 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeHostility Detection in UK Politics: A Dataset on Online Abuse Targeting MPs
Dec 05, 2024



Numerous politicians use social media platforms, particularly X, to engage with their constituents. This interaction allows constituents to pose questions and offer feedback but also exposes politicians to a barrage of hostile responses, especially given the anonymity afforded by social media. They are typically targeted in relation to their governmental role, but the comments also tend to attack their personal identity. This can discredit politicians and reduce public trust in the government. It can also incite anger and disrespect, leading to offline harm and violence. While numerous models exist for detecting hostility in general, they lack the specificity required for political contexts. Furthermore, addressing hostility towards politicians demands tailored approaches due to the distinct language and issues inherent to each country (e.g., Brexit for the UK). To bridge this gap, we construct a dataset of 3,320 English tweets spanning a two-year period manually annotated for hostility towards UK MPs. Our dataset also captures the targeted identity characteristics (race, gender, religion, none) in hostile tweets. We perform linguistic and topical analyses to delve into the unique content of the UK political data. Finally, we evaluate the performance of pre-trained language models and large language models on binary hostility detection and multi-class targeted identity type classification tasks. Our study offers valuable data and insights for future research on the prevalence and nature of politics-related hostility specific to the UK.
Exploring the Influence of Label Aggregation on Minority Voices: Implications for Dataset Bias and Model Training
Dec 05, 2024



Resolving disagreement in manual annotation typically consists of removing unreliable annotators and using a label aggregation strategy such as majority vote or expert opinion to resolve disagreement. These may have the side-effect of silencing or under-representing minority but equally valid opinions. In this paper, we study the impact of standard label aggregation strategies on minority opinion representation in sexism detection. We investigate the quality and value of minority annotations, and then examine their effect on the class distributions in gold labels, as well as how this affects the behaviour of models trained on the resulting datasets. Finally, we discuss the potential biases introduced by each method and how they can be amplified by the models.
Dimensions of Online Conflict: Towards Modeling Agonism
Nov 06, 2023



Agonism plays a vital role in democratic dialogue by fostering diverse perspectives and robust discussions. Within the realm of online conflict there is another type: hateful antagonism, which undermines constructive dialogue. Detecting conflict online is central to platform moderation and monetization. It is also vital for democratic dialogue, but only when it takes the form of agonism. To model these two types of conflict, we collected Twitter conversations related to trending controversial topics. We introduce a comprehensive annotation schema for labelling different dimensions of conflict in the conversations, such as the source of conflict, the target, and the rhetorical strategies deployed. Using this schema, we annotated approximately 4,000 conversations with multiple labels. We then trained both logistic regression and transformer-based models on the dataset, incorporating context from the conversation, including the number of participants and the structure of the interactions. Results show that contextual labels are helpful in identifying conflict and make the models robust to variations in topic. Our research contributes a conceptualization of different dimensions of conflict, a richly annotated dataset, and promising results that can contribute to content moderation.
* To appear
Alexa, Google, Siri: What are Your Pronouns? Gender and Anthropomorphism in the Design and Perception of Conversational Assistants
Jun 04, 2021

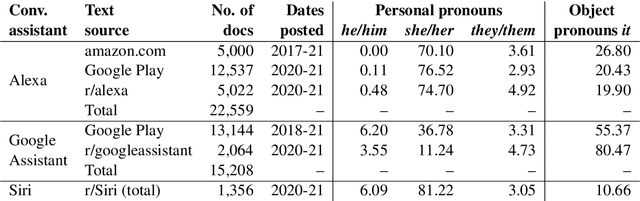
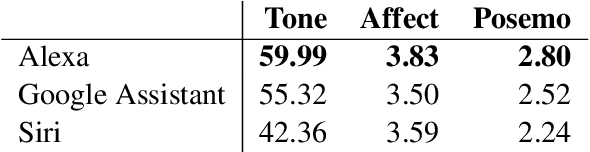
Technology companies have produced varied responses to concerns about the effects of the design of their conversational AI systems. Some have claimed that their voice assistants are in fact not gendered or human-like -- despite design features suggesting the contrary. We compare these claims to user perceptions by analysing the pronouns they use when referring to AI assistants. We also examine systems' responses and the extent to which they generate output which is gendered and anthropomorphic. We find that, while some companies appear to be addressing the ethical concerns raised, in some cases, their claims do not seem to hold true. In particular, our results show that system outputs are ambiguous as to the humanness of the systems, and that users tend to personify and gender them as a result.
Intrinsic Bias Metrics Do Not Correlate with Application Bias
Jan 02, 2021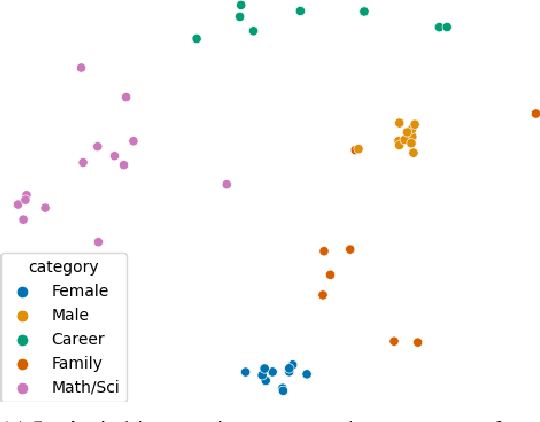

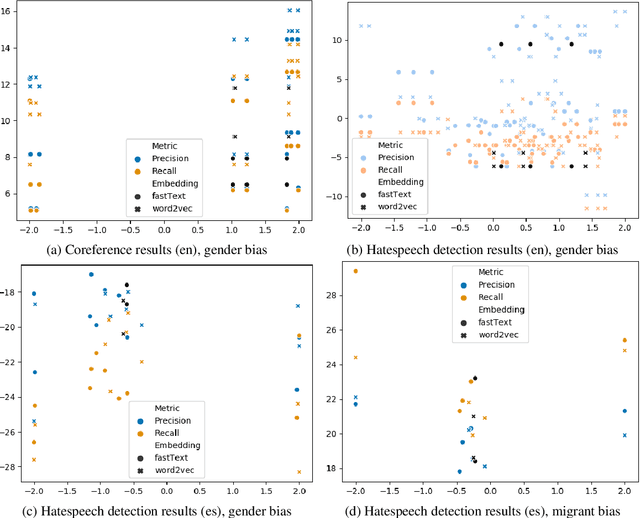
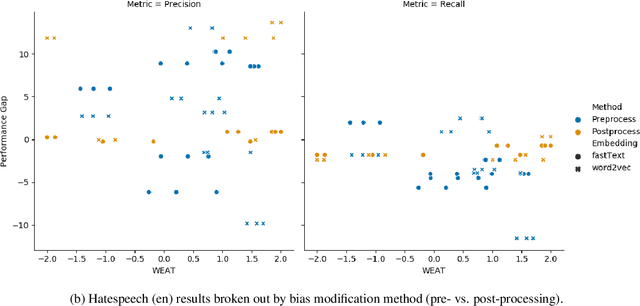
Natural Language Processing (NLP) systems learn harmful societal biases that cause them to widely proliferate inequality as they are deployed in more and more situations. To address and combat this, the NLP community relies on a variety of metrics to identify and quantify bias in black-box models and to guide efforts at debiasing. Some of these metrics are intrinsic, and are measured in word embedding spaces, and some are extrinsic, which measure the bias present downstream in the tasks that the word embeddings are plugged into. This research examines whether easy-to-measure intrinsic metrics correlate well to real world extrinsic metrics. We measure both intrinsic and extrinsic bias across hundreds of trained models covering different tasks and experimental conditions and find that there is no reliable correlation between these metrics that holds in all scenarios across tasks and languages. We advise that efforts to debias embedding spaces be always also paired with measurement of downstream model bias, and suggest that that community increase effort into making downstream measurement more feasible via creation of additional challenge sets and annotated test data. We additionally release code, a new intrinsic metric, and an annotated test set for gender bias for hatespeech.