 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeThe Scaffold Effect: How Prompt Framing Drives Apparent Multimodal Gains in Clinical VLM Evaluation
Mar 30, 2026Trustworthy clinical AI requires that performance gains reflect genuine evidence integration rather than surface-level artifacts. We evaluate 12 open-weight vision-language models (VLMs) on binary classification across two clinical neuroimaging cohorts, \textsc{FOR2107} (affective disorders) and \textsc{OASIS-3} (cognitive decline). Both datasets come with structural MRI data that carries no reliable individual-level diagnostic signal. Under these conditions, smaller VLMs exhibit gains of up to 58\% F1 upon introduction of neuroimaging context, with distilled models becoming competitive with counterparts an order of magnitude larger. A contrastive confidence analysis reveals that merely \emph{mentioning} MRI availability in the task prompt accounts for 70-80\% of this shift, independent of whether imaging data is present, a domain-specific instance of modality collapse we term the \emph{scaffold effect}. Expert evaluation reveals fabrication of neuroimaging-grounded justifications across all conditions, and preference alignment, while eliminating MRI-referencing behavior, collapses both conditions toward random baseline. Our findings demonstrate that surface evaluations are inadequate indicators of multimodal reasoning, with direct implications for the deployment of VLMs in clinical settings.
A Course Shared Task on Evaluating LLM Output for Clinical Questions
Jul 31, 2024


This paper presents a shared task that we organized at the Foundations of Language Technology (FoLT) course in 2023/2024 at the Technical University of Darmstadt, which focuses on evaluating the output of Large Language Models (LLMs) in generating harmful answers to health-related clinical questions. We describe the task design considerations and report the feedback we received from the students. We expect the task and the findings reported in this paper to be relevant for instructors teaching natural language processing (NLP) and designing course assignments.
Granularity is crucial when applying differential privacy to text: An investigation for neural machine translation
Jul 26, 2024Applying differential privacy (DP) by means of the DP-SGD algorithm to protect individual data points during training is becoming increasingly popular in NLP. However, the choice of granularity at which DP is applied is often neglected. For example, neural machine translation (NMT) typically operates on the sentence-level granularity. From the perspective of DP, this setup assumes that each sentence belongs to a single person and any two sentences in the training dataset are independent. This assumption is however violated in many real-world NMT datasets, e.g. those including dialogues. For proper application of DP we thus must shift from sentences to entire documents. In this paper, we investigate NMT at both the sentence and document levels, analyzing the privacy/utility trade-off for both scenarios, and evaluating the risks of not using the appropriate privacy granularity in terms of leaking personally identifiable information (PII). Our findings indicate that the document-level NMT system is more resistant to membership inference attacks, emphasizing the significance of using the appropriate granularity when working with DP.
DP-NMT: Scalable Differentially-Private Machine Translation
Nov 24, 2023Neural machine translation (NMT) is a widely popular text generation task, yet there is a considerable research gap in the development of privacy-preserving NMT models, despite significant data privacy concerns for NMT systems. Differentially private stochastic gradient descent (DP-SGD) is a popular method for training machine learning models with concrete privacy guarantees; however, the implementation specifics of training a model with DP-SGD are not always clarified in existing models, with differing software libraries used and code bases not always being public, leading to reproducibility issues. To tackle this, we introduce DP-NMT, an open-source framework for carrying out research on privacy-preserving NMT with DP-SGD, bringing together numerous models, datasets, and evaluation metrics in one systematic software package. Our goal is to provide a platform for researchers to advance the development of privacy-preserving NMT systems, keeping the specific details of the DP-SGD algorithm transparent and intuitive to implement. We run a set of experiments on datasets from both general and privacy-related domains to demonstrate our framework in use. We make our framework publicly available and welcome feedback from the community.
Layer or Representation Space: What makes BERT-based Evaluation Metrics Robust?
Sep 07, 2022
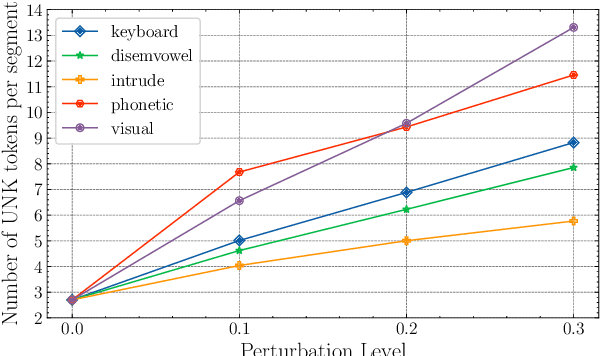
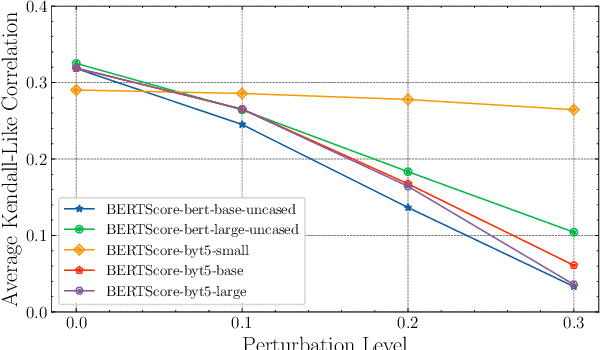
The evaluation of recent embedding-based evaluation metrics for text generation is primarily based on measuring their correlation with human evaluations on standard benchmarks. However, these benchmarks are mostly from similar domains to those used for pretraining word embeddings. This raises concerns about the (lack of) generalization of embedding-based metrics to new and noisy domains that contain a different vocabulary than the pretraining data. In this paper, we examine the robustness of BERTScore, one of the most popular embedding-based metrics for text generation. We show that (a) an embedding-based metric that has the highest correlation with human evaluations on a standard benchmark can have the lowest correlation if the amount of input noise or unknown tokens increases, (b) taking embeddings from the first layer of pretrained models improves the robustness of all metrics, and (c) the highest robustness is achieved when using character-level embeddings, instead of token-based embeddings, from the first layer of the pretrained model.