 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeTowards a Theory of Non-Log-Concave Sampling: First-Order Stationarity Guarantees for Langevin Monte Carlo
Feb 10, 2022For the task of sampling from a density $\pi \propto \exp(-V)$ on $\mathbb{R}^d$, where $V$ is possibly non-convex but $L$-gradient Lipschitz, we prove that averaged Langevin Monte Carlo outputs a sample with $\varepsilon$-relative Fisher information after $O( L^2 d^2/\varepsilon^2)$ iterations. This is the sampling analogue of complexity bounds for finding an $\varepsilon$-approximate first-order stationary points in non-convex optimization and therefore constitutes a first step towards the general theory of non-log-concave sampling. We discuss numerous extensions and applications of our result; in particular, it yields a new state-of-the-art guarantee for sampling from distributions which satisfy a Poincar\'e inequality.
Heavy-tailed Sampling via Transformed Unadjusted Langevin Algorithm
Jan 20, 2022
We analyze the oracle complexity of sampling from polynomially decaying heavy-tailed target densities based on running the Unadjusted Langevin Algorithm on certain transformed versions of the target density. The specific class of closed-form transformation maps that we construct are shown to be diffeomorphisms, and are particularly suited for developing efficient diffusion-based samplers. We characterize the precise class of heavy-tailed densities for which polynomial-order oracle complexities (in dimension and inverse target accuracy) could be obtained, and provide illustrative examples. We highlight the relationship between our assumptions and functional inequalities (super and weak Poincar\'e inequalities) based on non-local Dirichlet forms defined via fractional Laplacian operators, used to characterize the heavy-tailed equilibrium densities of certain stable-driven stochastic differential equations.
Analysis of Langevin Monte Carlo from Poincaré to Log-Sobolev
Dec 23, 2021

Classically, the continuous-time Langevin diffusion converges exponentially fast to its stationary distribution $\pi$ under the sole assumption that $\pi$ satisfies a Poincar\'e inequality. Using this fact to provide guarantees for the discrete-time Langevin Monte Carlo (LMC) algorithm, however, is considerably more challenging due to the need for working with chi-squared or R\'enyi divergences, and prior works have largely focused on strongly log-concave targets. In this work, we provide the first convergence guarantees for LMC assuming that $\pi$ satisfies either a Lata{\l}a--Oleszkiewicz or modified log-Sobolev inequality, which interpolates between the Poincar\'e and log-Sobolev settings. Unlike prior works, our results allow for weak smoothness and do not require convexity or dissipativity conditions.
On Empirical Risk Minimization with Dependent and Heavy-Tailed Data
Sep 10, 2021In this work, we establish risk bounds for the Empirical Risk Minimization (ERM) with both dependent and heavy-tailed data-generating processes. We do so by extending the seminal works of Mendelson [Men15, Men18] on the analysis of ERM with heavy-tailed but independent and identically distributed observations, to the strictly stationary exponentially $\beta$-mixing case. Our analysis is based on explicitly controlling the multiplier process arising from the interaction between the noise and the function evaluations on inputs. It allows for the interaction to be even polynomially heavy-tailed, which covers a significantly large class of heavy-tailed models beyond what is analyzed in the learning theory literature. We illustrate our results by deriving rates of convergence for the high-dimensional linear regression problem with dependent and heavy-tailed data.
Fractal Structure and Generalization Properties of Stochastic Optimization Algorithms
Jun 09, 2021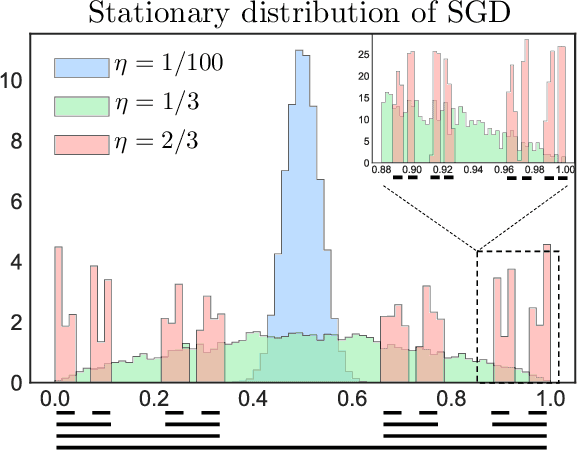
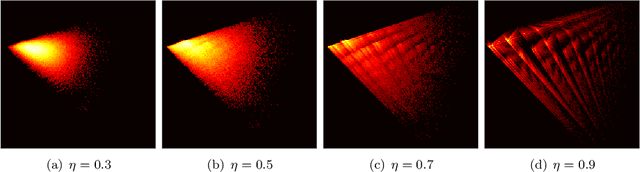
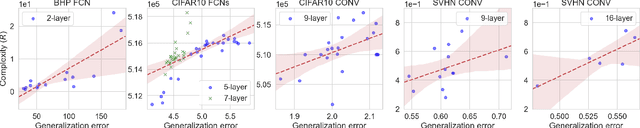
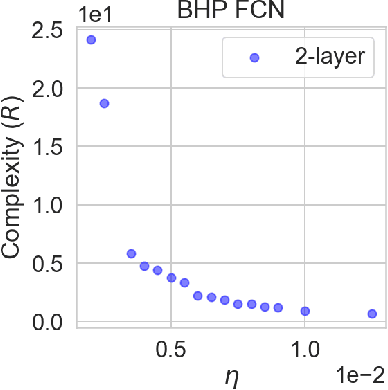
Understanding generalization in deep learning has been one of the major challenges in statistical learning theory over the last decade. While recent work has illustrated that the dataset and the training algorithm must be taken into account in order to obtain meaningful generalization bounds, it is still theoretically not clear which properties of the data and the algorithm determine the generalization performance. In this study, we approach this problem from a dynamical systems theory perspective and represent stochastic optimization algorithms as random iterated function systems (IFS). Well studied in the dynamical systems literature, under mild assumptions, such IFSs can be shown to be ergodic with an invariant measure that is often supported on sets with a fractal structure. As our main contribution, we prove that the generalization error of a stochastic optimization algorithm can be bounded based on the `complexity' of the fractal structure that underlies its invariant measure. Leveraging results from dynamical systems theory, we show that the generalization error can be explicitly linked to the choice of the algorithm (e.g., stochastic gradient descent -- SGD), algorithm hyperparameters (e.g., step-size, batch-size), and the geometry of the problem (e.g., Hessian of the loss). We further specialize our results to specific problems (e.g., linear/logistic regression, one hidden-layered neural networks) and algorithms (e.g., SGD and preconditioned variants), and obtain analytical estimates for our bound.For modern neural networks, we develop an efficient algorithm to compute the developed bound and support our theory with various experiments on neural networks.
Heavy Tails in SGD and Compressibility of Overparametrized Neural Networks
Jun 07, 2021
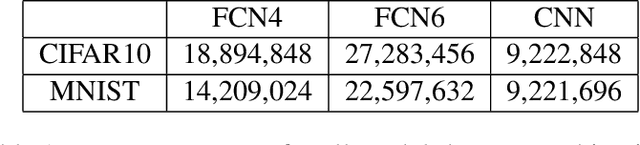

Neural network compression techniques have become increasingly popular as they can drastically reduce the storage and computation requirements for very large networks. Recent empirical studies have illustrated that even simple pruning strategies can be surprisingly effective, and several theoretical studies have shown that compressible networks (in specific senses) should achieve a low generalization error. Yet, a theoretical characterization of the underlying cause that makes the networks amenable to such simple compression schemes is still missing. In this study, we address this fundamental question and reveal that the dynamics of the training algorithm has a key role in obtaining such compressible networks. Focusing our attention on stochastic gradient descent (SGD), our main contribution is to link compressibility to two recently established properties of SGD: (i) as the network size goes to infinity, the system can converge to a mean-field limit, where the network weights behave independently, (ii) for a large step-size/batch-size ratio, the SGD iterates can converge to a heavy-tailed stationary distribution. In the case where these two phenomena occur simultaneously, we prove that the networks are guaranteed to be '$\ell_p$-compressible', and the compression errors of different pruning techniques (magnitude, singular value, or node pruning) become arbitrarily small as the network size increases. We further prove generalization bounds adapted to our theoretical framework, which indeed confirm that the generalization error will be lower for more compressible networks. Our theory and numerical study on various neural networks show that large step-size/batch-size ratios introduce heavy-tails, which, in combination with overparametrization, result in compressibility.
Manipulating SGD with Data Ordering Attacks
Apr 19, 2021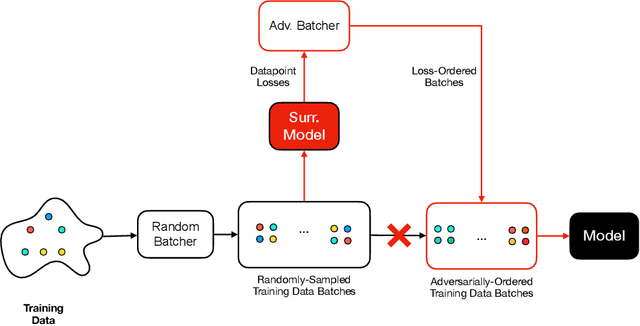
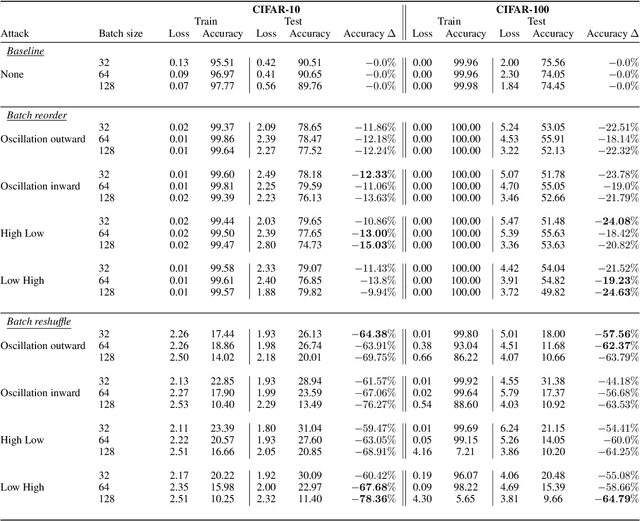
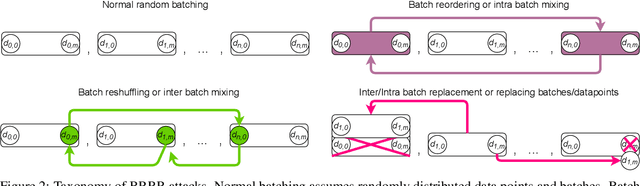
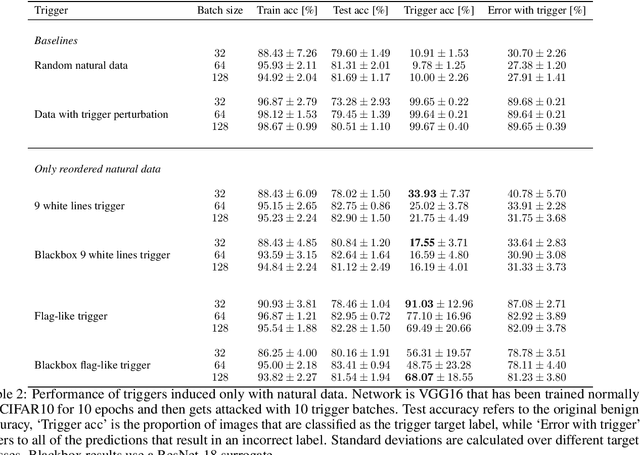
Machine learning is vulnerable to a wide variety of different attacks. It is now well understood that by changing the underlying data distribution, an adversary can poison the model trained with it or introduce backdoors. In this paper we present a novel class of training-time attacks that require no changes to the underlying model dataset or architecture, but instead only change the order in which data are supplied to the model. In particular, an attacker can disrupt the integrity and availability of a model by simply reordering training batches, with no knowledge about either the model or the dataset. Indeed, the attacks presented here are not specific to the model or dataset, but rather target the stochastic nature of modern learning procedures. We extensively evaluate our attacks to find that the adversary can disrupt model training and even introduce backdoors. For integrity we find that the attacker can either stop the model from learning, or poison it to learn behaviours specified by the attacker. For availability we find that a single adversarially-ordered epoch can be enough to slow down model learning, or even to reset all of the learning progress. Such attacks have a long-term impact in that they decrease model performance hundreds of epochs after the attack took place. Reordering is a very powerful adversarial paradigm in that it removes the assumption that an adversary must inject adversarial data points or perturbations to perform training-time attacks. It reminds us that stochastic gradient descent relies on the assumption that data are sampled at random. If this randomness is compromised, then all bets are off.
Convergence Rates of Stochastic Gradient Descent under Infinite Noise Variance
Feb 20, 2021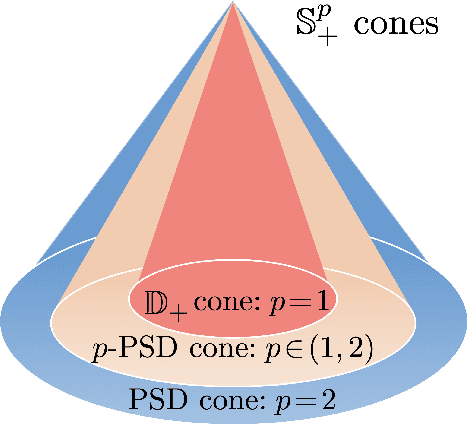
Recent studies have provided both empirical and theoretical evidence illustrating that heavy tails can emerge in stochastic gradient descent (SGD) in various scenarios. Such heavy tails potentially result in iterates with diverging variance, which hinders the use of conventional convergence analysis techniques that rely on the existence of the second-order moments. In this paper, we provide convergence guarantees for SGD under a state-dependent and heavy-tailed noise with a potentially infinite variance, for a class of strongly convex objectives. In the case where the $p$-th moment of the noise exists for some $p\in [1,2)$, we first identify a condition on the Hessian, coined '$p$-positive (semi-)definiteness', that leads to an interesting interpolation between positive semi-definite matrices ($p=2$) and diagonally dominant matrices with non-negative diagonal entries ($p=1$). Under this condition, we then provide a convergence rate for the distance to the global optimum in $L^p$. Furthermore, we provide a generalized central limit theorem, which shows that the properly scaled Polyak-Ruppert averaging converges weakly to a multivariate $\alpha$-stable random vector. Our results indicate that even under heavy-tailed noise with infinite variance, SGD can converge to the global optimum without necessitating any modification neither to the loss function or to the algorithm itself, as typically required in robust statistics. We demonstrate the implications of our results to applications such as linear regression and generalized linear models subject to heavy-tailed data.
On the Ergodicity, Bias and Asymptotic Normality of Randomized Midpoint Sampling Method
Nov 06, 2020The randomized midpoint method, proposed by [SL19], has emerged as an optimal discretization procedure for simulating the continuous time Langevin diffusions. Focusing on the case of strong-convex and smooth potentials, in this paper, we analyze several probabilistic properties of the randomized midpoint discretization method for both overdamped and underdamped Langevin diffusions. We first characterize the stationary distribution of the discrete chain obtained with constant step-size discretization and show that it is biased away from the target distribution. Notably, the step-size needs to go to zero to obtain asymptotic unbiasedness. Next, we establish the asymptotic normality for numerical integration using the randomized midpoint method and highlight the relative advantages and disadvantages over other discretizations. Our results collectively provide several insights into the behavior of the randomized midpoint discretization method, including obtaining confidence intervals for numerical integrations.
Riemannian Langevin Algorithm for Solving Semidefinite Programs
Oct 22, 2020
We propose a Langevin diffusion-based algorithm for non-convex optimization and sampling on a product manifold of spheres. Under a logarithmic Sobolev inequality, we establish a guarantee for finite iteration convergence to the Gibbs distribution in terms of Kullback-Leibler divergence. We show that with an appropriate temperature choice, the suboptimality gap to the global minimum is guaranteed to be arbitrarily small with high probability. As an application, we analyze the proposed Langevin algorithm for solving the Burer-Monteiro relaxation of a semidefinite program (SDP). In particular, we establish a logarithmic Sobolev inequality for the Burer-Monteiro problem when there are no spurious local minima; hence implying a fast escape from saddle points. Combining the results, we then provide a global optimality guarantee for the SDP and the Max-Cut problem. More precisely, we show the Langevin algorithm achieves $\epsilon$-multiplicative accuracy with high probability in $\widetilde{\Omega}( n^2 \epsilon^{-3} )$ iterations, where $n$ is the size of the cost matrix.