 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSupervised Learning based Sparse Channel Estimation for RIS aided Communications
Feb 24, 2022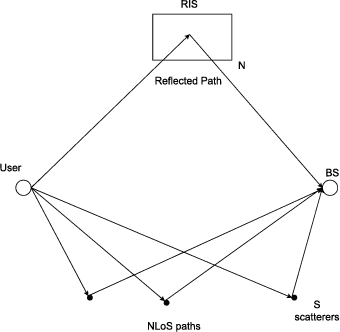
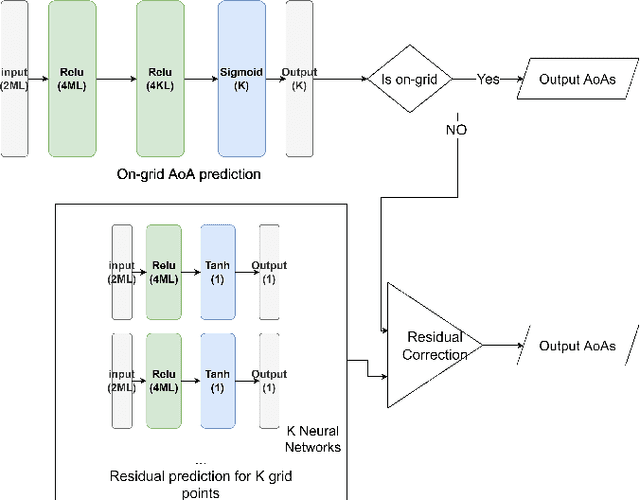
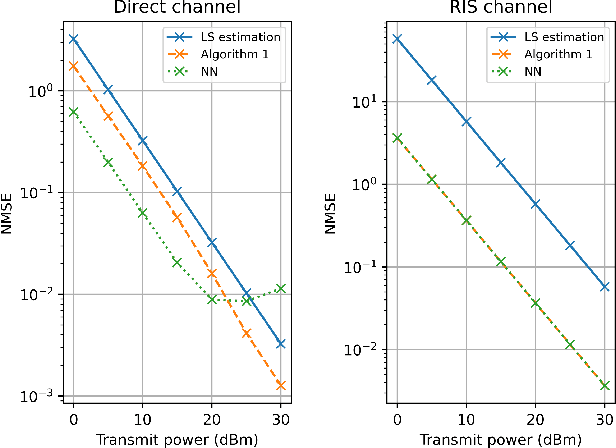
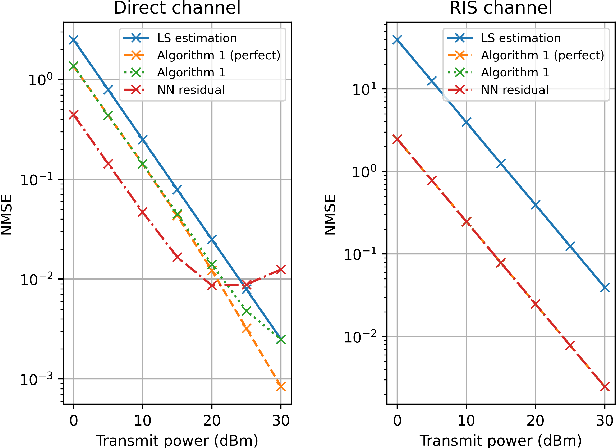
An reconfigurable intelligent surface (RIS) can be used to establish line-of-sight (LoS) communication when the direct path is compromised, which is a common occurrence in a millimeter wave (mmWave) network. In this paper, we focus on the uplink channel estimation of a such network. We formulate this as a sparse signal recovery problem, by discretizing the angle of arrivals (AoAs) at the base station (BS). On-grid and off-grid AoAs are considered separately. In the on-grid case, we propose an algorithm to estimate the direct and RIS channels. Neural networks trained based on supervised learning is used to estimate the residual angles in the off-grid case, and the AoAs in both cases. Numerical results show the performance gains of the proposed algorithms in both cases.
Permutation Matrix Modulation
Dec 27, 2021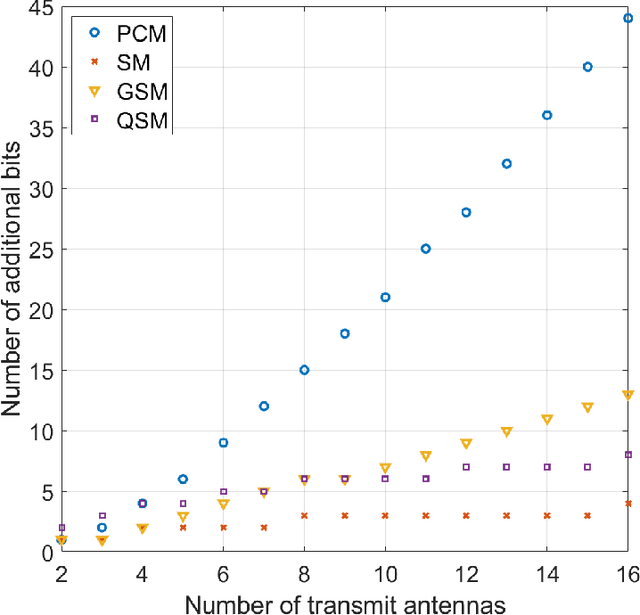
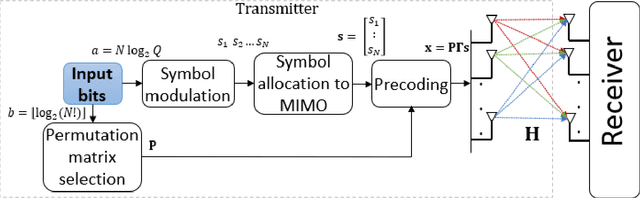
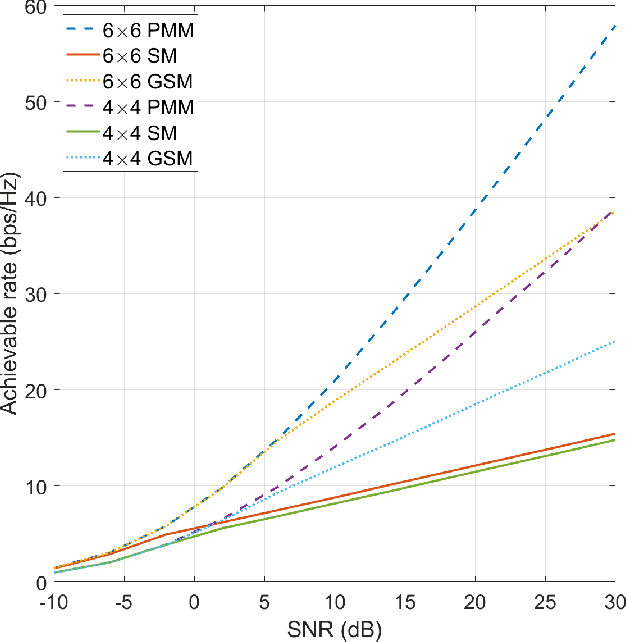
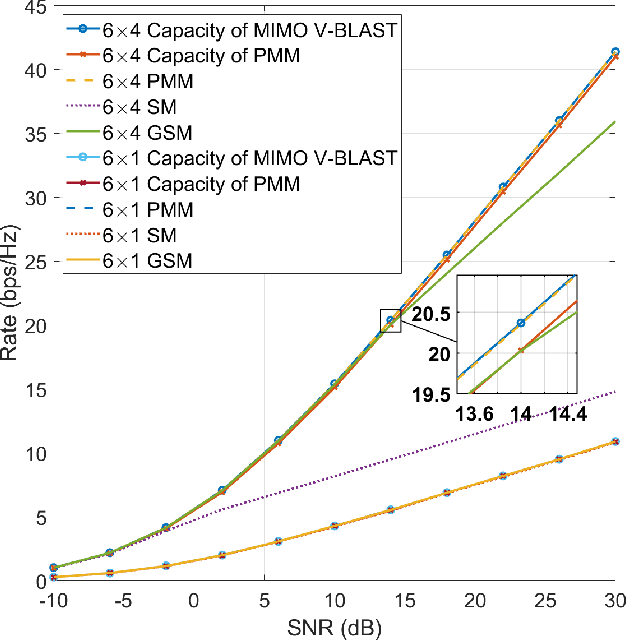
We propose a novel scheme that allows MIMO system to modulate a set of permutation matrices to send more information bits, extending our initial work on the topic. This system is called Permutation Matrix Modulation (PMM). The basic idea is to employ a permutation matrix as a precoder and treat it as a modulated symbol. We continue the evolution of index modulation in MIMO by adopting all-antenna activation and obtaining a set of unique symbols from altering the positions of the antenna transmit power. We provide the analysis of the achievable rate of PMM under Gaussian Mixture Model (GMM) distribution and evaluate the numerical results by comparing it with the other existing systems. The result shows that PMM outperforms the existing systems under a fair parameter setting. We also present a way to attain the optimal achievable rate of PMM by solving a maximization problem via interior-point method. A low complexity detection scheme based on zero-forcing (ZF) is proposed, and maximum likelihood (ML) detection is discussed. We demonstrate the trade-off between simulation of the symbol error rate (SER) and the computational complexity where ZF performs worse in the SER simulation but requires much less computational complexity than ML.
LiDAR Aided Human Blockage Prediction for 6G
Oct 01, 2021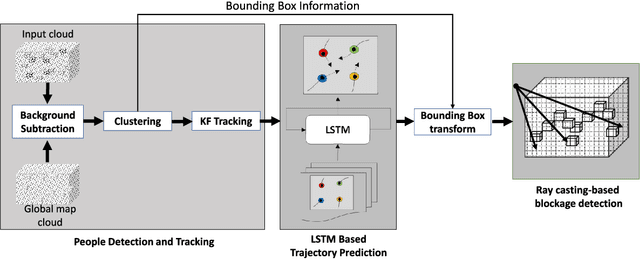

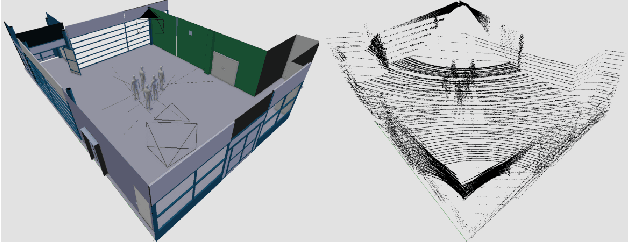

Leveraging higher frequencies up to THz band paves the way towards a faster network in the next generation of wireless communications. However, such shorter wavelengths are susceptible to higher scattering and path loss forcing the link to depend predominantly on the line-of-sight (LOS) path. Dynamic movement of humans has been identified as a major source of blockages to such LOS links. In this work, we aim to overcome this challenge by predicting human blockages to the LOS link enabling the transmitter to anticipate the blockage and act intelligently. We propose an end-to-end system of infrastructure-mounted LiDAR sensors to capture the dynamics of the communication environment visually, process the data with deep learning and ray casting techniques to predict future blockages. Experiments indicate that the system achieves an accuracy of 87% predicting the upcoming blockages while maintaining a precision of 78% and a recall of 79% for a window of 300 ms.
A Low Complexity Learning-based Channel Estimation for OFDM Systems with Online Training
Jul 14, 2021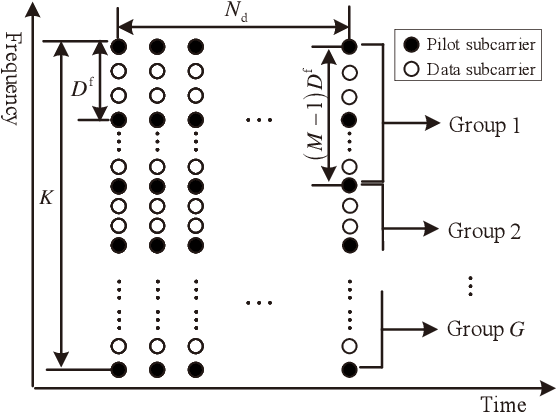
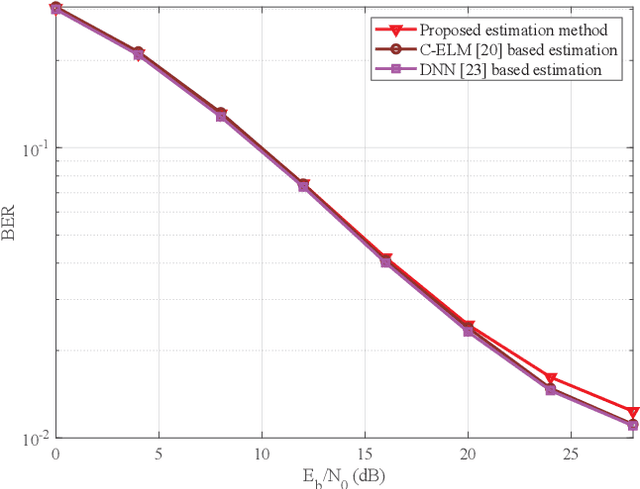
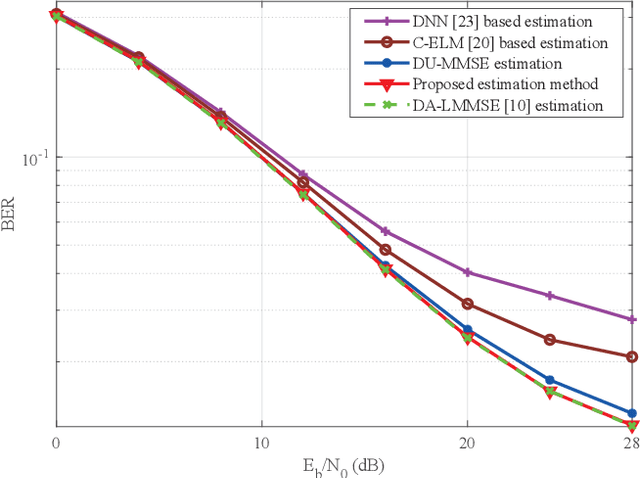
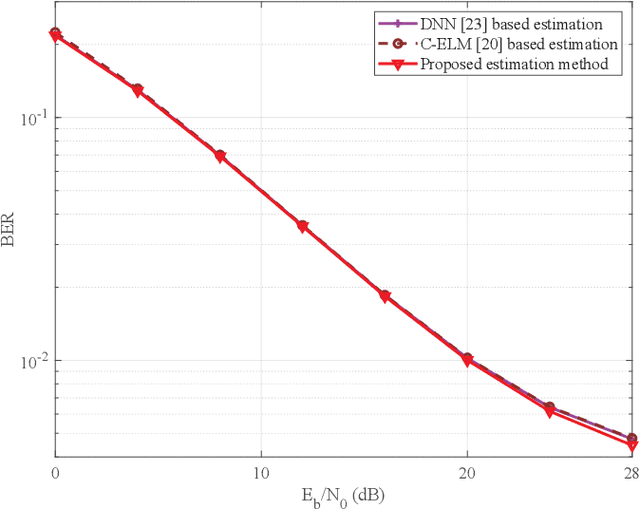
In this paper, we devise a highly efficient machine learning-based channel estimation for orthogonal frequency division multiplexing (OFDM) systems, in which the training of the estimator is performed online. A simple learning module is employed for the proposed learning-based estimator. The training process is thus much faster and the required training data is reduced significantly. Besides, a training data construction approach utilizing least square (LS) estimation results is proposed so that the training data can be collected during the data transmission. The feasibility of this novel construction approach is verified by theoretical analysis and simulations. Based on this construction approach, two alternative training data generation schemes are proposed. One scheme transmits additional block pilot symbols to create training data, while the other scheme adopts a decision-directed method and does not require extra pilot overhead. Simulation results show the robustness of the proposed channel estimation method. Furthermore, the proposed method shows better adaptation to practical imperfections compared with the conventional minimum mean-square error (MMSE) channel estimation. It outperforms the existing machine learning-based channel estimation techniques under varying channel conditions.
Untrained DNN for Channel Estimation of RIS-Assisted Multi-User OFDM System with Hardware Impairments
Jul 13, 2021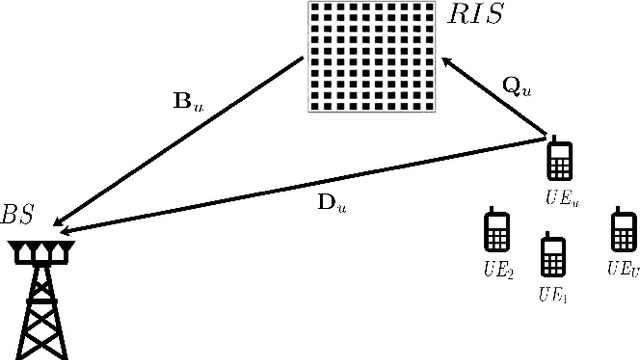
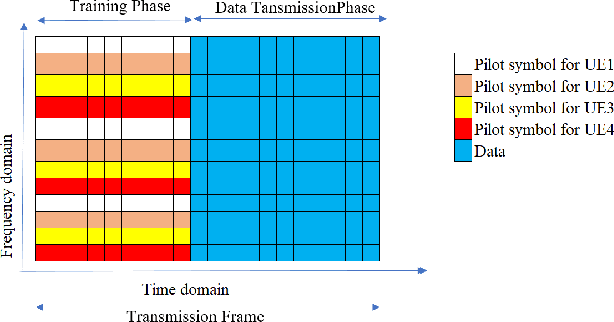

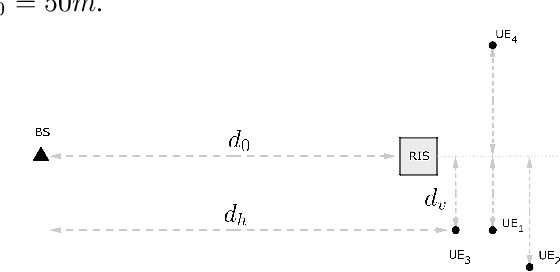
Reconfigurable intelligent surface (RIS) is an emerging technology for improving performance in fifth-generation (5G) and beyond networks. Practically channel estimation of RIS-assisted systems is challenging due to the passive nature of the RIS. The purpose of this paper is to introduce a deep learning-based, low complexity channel estimator for the RIS-assisted multi-user single-input-multiple-output (SIMO) orthogonal frequency division multiplexing (OFDM) system with hardware impairments. We propose an untrained deep neural network (DNN) based on the deep image prior (DIP) network to denoise the effective channel of the system obtained from the conventional pilot-based least-square (LS) estimation and acquire a more accurate estimation. We have shown that our proposed method has high performance in terms of accuracy and low complexity compared to conventional methods. Further, we have shown that the proposed estimator is robust to interference caused by the hardware impairments at the transceiver and RIS.
Deep Neural Network-Based Blind Multiple User Detection for Grant-free Multi-User Shared Access
Jun 21, 2021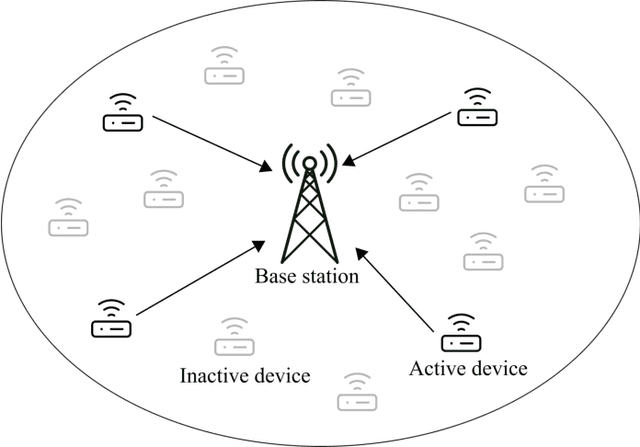
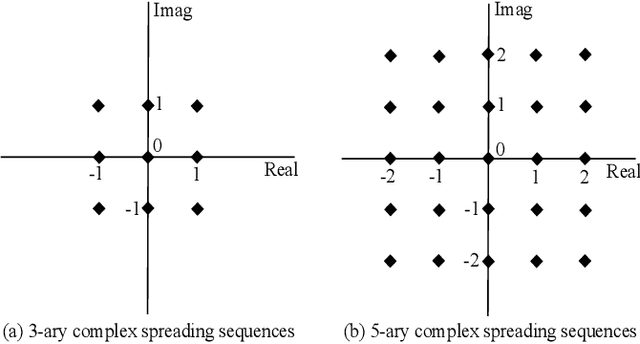
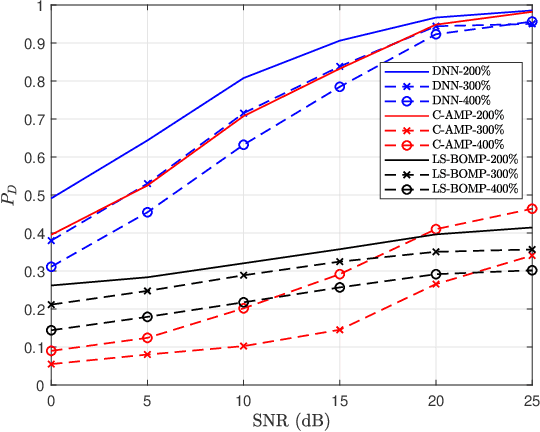
Multi-user shared access (MUSA) is introduced as advanced code domain non-orthogonal complex spreading sequences to support a massive number of machine-type communications (MTC) devices. In this paper, we propose a novel deep neural network (DNN)-based multiple user detection (MUD) for grant-free MUSA systems. The DNN-based MUD model determines the structure of the sensing matrix, randomly distributed noise, and inter-device interference during the training phase of the model by several hidden nodes, neuron activation units, and a fit loss function. The thoroughly learned DNN model is capable of distinguishing the active devices of the received signal without any a priori knowledge of the device sparsity level and the channel state information. Our numerical evaluation shows that with a higher percentage of active devices, the DNN-MUD achieves a significantly increased probability of detection compared to the conventional approaches.
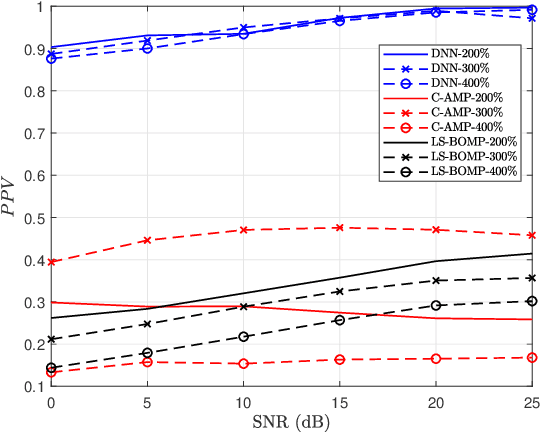
Deep Learning-Based Active User Detection for Grant-free SCMA Systems
Jun 21, 2021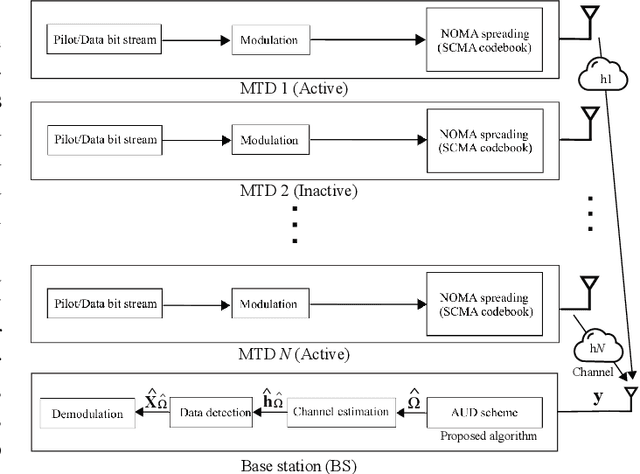
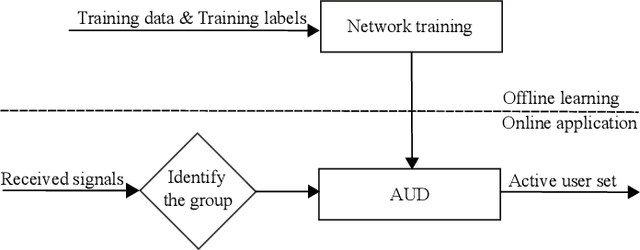

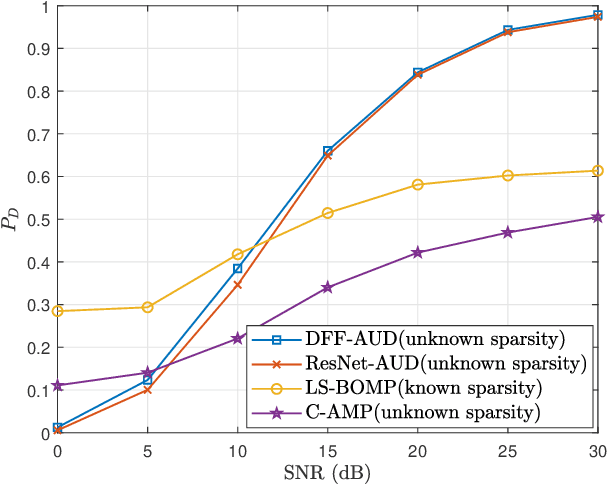
Grant-free random access and uplink non-orthogonal multiple access (NOMA) have been introduced to reduce transmission latency and signaling overhead in massive machine-type communication (mMTC). In this paper, we propose two novel group-based deep neural network active user detection (AUD) schemes for the grant-free sparse code multiple access (SCMA) system in mMTC uplink framework. The proposed AUD schemes learn the nonlinear mapping, i.e., multi-dimensional codebook structure and the channel characteristic. This is accomplished through the received signal which incorporates the sparse structure of device activity with the training dataset. Moreover, the offline pre-trained model is able to detect the active devices without any channel state information and prior knowledge of the device sparsity level. Simulation results show that with several active devices, the proposed schemes obtain more than twice the probability of detection compared to the conventional AUD schemes over the signal to noise ratio range of interest.
Deep Contextual Bandits for Fast Neighbor-Aided Initial Access in mmWave Cell-Free Networks
Mar 17, 2021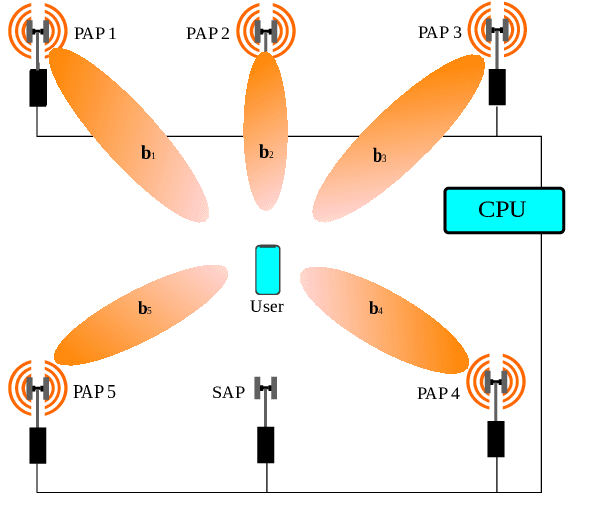
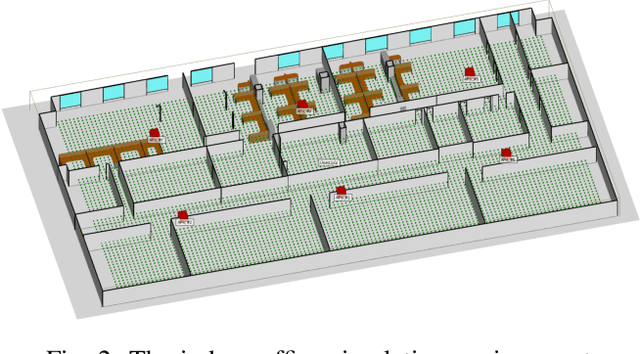
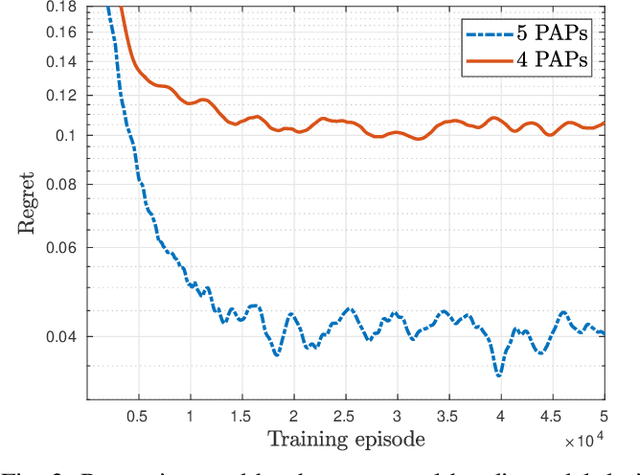
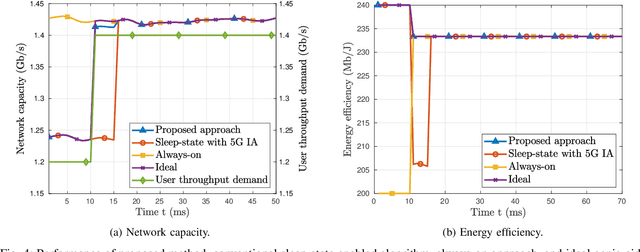
Access points (APs) in millimeter-wave (mmWave) and sub-THz-based user-centric (UC) networks will have sleep mode functionality. As a result of this, it becomes challenging to solve the initial access (IA) problem when the sleeping APs are activated to start serving users. In this paper, a novel deep contextual bandit (DCB) learning method is proposed to provide instant IA using information from the neighboring active APs. In the proposed approach, beam selection information from the neighboring active APs is used as an input to neural networks that act as a function approximator for the bandit algorithm. Simulations are carried out with realistic channel models generated using the Wireless Insight ray-tracing tool. The results show that the system can respond to dynamic throughput demands with negligible latency compared to the standard baseline 5G IA scheme. The proposed fast beam selection scheme can enable the network to use energy-saving sleep modes without compromising the quality of service due to inefficient IA
Elevated LiDAR based Sensing for 6G -- 3D Maps with cm Level Accuracy
Feb 22, 2021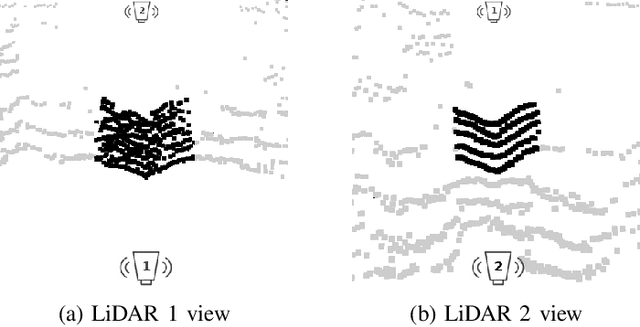
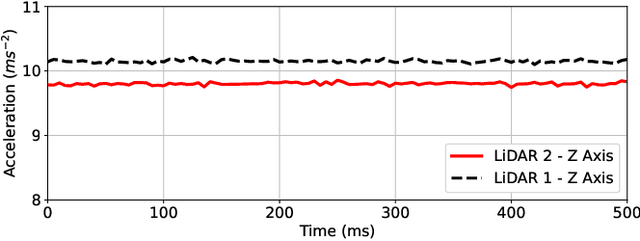

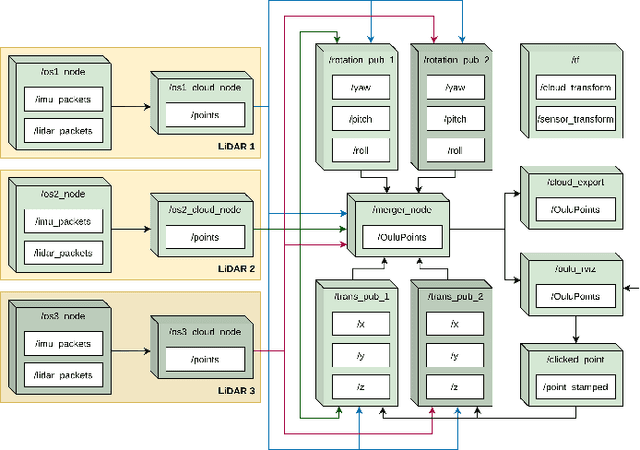
One key vertical application that will be enabled by 6G is the automation of the processes with the increased use of robots. As a result, sensing and localization of the surrounding environment becomes a crucial factor for these robots to operate. Light detection and ranging (LiDAR) has emerged as an appropriate method of sensing due to its capability of generating detail-rich information with high accuracy. However, LiDARs are power hungry devices that generate a lot of data, and these characteristics limit their use as on-board sensors in robots. In this paper, we present a novel approach on the methodology of generating an enhanced 3D map with improved field-of-view using multiple LiDAR sensors. We utilize an inherent property of LiDAR point clouds; rings and data from the inertial measurement unit (IMU) embedded in the sensor for registration of the point clouds. The generated 3D map has an accuracy of 10 cm when compared to the real-world measurements. We also carry out the practical implementation of the proposed method using two LiDAR sensors. Furthermore, we develop an application to utilize the generated map where a robot navigates through the mapped environment with minimal support from the sensors on-board. The LiDARs are fixed in the infrastructure at elevated positions. Thus this is applicable to vehicular and factory scenarios. Our results further validate the idea of using multiple elevated LiDARs as a part of the infrastructure for various applications.
Deep Learning-based Power Control for Cell-Free Massive MIMO Networks
Feb 20, 2021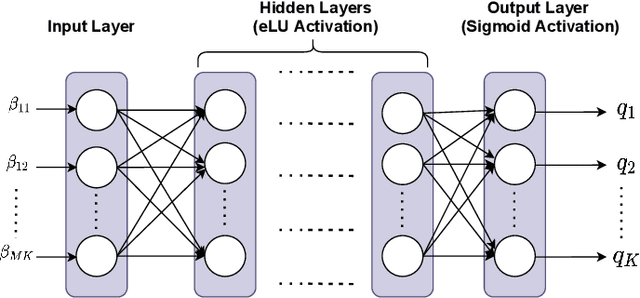
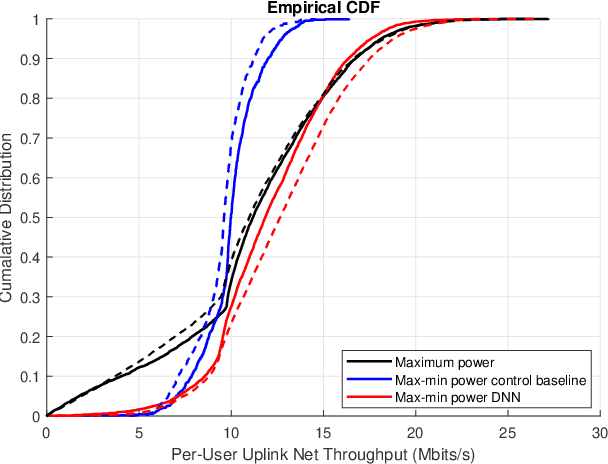
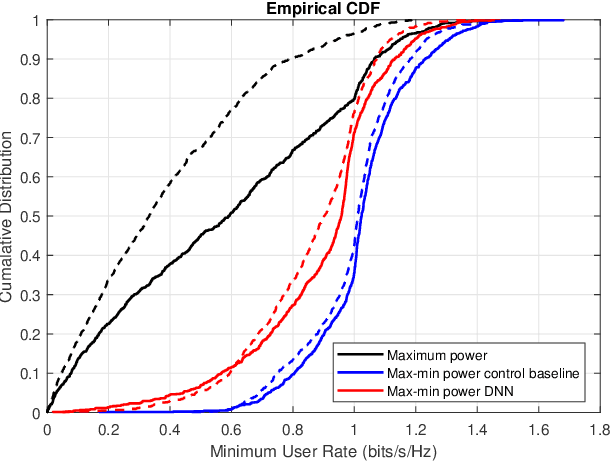
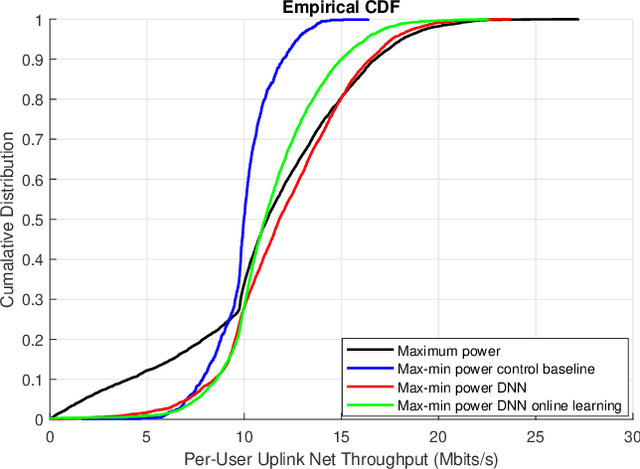
A deep learning (DL)-based power control algorithm that solves the max-min user fairness problem in a cell-free massive multiple-input multiple-output (MIMO) system is proposed. Max-min rate optimization problem in a cell-free massive MIMO uplink setup is formulated, where user power allocations are optimized in order to maximize the minimum user rate. Instead of modeling the problem using mathematical optimization theory, and solving it with iterative algorithms, our proposed solution approach is using DL. Specifically, we model a deep neural network (DNN) and train it in an unsupervised manner to learn the optimum user power allocations which maximize the minimum user rate. This novel unsupervised learning-based approach does not require optimal power allocations to be known during model training as in previously used supervised learning techniques, hence it has a simpler and flexible model training stage. Numerical results show that the proposed DNN achieves a performance-complexity trade-off with around 400 times faster implementation and comparable performance to the optimization-based algorithm. An online learning stage is also introduced, which results in near-optimal performance with 4-6 times faster processing.