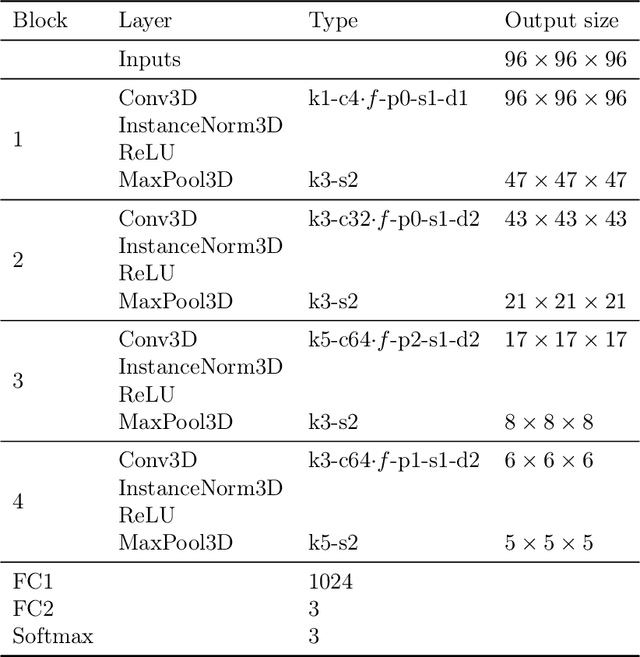
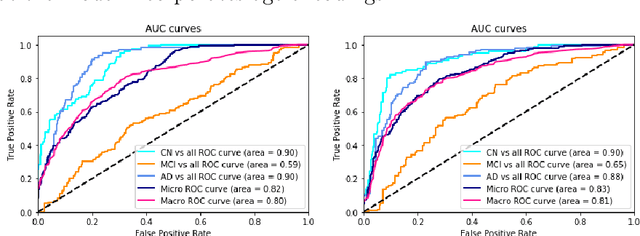
Early detection is a crucial goal in the study of Alzheimer's Disease (AD). In this work, we describe several techniques to boost the performance of 3D convolutional neural networks trained to detect AD using structural brain MRI scans. Specifically, we provide evidence that (1) instance normalization outperforms batch normalization, (2) early spatial downsampling negatively affects performance, (3) widening the model brings consistent gains while increasing the depth does not, and (4) incorporating age information yields moderate improvement. Together, these insights yield an increment of approximately 14% in test accuracy over existing models when distinguishing between patients with AD, mild cognitive impairment, and controls in the ADNI dataset. Similar performance is achieved on an independent dataset.
* Machine Learning for Health Workshop, NeurIPS2019. Authors Fernandez-Granda and Razavian are joint last authors
Deep EHR: Chronic Disease Prediction Using Medical Notes
Aug 15, 2018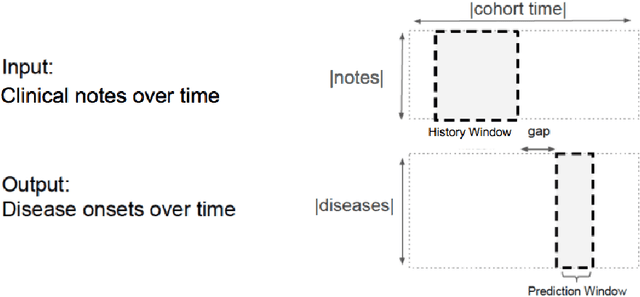

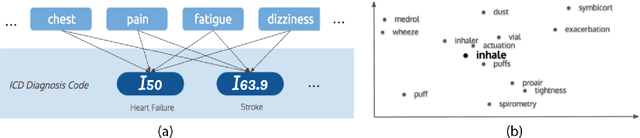
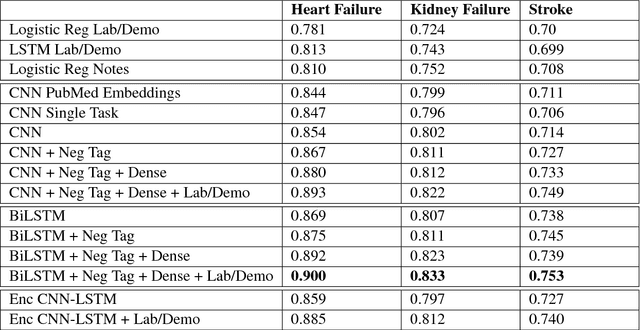
Early detection of preventable diseases is important for better disease management, improved inter-ventions, and more efficient health-care resource allocation. Various machine learning approacheshave been developed to utilize information in Electronic Health Record (EHR) for this task. Majorityof previous attempts, however, focus on structured fields and lose the vast amount of information inthe unstructured notes. In this work we propose a general multi-task framework for disease onsetprediction that combines both free-text medical notes and structured information. We compareperformance of different deep learning architectures including CNN, LSTM and hierarchical models.In contrast to traditional text-based prediction models, our approach does not require disease specificfeature engineering, and can handle negations and numerical values that exist in the text. Ourresults on a cohort of about 1 million patients show that models using text outperform modelsusing just structured data, and that models capable of using numerical values and negations in thetext, in addition to the raw text, further improve performance. Additionally, we compare differentvisualization methods for medical professionals to interpret model predictions.