 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeFrom Federated Learning to Fog Learning: Towards Large-Scale Distributed Machine Learning in Heterogeneous Wireless Networks
Jun 07, 2020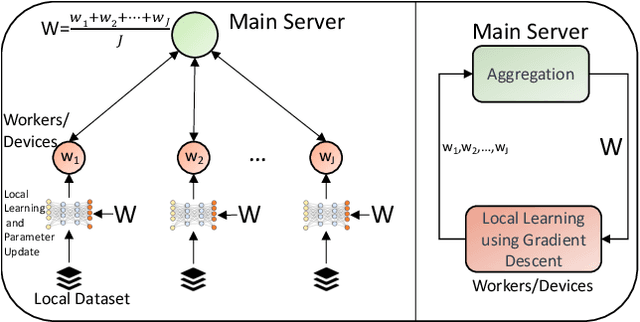


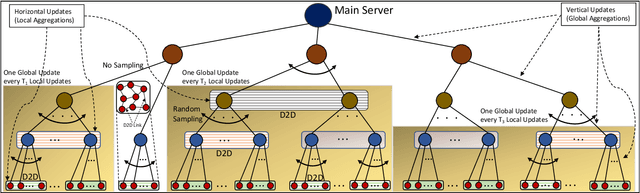
Contemporary network architectures are pushing computing tasks from the cloud towards the network edge, leveraging the increased processing capabilities of edge devices to meet rising user demands. Of particular importance are machine learning (ML) tasks, which are becoming ubiquitous in networked applications ranging from content recommendation systems to intelligent vehicular communications. Federated learning has emerged recently as a technique for training ML models by leveraging processing capabilities across the nodes that collect the data. There are several challenges with employing federated learning at the edge, however, due to the significant heterogeneity in compute and communication capabilities that exist across devices. To address this, we advocate a new learning paradigm called {fog learning which will intelligently distribute ML model training across the fog, the continuum of nodes from edge devices to cloud servers. Fog learning is inherently a multi-stage learning framework that breaks down the aggregations of heterogeneous local models across several layers and can leverage data offloading within each layer. Its hybrid learning paradigm transforms star network topologies used for parameter transfers in federated learning to more distributed topologies. We also discuss several open research directions for fog learning.
AppStreamer: Reducing Storage Requirements of Mobile Games through Predictive Streaming
Dec 16, 2019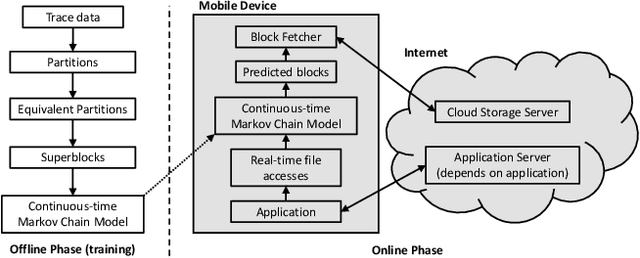
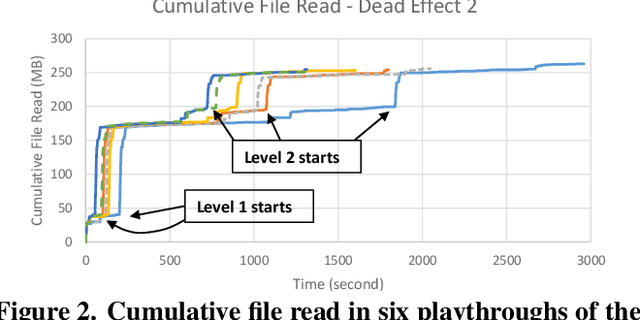
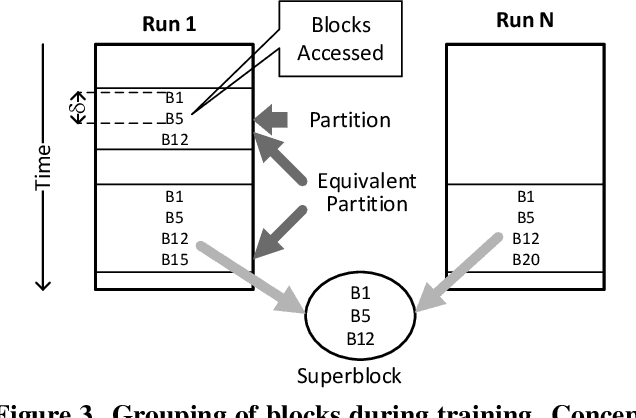
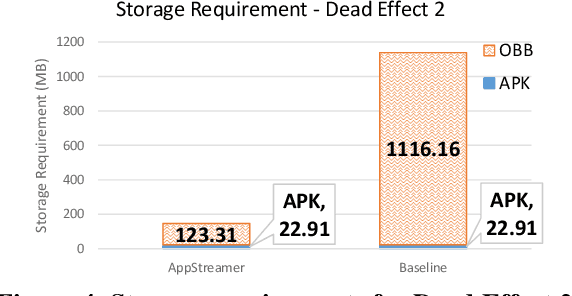
Storage has become a constrained resource on smartphones. Gaming is a popular activity on mobile devices and the explosive growth in the number of games coupled with their growing size contributes to the storage crunch. Even where storage is plentiful, it takes a long time to download and install a heavy app before it can be launched. This paper presents AppStreamer, a novel technique for reducing the storage requirements or startup delay of mobile games, and heavy mobile apps in general. AppStreamer is based on the intuition that most apps do not need the entirety of its files (images, audio and video clips, etc.) at any one time. AppStreamer can, therefore, keep only a small part of the files on the device, akin to a "cache", and download the remainder from a cloud storage server or a nearby edge server when it predicts that the app will need them in the near future. AppStreamer continuously predicts file blocks for the near future as the user uses the app, and fetches them from the storage server before the user sees a stall due to missing resources. We implement AppStreamer at the Android file system layer. This ensures that the apps require no source code or modification, and the approach generalizes across apps. We evaluate AppStreamer using two popular games: Dead Effect 2, a 3D first-person shooter, and Fire Emblem Heroes, a 2D turn-based strategy role-playing game. Through a user study, 75% and 87% of the users respectively find that AppStreamer provides the same quality of user experience as the baseline where all files are stored on the device. AppStreamer cuts down the storage requirement by 87% for Dead Effect 2 and 86% for Fire Emblem Heroes.
Better the Devil you Know: An Analysis of Evasion Attacks using Out-of-Distribution Adversarial Examples
May 05, 2019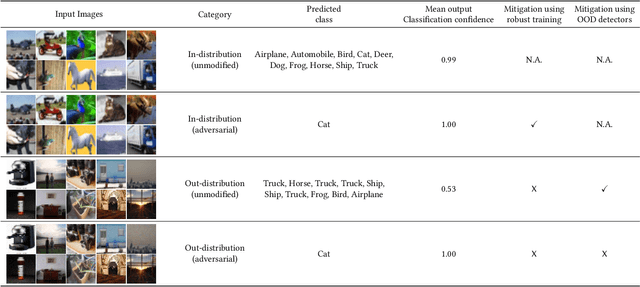
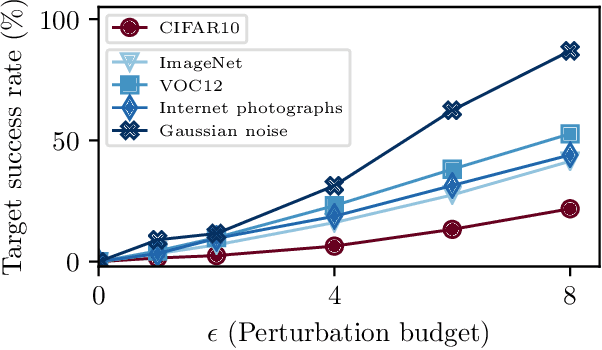
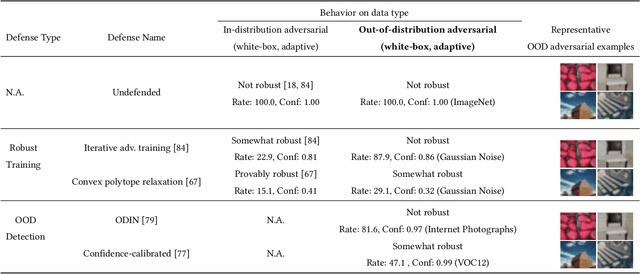
A large body of recent work has investigated the phenomenon of evasion attacks using adversarial examples for deep learning systems, where the addition of norm-bounded perturbations to the test inputs leads to incorrect output classification. Previous work has investigated this phenomenon in closed-world systems where training and test inputs follow a pre-specified distribution. However, real-world implementations of deep learning applications, such as autonomous driving and content classification are likely to operate in the open-world environment. In this paper, we demonstrate the success of open-world evasion attacks, where adversarial examples are generated from out-of-distribution inputs (OOD adversarial examples). In our study, we use 11 state-of-the-art neural network models trained on 3 image datasets of varying complexity. We first demonstrate that state-of-the-art detectors for out-of-distribution data are not robust against OOD adversarial examples. We then consider 5 known defenses for adversarial examples, including state-of-the-art robust training methods, and show that against these defenses, OOD adversarial examples can achieve up to 4$\times$ higher target success rates compared to adversarial examples generated from in-distribution data. We also take a quantitative look at how open-world evasion attacks may affect real-world systems. Finally, we present the first steps towards a robust open-world machine learning system.
An Estimation and Analysis Framework for the Rasch Model
Jun 09, 2018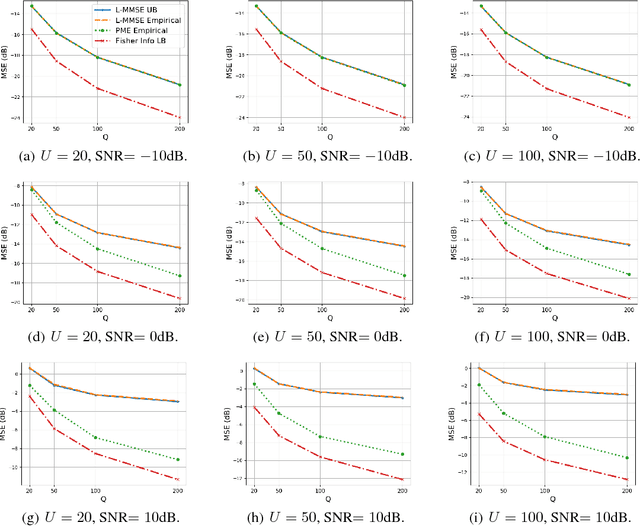
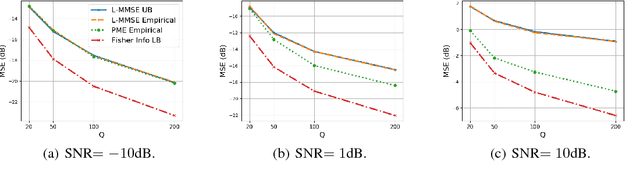
The Rasch model is widely used for item response analysis in applications ranging from recommender systems to psychology, education, and finance. While a number of estimators have been proposed for the Rasch model over the last decades, the available analytical performance guarantees are mostly asymptotic. This paper provides a framework that relies on a novel linear minimum mean-squared error (L-MMSE) estimator which enables an exact, nonasymptotic, and closed-form analysis of the parameter estimation error under the Rasch model. The proposed framework provides guidelines on the number of items and responses required to attain low estimation errors in tests or surveys. We furthermore demonstrate its efficacy on a number of real-world collaborative filtering datasets, which reveals that the proposed L-MMSE estimator performs on par with state-of-the-art nonlinear estimators in terms of predictive performance.
DARTS: Deceiving Autonomous Cars with Toxic Signs
May 31, 2018

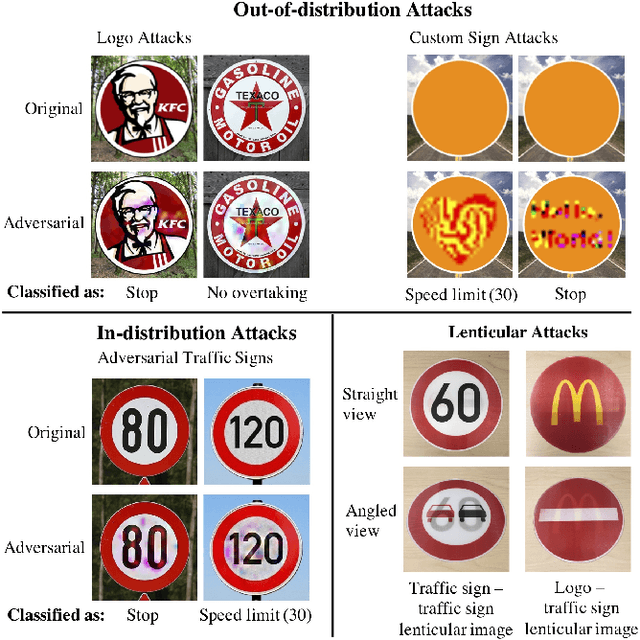

Sign recognition is an integral part of autonomous cars. Any misclassification of traffic signs can potentially lead to a multitude of disastrous consequences, ranging from a life-threatening accident to even a large-scale interruption of transportation services relying on autonomous cars. In this paper, we propose and examine security attacks against sign recognition systems for Deceiving Autonomous caRs with Toxic Signs (we call the proposed attacks DARTS). In particular, we introduce two novel methods to create these toxic signs. First, we propose Out-of-Distribution attacks, which expand the scope of adversarial examples by enabling the adversary to generate these starting from an arbitrary point in the image space compared to prior attacks which are restricted to existing training/test data (In-Distribution). Second, we present the Lenticular Printing attack, which relies on an optical phenomenon to deceive the traffic sign recognition system. We extensively evaluate the effectiveness of the proposed attacks in both virtual and real-world settings and consider both white-box and black-box threat models. Our results demonstrate that the proposed attacks are successful under both settings and threat models. We further show that Out-of-Distribution attacks can outperform In-Distribution attacks on classifiers defended using the adversarial training defense, exposing a new attack vector for these defenses.
Rogue Signs: Deceiving Traffic Sign Recognition with Malicious Ads and Logos
Mar 26, 2018
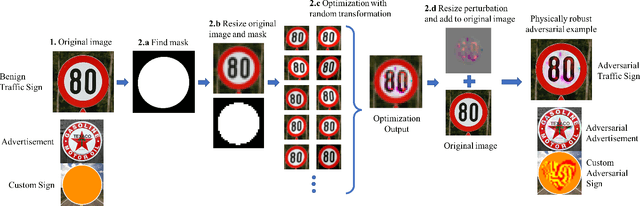
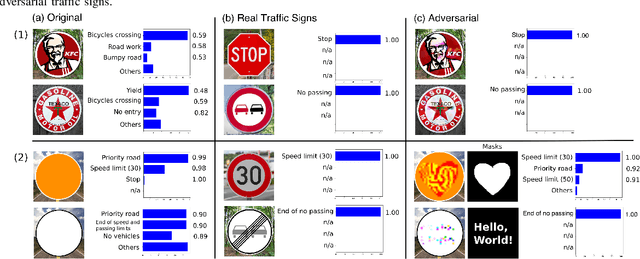

We propose a new real-world attack against the computer vision based systems of autonomous vehicles (AVs). Our novel Sign Embedding attack exploits the concept of adversarial examples to modify innocuous signs and advertisements in the environment such that they are classified as the adversary's desired traffic sign with high confidence. Our attack greatly expands the scope of the threat posed to AVs since adversaries are no longer restricted to just modifying existing traffic signs as in previous work. Our attack pipeline generates adversarial samples which are robust to the environmental conditions and noisy image transformations present in the physical world. We ensure this by including a variety of possible image transformations in the optimization problem used to generate adversarial samples. We verify the robustness of the adversarial samples by printing them out and carrying out drive-by tests simulating the conditions under which image capture would occur in a real-world scenario. We experimented with physical attack samples for different distances, lighting conditions and camera angles. In addition, extensive evaluations were carried out in the virtual setting for a variety of image transformations. The adversarial samples generated using our method have adversarial success rates in excess of 95% in the physical as well as virtual settings.
Linearized Binary Regression
Feb 01, 2018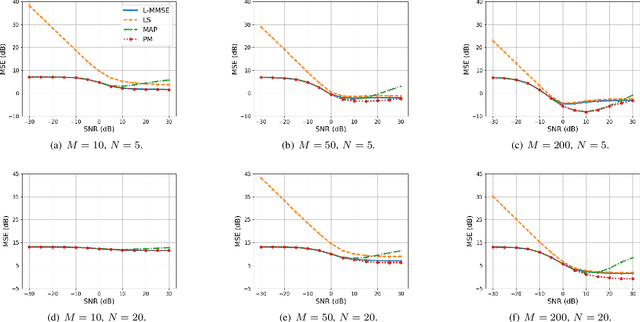
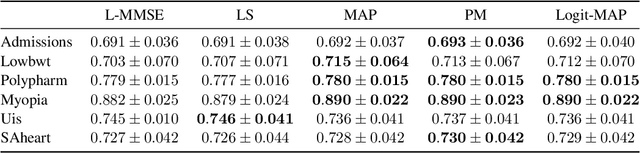
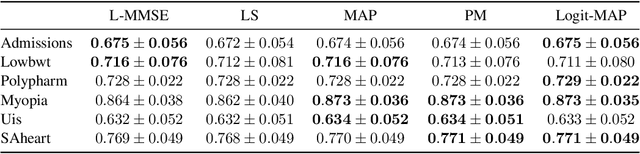
Probit regression was first proposed by Bliss in 1934 to study mortality rates of insects. Since then, an extensive body of work has analyzed and used probit or related binary regression methods (such as logistic regression) in numerous applications and fields. This paper provides a fresh angle to such well-established binary regression methods. Concretely, we demonstrate that linearizing the probit model in combination with linear estimators performs on par with state-of-the-art nonlinear regression methods, such as posterior mean or maximum aposteriori estimation, for a broad range of real-world regression problems. We derive exact, closed-form, and nonasymptotic expressions for the mean-squared error of our linearized estimators, which clearly separates them from nonlinear regression methods that are typically difficult to analyze. We showcase the efficacy of our methods and results for a number of synthetic and real-world datasets, which demonstrates that linearized binary regression finds potential use in a variety of inference, estimation, signal processing, and machine learning applications that deal with binary-valued observations or measurements.
Stock Market Prediction from WSJ: Text Mining via Sparse Matrix Factorization
Jun 27, 2014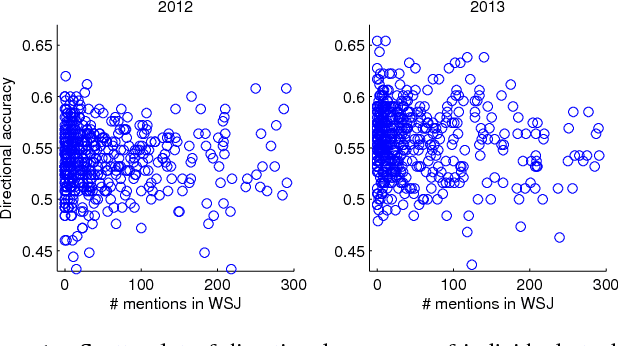
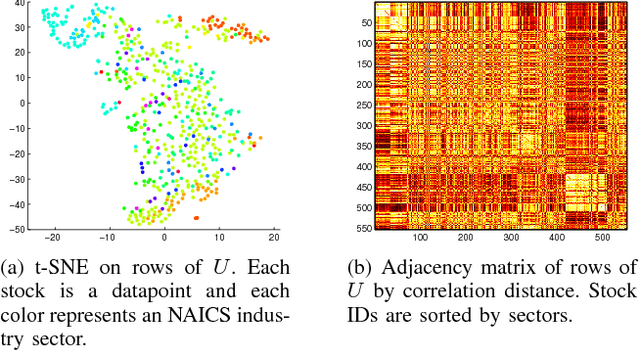
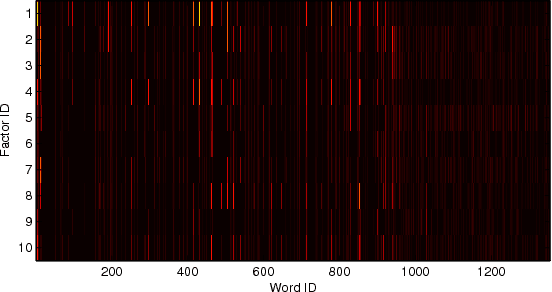
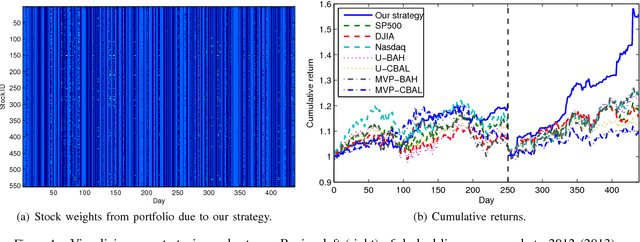
We revisit the problem of predicting directional movements of stock prices based on news articles: here our algorithm uses daily articles from The Wall Street Journal to predict the closing stock prices on the same day. We propose a unified latent space model to characterize the "co-movements" between stock prices and news articles. Unlike many existing approaches, our new model is able to simultaneously leverage the correlations: (a) among stock prices, (b) among news articles, and (c) between stock prices and news articles. Thus, our model is able to make daily predictions on more than 500 stocks (most of which are not even mentioned in any news article) while having low complexity. We carry out extensive backtesting on trading strategies based on our algorithm. The result shows that our model has substantially better accuracy rate (55.7%) compared to many widely used algorithms. The return (56%) and Sharpe ratio due to a trading strategy based on our model are also much higher than baseline indices.