 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeTMAS: Scaling Test-Time Compute via Multi-Agent Synergy
May 11, 2026Test-time scaling has become an effective paradigm for improving the reasoning ability of large language models by allocating additional computation during inference. Recent structured approaches have further advanced this paradigm by organizing inference across multiple trajectories, refinement rounds, and verification-based feedback. However, existing structured test-time scaling methods either weakly coordinate parallel reasoning trajectories or rely on noisy historical information without explicitly deciding what should be retained and reused, limiting their ability to balance exploration and exploitation. In this work, we propose TMAS, a framework for scaling test-time compute via multi-agent synergy. TMAS organizes inference as a collaborative process among specialized agents, enabling structured information flow across agents, trajectories, and refinement iterations. To support effective cross-trajectory collaboration, TMAS introduces hierarchical memories: the experience bank reuses low-level reliable intermediate conclusions and local feedback, while the guideline bank records previously explored high-level strategies to steer subsequent rollouts away from redundant reasoning patterns. Furthermore, we design a hybrid reward reinforcement learning scheme tailored to TMAS, which jointly preserves basic reasoning capability, enhances experience utilization, and encourages exploration beyond previously attempted solution strategies. Extensive experiments on challenging reasoning benchmarks demonstrate that TMAS achieves stronger iterative scaling than existing test-time scaling baselines, while hybrid reward training further improves scaling effectiveness and stability across iterations. Code and data are available at https://github.com/george-QF/TMAS-code.
Saiyan: Design and Implementation of a Low-power Demodulator for LoRa Backscatter Systems
Sep 30, 2022

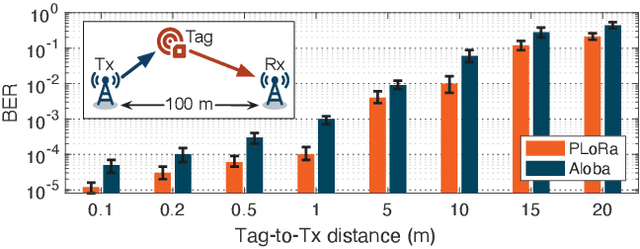

The radio range of backscatter systems continues growing as new wireless communication primitives are continuously invented. Nevertheless, both the bit error rate and the packet loss rate of backscatter signals increase rapidly with the radio range, thereby necessitating the cooperation between the access point and the backscatter tags through a feedback loop. Unfortunately, the low-power nature of backscatter tags limits their ability to demodulate feedback signals from a remote access point and scales down to such circumstances. This paper presents Saiyan, an ultra-low-power demodulator for long-range LoRa backscatter systems. With Saiyan, a backscatter tag can demodulate feedback signals from a remote access point with moderate power consumption and then perform an immediate packet retransmission in the presence of packet loss. Moreover, Saiyan enables rate adaption and channel hopping-two PHY-layer operations that are important to channel efficiency yet unavailable on long-range backscatter systems. We prototype Saiyan on a two-layer PCB board and evaluate its performance in different environments. Results show that Saiyan achieves 5 gain on the demodulation range, compared with state-of-the-art systems. Our ASIC simulation shows that the power consumption of Saiyan is around 93.2 uW. Code and hardware schematics can be found at: https://github.com/ZangJac/Saiyan.