 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeWhen Do Curricula Work in Federated Learning?
Dec 24, 2022



An oft-cited open problem of federated learning is the existence of data heterogeneity at the clients. One pathway to understanding the drastic accuracy drop in federated learning is by scrutinizing the behavior of the clients' deep models on data with different levels of "difficulty", which has been left unaddressed. In this paper, we investigate a different and rarely studied dimension of FL: ordered learning. Specifically, we aim to investigate how ordered learning principles can contribute to alleviating the heterogeneity effects in FL. We present theoretical analysis and conduct extensive empirical studies on the efficacy of orderings spanning three kinds of learning: curriculum, anti-curriculum, and random curriculum. We find that curriculum learning largely alleviates non-IIDness. Interestingly, the more disparate the data distributions across clients the more they benefit from ordered learning. We provide analysis explaining this phenomenon, specifically indicating how curriculum training appears to make the objective landscape progressively less convex, suggesting fast converging iterations at the beginning of the training procedure. We derive quantitative results of convergence for both convex and nonconvex objectives by modeling the curriculum training on federated devices as local SGD with locally biased stochastic gradients. Also, inspired by ordered learning, we propose a novel client selection technique that benefits from the real-world disparity in the clients. Our proposed approach to client selection has a synergic effect when applied together with ordered learning in FL.
Lightning Fast Video Anomaly Detection via Adversarial Knowledge Distillation
Nov 28, 2022



We propose a very fast frame-level model for anomaly detection in video, which learns to detect anomalies by distilling knowledge from multiple highly accurate object-level teacher models. To improve the fidelity of our student, we distill the low-resolution anomaly maps of the teachers by jointly applying standard and adversarial distillation, introducing an adversarial discriminator for each teacher to distinguish between target and generated anomaly maps. We conduct experiments on three benchmarks (Avenue, ShanghaiTech, UCSD Ped2), showing that our method is over 7 times faster than the fastest competing method, and between 28 and 62 times faster than object-centric models, while obtaining comparable results to recent methods. Our evaluation also indicates that our model achieves the best trade-off between speed and accuracy, due to its previously unheard-of speed of 1480 FPS. In addition, we carry out a comprehensive ablation study to justify our architectural design choices.
Query Efficient Cross-Dataset Transferable Black-Box Attack on Action Recognition
Nov 23, 2022Black-box adversarial attacks present a realistic threat to action recognition systems. Existing black-box attacks follow either a query-based approach where an attack is optimized by querying the target model, or a transfer-based approach where attacks are generated using a substitute model. While these methods can achieve decent fooling rates, the former tends to be highly query-inefficient while the latter assumes extensive knowledge of the black-box model's training data. In this paper, we propose a new attack on action recognition that addresses these shortcomings by generating perturbations to disrupt the features learned by a pre-trained substitute model to reduce the number of queries. By using a nearly disjoint dataset to train the substitute model, our method removes the requirement that the substitute model be trained using the same dataset as the target model, and leverages queries to the target model to retain the fooling rate benefits provided by query-based methods. This ultimately results in attacks which are more transferable than conventional black-box attacks. Through extensive experiments, we demonstrate highly query-efficient black-box attacks with the proposed framework. Our method achieves 8% and 12% higher deception rates compared to state-of-the-art query-based and transfer-based attacks, respectively.
Person Image Synthesis via Denoising Diffusion Model
Nov 22, 2022The pose-guided person image generation task requires synthesizing photorealistic images of humans in arbitrary poses. The existing approaches use generative adversarial networks that do not necessarily maintain realistic textures or need dense correspondences that struggle to handle complex deformations and severe occlusions. In this work, we show how denoising diffusion models can be applied for high-fidelity person image synthesis with strong sample diversity and enhanced mode coverage of the learnt data distribution. Our proposed Person Image Diffusion Model (PIDM) disintegrates the complex transfer problem into a series of simpler forward-backward denoising steps. This helps in learning plausible source-to-target transformation trajectories that result in faithful textures and undistorted appearance details. We introduce a 'texture diffusion module' based on cross-attention to accurately model the correspondences between appearance and pose information available in source and target images. Further, we propose 'disentangled classifier-free guidance' to ensure close resemblance between the conditional inputs and the synthesized output in terms of both pose and appearance information. Our extensive results on two large-scale benchmarks and a user study demonstrate the photorealism of our proposed approach under challenging scenarios. We also show how our generated images can help in downstream tasks. Our code and models will be publicly released.
3DMODT: Attention-Guided Affinities for Joint Detection & Tracking in 3D Point Clouds
Nov 01, 2022



We propose a method for joint detection and tracking of multiple objects in 3D point clouds, a task conventionally treated as a two-step process comprising object detection followed by data association. Our method embeds both steps into a single end-to-end trainable network eliminating the dependency on external object detectors. Our model exploits temporal information employing multiple frames to detect objects and track them in a single network, thereby making it a utilitarian formulation for real-world scenarios. Computing affinity matrix by employing features similarity across consecutive point cloud scans forms an integral part of visual tracking. We propose an attention-based refinement module to refine the affinity matrix by suppressing erroneous correspondences. The module is designed to capture the global context in affinity matrix by employing self-attention within each affinity matrix and cross-attention across a pair of affinity matrices. Unlike competing approaches, our network does not require complex post-processing algorithms, and processes raw LiDAR frames to directly output tracking results. We demonstrate the effectiveness of our method on the three tracking benchmarks: JRDB, Waymo, and KITTI. Experimental evaluations indicate the ability of our model to generalize well across datasets.
Adversarial Pretraining of Self-Supervised Deep Networks: Past, Present and Future
Oct 23, 2022



In this paper, we review adversarial pretraining of self-supervised deep networks including both convolutional neural networks and vision transformers. Unlike the adversarial training with access to labeled examples, adversarial pretraining is complicated as it only has access to unlabeled examples. To incorporate adversaries into pretraining models on either input or feature level, we find that existing approaches are largely categorized into two groups: memory-free instance-wise attacks imposing worst-case perturbations on individual examples, and memory-based adversaries shared across examples over iterations. In particular, we review several representative adversarial pretraining models based on Contrastive Learning (CL) and Masked Image Modeling (MIM), respectively, two popular self-supervised pretraining methods in literature. We also review miscellaneous issues about computing overheads, input-/feature-level adversaries, as well as other adversarial pretraining approaches beyond the above two groups. Finally, we discuss emerging trends and future directions about the relations between adversarial and cooperative pretraining, unifying adversarial CL and MIM pretraining, and the trade-off between accuracy and robustness in adversarial pretraining.
TransVisDrone: Spatio-Temporal Transformer for Vision-based Drone-to-Drone Detection in Aerial Videos
Oct 16, 2022
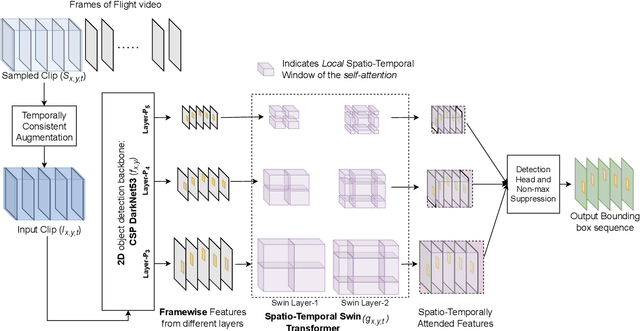
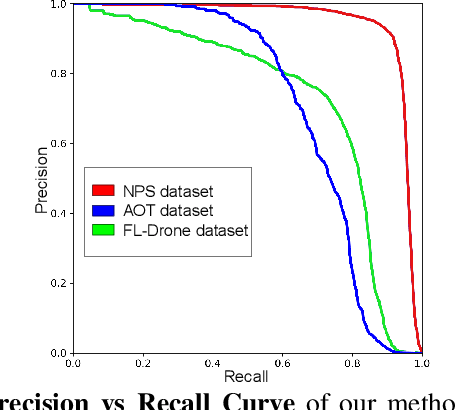
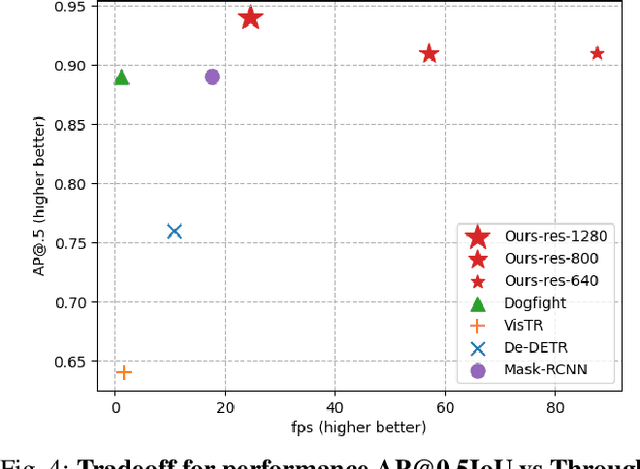
Drone-to-drone detection using visual feed has crucial applications like avoiding collision with other drones/airborne objects, tackling a drone attack or coordinating flight with other drones. However, the existing methods are computationally costly, follow a non-end-to-end optimization and have complex multi-stage pipeline, which make them less suitable to deploy on edge devices for real-time drone flight. In this work, we propose a simple-yet-effective framework TransVisDrone, which provides end-to-end solution with higher computational efficiency. We utilize CSPDarkNet-53 network to learn object-related spatial features and VideoSwin model to learn the spatio-temporal dependencies of drone motion which improves drone detection in challenging scenarios. Our method obtains state-of-the-art performance on three challenging real-world datasets (Average Precision@0.5IOU): NPS 0.95, FLDrones 0.75 and AOT 0.80. Apart from its superior performance, it achieves higher throughput than the prior work. We also demonstrate its deployment capability on edge-computing devices and usefulness in applications like drone-collision (encounter) detection. Code: \url{https://github.com/tusharsangam/TransVisDrone}.
Rethinking Data Heterogeneity in Federated Learning: Introducing a New Notion and Standard Benchmarks
Sep 30, 2022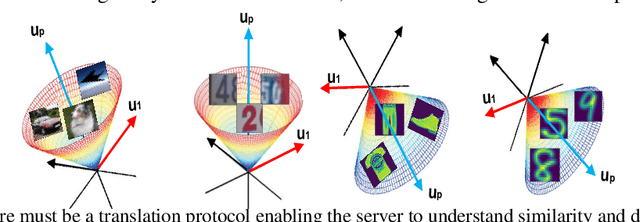

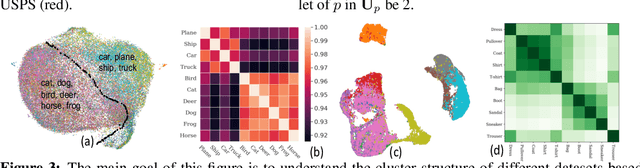
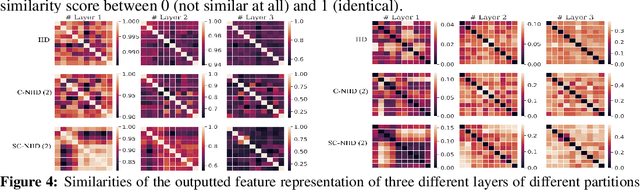
Though successful, federated learning presents new challenges for machine learning, especially when the issue of data heterogeneity, also known as Non-IID data, arises. To cope with the statistical heterogeneity, previous works incorporated a proximal term in local optimization or modified the model aggregation scheme at the server side or advocated clustered federated learning approaches where the central server groups agent population into clusters with jointly trainable data distributions to take the advantage of a certain level of personalization. While effective, they lack a deep elaboration on what kind of data heterogeneity and how the data heterogeneity impacts the accuracy performance of the participating clients. In contrast to many of the prior federated learning approaches, we demonstrate not only the issue of data heterogeneity in current setups is not necessarily a problem but also in fact it can be beneficial for the FL participants. Our observations are intuitive: (1) Dissimilar labels of clients (label skew) are not necessarily considered data heterogeneity, and (2) the principal angle between the agents' data subspaces spanned by their corresponding principal vectors of data is a better estimate of the data heterogeneity. Our code is available at https://github.com/MMorafah/FL-SC-NIID.
Self-Supervised Masked Convolutional Transformer Block for Anomaly Detection
Sep 25, 2022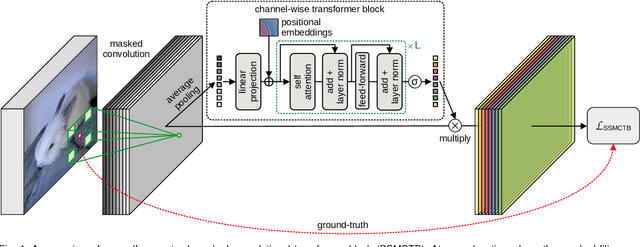

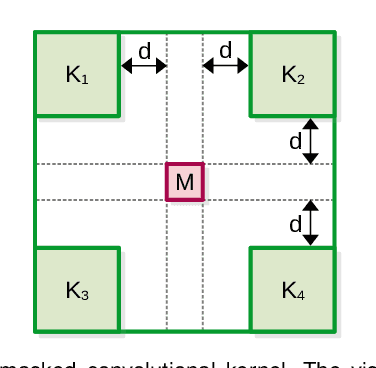
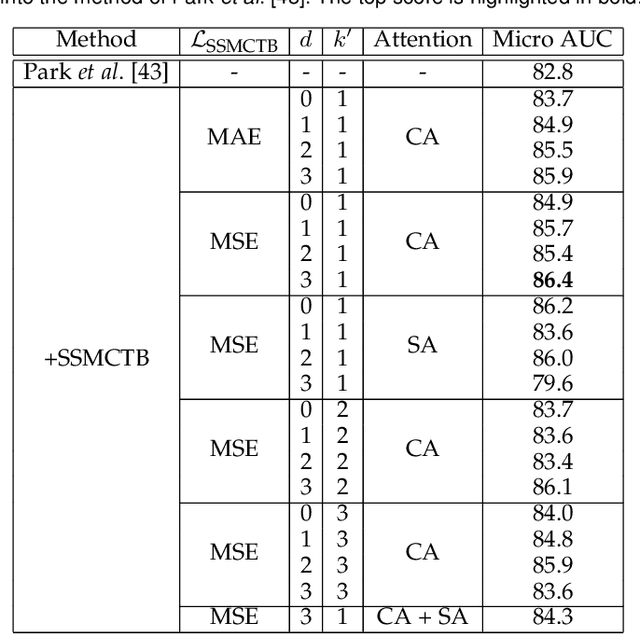
Anomaly detection has recently gained increasing attention in the field of computer vision, likely due to its broad set of applications ranging from product fault detection on industrial production lines and impending event detection in video surveillance to finding lesions in medical scans. Regardless of the domain, anomaly detection is typically framed as a one-class classification task, where the learning is conducted on normal examples only. An entire family of successful anomaly detection methods is based on learning to reconstruct masked normal inputs (e.g. patches, future frames, etc.) and exerting the magnitude of the reconstruction error as an indicator for the abnormality level. Unlike other reconstruction-based methods, we present a novel self-supervised masked convolutional transformer block (SSMCTB) that comprises the reconstruction-based functionality at a core architectural level. The proposed self-supervised block is extremely flexible, enabling information masking at any layer of a neural network and being compatible with a wide range of neural architectures. In this work, we extend our previous self-supervised predictive convolutional attentive block (SSPCAB) with a 3D masked convolutional layer, as well as a transformer for channel-wise attention. Furthermore, we show that our block is applicable to a wider variety of tasks, adding anomaly detection in medical images and thermal videos to the previously considered tasks based on RGB images and surveillance videos. We exhibit the generality and flexibility of SSMCTB by integrating it into multiple state-of-the-art neural models for anomaly detection, bringing forth empirical results that confirm considerable performance improvements on five benchmarks: MVTec AD, BRATS, Avenue, ShanghaiTech, and Thermal Rare Event. We release our code and data as open source at https://github.com/ristea/ssmctb.
Efficient Distribution Similarity Identification in Clustered Federated Learning via Principal Angles Between Client Data Subspaces
Sep 21, 2022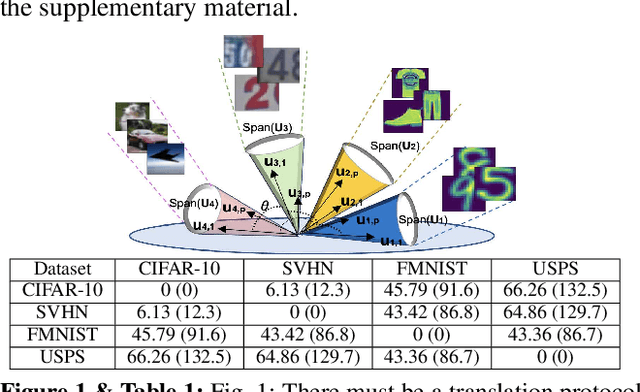

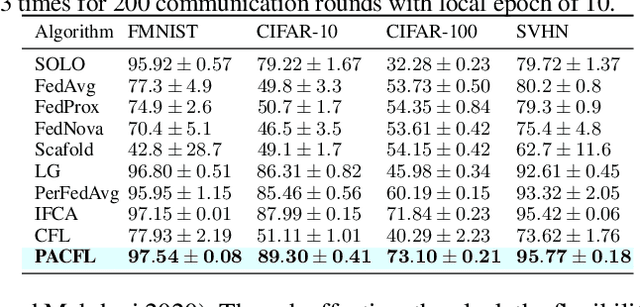

Clustered federated learning (FL) has been shown to produce promising results by grouping clients into clusters. This is especially effective in scenarios where separate groups of clients have significant differences in the distributions of their local data. Existing clustered FL algorithms are essentially trying to group together clients with similar distributions so that clients in the same cluster can leverage each other's data to better perform federated learning. However, prior clustered FL algorithms attempt to learn these distribution similarities indirectly during training, which can be quite time consuming as many rounds of federated learning may be required until the formation of clusters is stabilized. In this paper, we propose a new approach to federated learning that directly aims to efficiently identify distribution similarities among clients by analyzing the principal angles between the client data subspaces. Each client applies a truncated singular value decomposition (SVD) step on its local data in a single-shot manner to derive a small set of principal vectors, which provides a signature that succinctly captures the main characteristics of the underlying distribution. This small set of principal vectors is provided to the server so that the server can directly identify distribution similarities among the clients to form clusters. This is achieved by comparing the similarities of the principal angles between the client data subspaces spanned by those principal vectors. The approach provides a simple, yet effective clustered FL framework that addresses a broad range of data heterogeneity issues beyond simpler forms of Non-IIDness like label skews. Our clustered FL approach also enables convergence guarantees for non-convex objectives. Our code is available at https://github.com/MMorafah/PACFL.