 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeIntrinsic Bias Metrics Do Not Correlate with Application Bias
Jan 02, 2021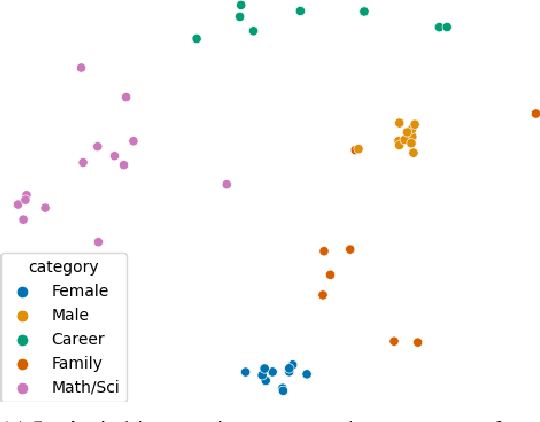

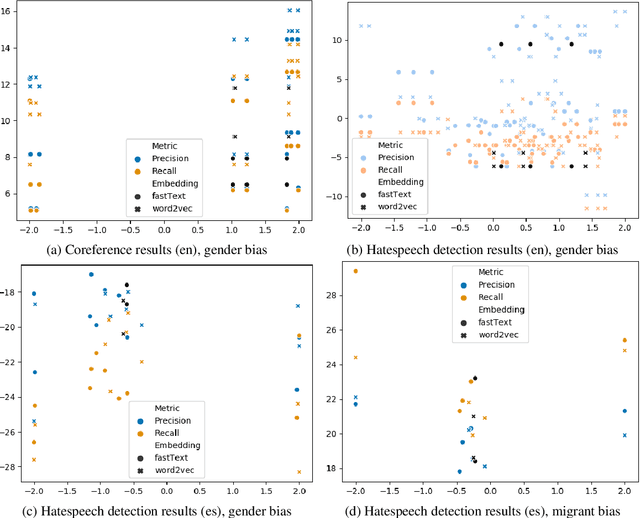
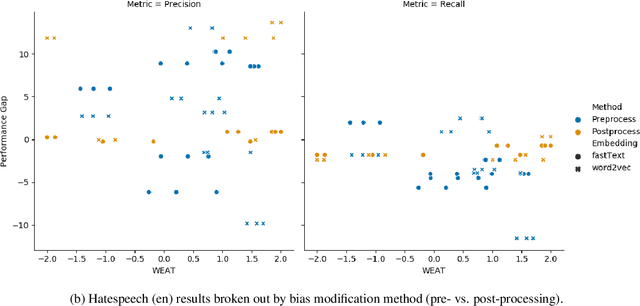
Natural Language Processing (NLP) systems learn harmful societal biases that cause them to widely proliferate inequality as they are deployed in more and more situations. To address and combat this, the NLP community relies on a variety of metrics to identify and quantify bias in black-box models and to guide efforts at debiasing. Some of these metrics are intrinsic, and are measured in word embedding spaces, and some are extrinsic, which measure the bias present downstream in the tasks that the word embeddings are plugged into. This research examines whether easy-to-measure intrinsic metrics correlate well to real world extrinsic metrics. We measure both intrinsic and extrinsic bias across hundreds of trained models covering different tasks and experimental conditions and find that there is no reliable correlation between these metrics that holds in all scenarios across tasks and languages. We advise that efforts to debias embedding spaces be always also paired with measurement of downstream model bias, and suggest that that community increase effort into making downstream measurement more feasible via creation of additional challenge sets and annotated test data. We additionally release code, a new intrinsic metric, and an annotated test set for gender bias for hatespeech.