 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeRolling the DICE on Idiomaticity: How LLMs Fail to Grasp Context
Oct 21, 2024



Human processing of idioms relies on understanding the contextual sentences in which idioms occur, as well as language-intrinsic features such as frequency and speaker-intrinsic factors like familiarity. While LLMs have shown high performance on idiomaticity detection tasks, this success may be attributed to reasoning shortcuts in existing datasets. To this end, we construct a novel, controlled contrastive dataset designed to test whether LLMs can effectively use context to disambiguate idiomatic meaning. Additionally, we explore how collocational frequency and sentence probability influence model performance. Our findings reveal that LLMs often fail to resolve idiomaticity when it is required to attend to the surrounding context, and that models perform better on sentences that have higher likelihood. The collocational frequency of expressions also impacts performance. We make our code and dataset publicly available.
How to Leverage Digit Embeddings to Represent Numbers?
Jul 01, 2024Apart from performing arithmetic operations, understanding numbers themselves is still a challenge for existing language models. Simple generalisations, such as solving 100+200 instead of 1+2, can substantially affect model performance (Sivakumar and Moosavi, 2023). Among various techniques, character-level embeddings of numbers have emerged as a promising approach to improve number representation. However, this method has limitations as it leaves the task of aggregating digit representations to the model, which lacks direct supervision for this process. In this paper, we explore the use of mathematical priors to compute aggregated digit embeddings and explicitly incorporate these aggregates into transformer models. This can be achieved either by adding a special token to the input embeddings or by introducing an additional loss function to enhance correct predictions. We evaluate the effectiveness of incorporating this explicit aggregation, analysing its strengths and shortcomings, and discuss future directions to better benefit from this approach. Our methods, while simple, are compatible with any pretrained model and require only a few lines of code, which we have made publicly available.
Decoding News Narratives: A Critical Analysis of Large Language Models in Framing Bias Detection
Feb 23, 2024This work contributes to the expanding research on the applicability of LLMs in social sciences by examining the performance of GPT-3.5 Turbo, GPT-4, and Flan-T5 models in detecting framing bias in news headlines through zero-shot, few-shot, and explainable prompting methods. A key insight from our evaluation is the notable efficacy of explainable prompting in enhancing the reliability of these models, highlighting the importance of explainable settings for social science research on framing bias. GPT-4, in particular, demonstrated enhanced performance in few-shot scenarios when presented with a range of relevant, in-domain examples. FLAN-T5's poor performance indicates that smaller models may require additional task-specific fine-tuning for identifying framing bias detection. Our study also found that models, particularly GPT-4, often misinterpret emotional language as an indicator of framing bias, underscoring the challenge of distinguishing between reporting genuine emotional expression and intentionally use framing bias in news headlines. We further evaluated the models on two subsets of headlines where the presence or absence of framing bias was either clear-cut or more contested, with the results suggesting that these models' can be useful in flagging potential annotation inaccuracies within existing or new datasets. Finally, the study evaluates the models in real-world conditions ("in the wild"), moving beyond the initial dataset focused on U.S. Gun Violence, assessing the models' performance on framed headlines covering a broad range of topics.
Beyond Hate Speech: NLP's Challenges and Opportunities in Uncovering Dehumanizing Language
Feb 21, 2024Dehumanization, characterized as a subtle yet harmful manifestation of hate speech, involves denying individuals of their human qualities and often results in violence against marginalized groups. Despite significant progress in Natural Language Processing across various domains, its application in detecting dehumanizing language is limited, largely due to the scarcity of publicly available annotated data for this domain. This paper evaluates the performance of cutting-edge NLP models, including GPT-4, GPT-3.5, and LLAMA-2, in identifying dehumanizing language. Our findings reveal that while these models demonstrate potential, achieving a 70\% accuracy rate in distinguishing dehumanizing language from broader hate speech, they also display biases. They are over-sensitive in classifying other forms of hate speech as dehumanization for a specific subset of target groups, while more frequently failing to identify clear cases of dehumanization for other target groups. Moreover, leveraging one of the best-performing models, we automatically annotated a larger dataset for training more accessible models. However, our findings indicate that these models currently do not meet the high-quality data generation threshold necessary for this task.
LLMs as Narcissistic Evaluators: When Ego Inflates Evaluation Scores
Nov 16, 2023



Automatic evaluation of generated textual content presents an ongoing challenge within the field of NLP. Given the impressive capabilities of modern language models (LMs) across diverse NLP tasks, there is a growing trend to employ these models in creating innovative evaluation metrics for automated assessment of generation tasks. This paper investigates a pivotal question: Do language model-driven evaluation metrics inherently exhibit bias favoring texts generated by the same underlying language model? Specifically, we assess whether prominent LM-based evaluation metrics--namely, BARTScore, T5Score, and GPTScore--demonstrate a favorable bias toward their respective underlying LMs in the context of summarization tasks. Our findings unveil a latent bias, particularly pronounced when such evaluation metrics are used in an reference-free manner without leveraging gold summaries. These results underscore that assessments provided by generative evaluation models can be influenced by factors beyond the inherent text quality, highlighting the necessity of developing more dependable evaluation protocols in the future.
Learning From Free-Text Human Feedback -- Collect New Datasets Or Extend Existing Ones?
Oct 24, 2023Learning from free-text human feedback is essential for dialog systems, but annotated data is scarce and usually covers only a small fraction of error types known in conversational AI. Instead of collecting and annotating new datasets from scratch, recent advances in synthetic dialog generation could be used to augment existing dialog datasets with the necessary annotations. However, to assess the feasibility of such an effort, it is important to know the types and frequency of free-text human feedback included in these datasets. In this work, we investigate this question for a variety of commonly used dialog datasets, including MultiWoZ, SGD, BABI, PersonaChat, Wizards-of-Wikipedia, and the human-bot split of the Self-Feeding Chatbot. Using our observations, we derive new taxonomies for the annotation of free-text human feedback in dialogs and investigate the impact of including such data in response generation for three SOTA language generation models, including GPT-2, LLAMA, and Flan-T5. Our findings provide new insights into the composition of the datasets examined, including error types, user response types, and the relations between them.
FERMAT: An Alternative to Accuracy for Numerical Reasoning
May 27, 2023While pre-trained language models achieve impressive performance on various NLP benchmarks, they still struggle with tasks that require numerical reasoning. Recent advances in improving numerical reasoning are mostly achieved using very large language models that contain billions of parameters and are not accessible to everyone. In addition, numerical reasoning is measured using a single score on existing datasets. As a result, we do not have a clear understanding of the strengths and shortcomings of existing models on different numerical reasoning aspects and therefore, potential ways to improve them apart from scaling them up. Inspired by CheckList (Ribeiro et al., 2020), we introduce a multi-view evaluation set for numerical reasoning in English, called FERMAT. Instead of reporting a single score on a whole dataset, FERMAT evaluates models on various key numerical reasoning aspects such as number understanding, mathematical operations, and training dependency. Apart from providing a comprehensive evaluation of models on different numerical reasoning aspects, FERMAT enables a systematic and automated generation of an arbitrarily large training or evaluation set for each aspect.The datasets and codes are publicly available to generate further multi-view data for ulterior tasks and languages.
Lessons Learned from a Citizen Science Project for Natural Language Processing
Apr 25, 2023



Many Natural Language Processing (NLP) systems use annotated corpora for training and evaluation. However, labeled data is often costly to obtain and scaling annotation projects is difficult, which is why annotation tasks are often outsourced to paid crowdworkers. Citizen Science is an alternative to crowdsourcing that is relatively unexplored in the context of NLP. To investigate whether and how well Citizen Science can be applied in this setting, we conduct an exploratory study into engaging different groups of volunteers in Citizen Science for NLP by re-annotating parts of a pre-existing crowdsourced dataset. Our results show that this can yield high-quality annotations and attract motivated volunteers, but also requires considering factors such as scalability, participation over time, and legal and ethical issues. We summarize lessons learned in the form of guidelines and provide our code and data to aid future work on Citizen Science.
Layer or Representation Space: What makes BERT-based Evaluation Metrics Robust?
Sep 07, 2022
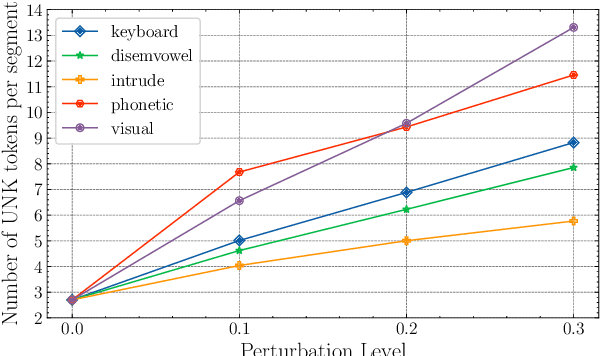
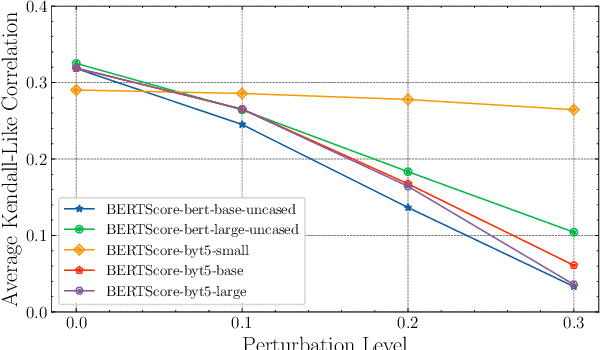
The evaluation of recent embedding-based evaluation metrics for text generation is primarily based on measuring their correlation with human evaluations on standard benchmarks. However, these benchmarks are mostly from similar domains to those used for pretraining word embeddings. This raises concerns about the (lack of) generalization of embedding-based metrics to new and noisy domains that contain a different vocabulary than the pretraining data. In this paper, we examine the robustness of BERTScore, one of the most popular embedding-based metrics for text generation. We show that (a) an embedding-based metric that has the highest correlation with human evaluations on a standard benchmark can have the lowest correlation if the amount of input noise or unknown tokens increases, (b) taking embeddings from the first layer of pretrained models improves the robustness of all metrics, and (c) the highest robustness is achieved when using character-level embeddings, instead of token-based embeddings, from the first layer of the pretrained model.
Transformers with Learnable Activation Functions
Sep 01, 2022
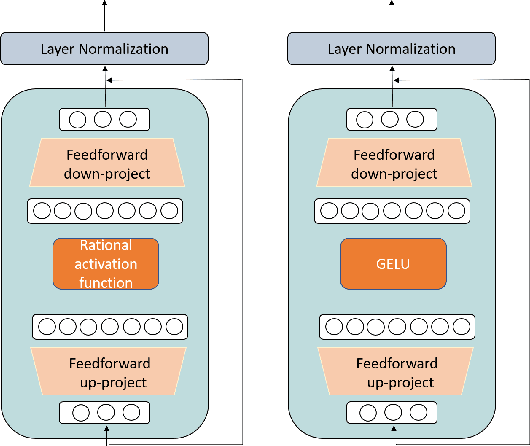

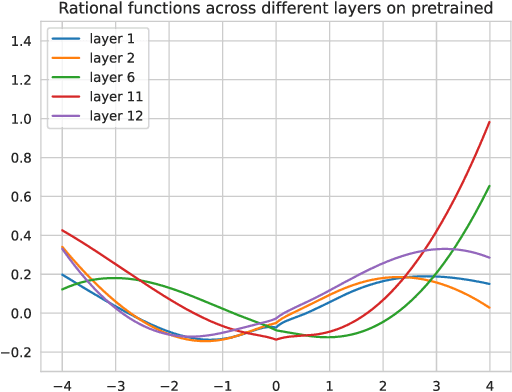
Activation functions can have a significant impact on reducing the topological complexity of input data and therefore improve the performance of the model. Selecting a suitable activation function is an essential step in neural model design. However, the choice of activation function is seldom discussed or explored in Transformer-based language models. Their activation functions are chosen beforehand and then remain fixed from pre-training to fine-tuning. As a result, the inductive biases they imposed on models cannot be adjusted during this long life cycle. Moreover, subsequently developed models (e.g., RoBERTa, BART, and GPT-3) often follow up prior work (e.g., BERT) to use the same activation function without justification. In this paper, we investigate the effectiveness of using Rational Activation Function (RAF), a learnable activation function, in the Transformer architecture. In contrast to conventional, predefined activation functions, RAFs can adaptively learn optimal activation functions during training according to input data. Our experiments show the RAF-based Transformer (RAFT) achieves a lower validation perplexity than a vanilla BERT with the GELU function. We further evaluate RAFT on downstream tasks in low- and full-data settings. Our results show that RAFT outperforms the counterpart model across the majority of tasks and settings. For instance, RAFT outperforms vanilla BERT on the GLUE benchmark by 5.71 points on average in low-data scenario (where 100 training examples are available) and by 2.05 points on SQuAD in full-data setting. Analysis of the shapes of learned RAFs further unveils that they substantially vary between different layers of the pre-trained model and mostly look very different from conventional activation functions. RAFT opens a new research direction for analyzing and interpreting pre-trained models according to the learned activation functions.