 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSolving Quantum-Inspired Perfect Matching Problems via Tutte's Theorem-Based Hybrid Boolean Constraints
Jan 24, 2023Determining the satisfiability of Boolean constraint-satisfaction problems with different types of constraints, that is hybrid constraints, is a well-studied problem with important applications. We study here a new application of hybrid Boolean constraints, which arises in quantum computing. The problem relates to constrained perfect matching in edge-colored graphs. While general-purpose hybrid constraint solvers can be powerful, we show that direct encodings of the constrained-matching problem as hybrid constraints scale poorly and special techniques are still needed. We propose a novel encoding based on Tutte's Theorem in graph theory as well as optimization techniques. Empirical results demonstrate that our encoding, in suitable languages with advanced SAT solvers, scales significantly better than a number of competing approaches on constrained-matching benchmarks. Our study identifies the necessity of designing problem-specific encodings when applying powerful general-purpose constraint solvers.
Synthesis from Satisficing and Temporal Goals
May 20, 2022
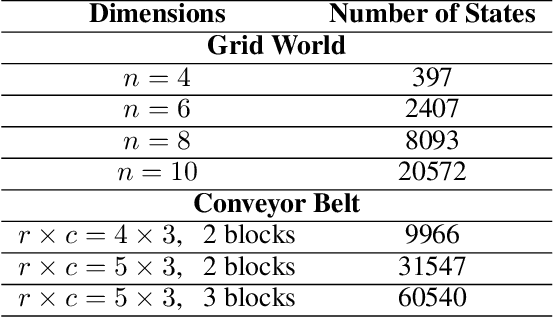
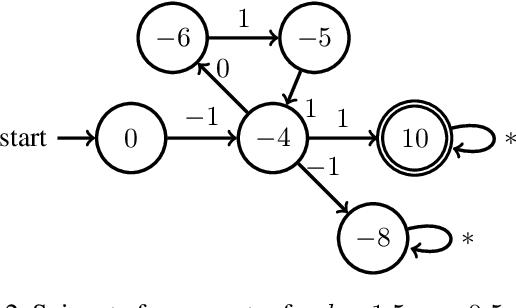
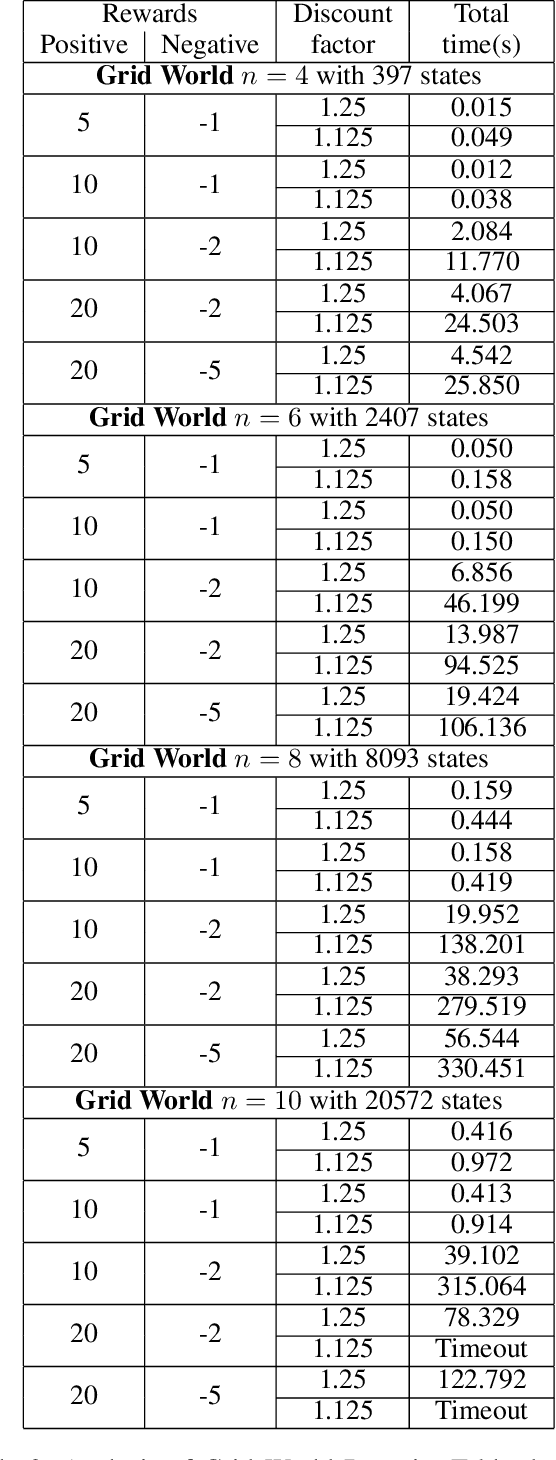
Reactive synthesis from high-level specifications that combine hard constraints expressed in Linear Temporal Logic LTL with soft constraints expressed by discounted-sum (DS) rewards has applications in planning and reinforcement learning. An existing approach combines techniques from LTL synthesis with optimization for the DS rewards but has failed to yield a sound algorithm. An alternative approach combining LTL synthesis with satisficing DS rewards (rewards that achieve a threshold) is sound and complete for integer discount factors, but, in practice, a fractional discount factor is desired. This work extends the existing satisficing approach, presenting the first sound algorithm for synthesis from LTL and DS rewards with fractional discount factors. The utility of our algorithm is demonstrated on robotic planning domains.
DPER: Dynamic Programming for Exist-Random Stochastic SAT
May 19, 2022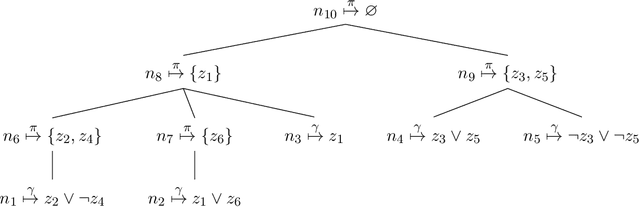
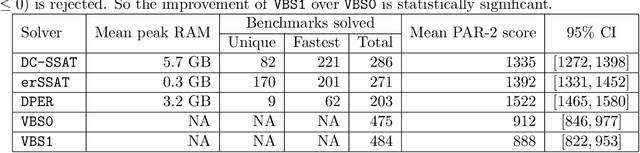
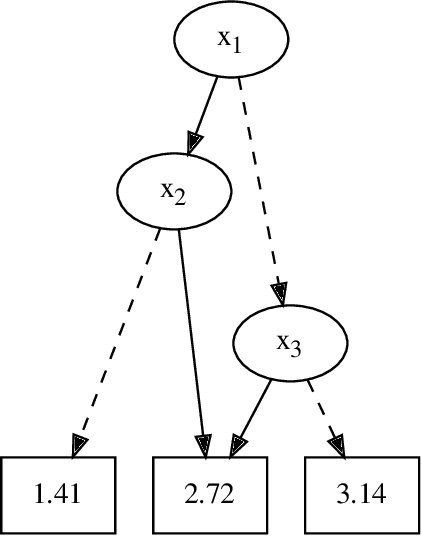
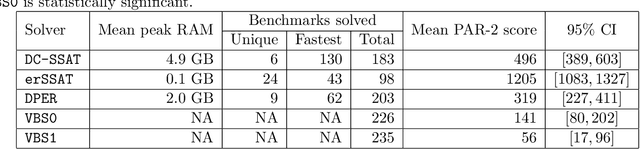
In Bayesian inference, the maximum a posteriori (MAP) problem combines the most probable explanation (MPE) and marginalization (MAR) problems. The counterpart in propositional logic is the exist-random stochastic satisfiability (ER-SSAT) problem, which combines the satisfiability (SAT) and weighted model counting (WMC) problems. Both MAP and ER-SSAT have the form $\operatorname{argmax}_X \sum_Y f(X, Y)$, where $f$ is a real-valued function over disjoint sets $X$ and $Y$ of variables. These two optimization problems request a value assignment for the $X$ variables that maximizes the weighted sum of $f(X, Y)$ over all value assignments for the $Y$ variables. ER-SSAT has been shown to be a promising approach to formally verify fairness in supervised learning. Recently, dynamic programming on graded project-join trees has been proposed to solve weighted projected model counting (WPMC), a related problem that has the form $\sum_X \max_Y f(X, Y)$. We extend this WPMC framework to exactly solve ER-SSAT and implement a dynamic-programming solver named DPER. Our empirical evaluation indicates that DPER contributes to the portfolio of state-of-the-art ER-SSAT solvers (DC-SSAT and erSSAT) through competitive performance on low-width problem instances.
DPO: Dynamic-Programming Optimization on Hybrid Constraints
May 17, 2022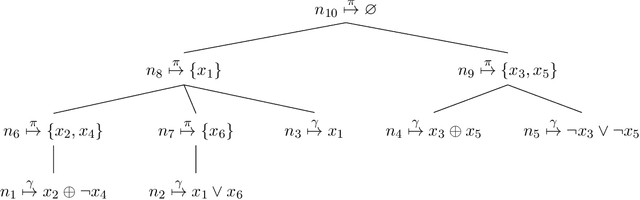
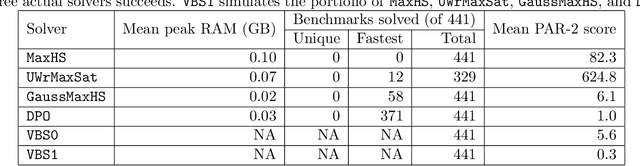
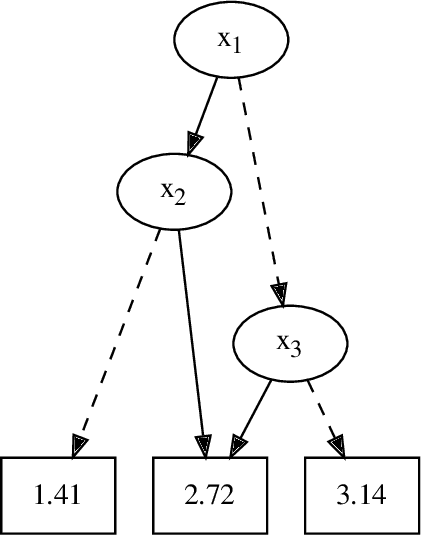
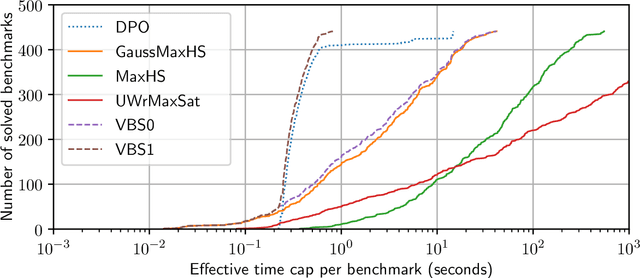
In Bayesian inference, the most probable explanation (MPE) problem requests a variable instantiation with the highest probability given some evidence. Since a Bayesian network can be encoded as a literal-weighted CNF formula $\varphi$, we study Boolean MPE, a more general problem that requests a model $\tau$ of $\varphi$ with the highest weight, where the weight of $\tau$ is the product of weights of literals satisfied by $\tau$. It is known that Boolean MPE can be solved via reduction to (weighted partial) MaxSAT. Recent work proposed DPMC, a dynamic-programming model counter that leverages graph-decomposition techniques to construct project-join trees. A project-join tree is an execution plan that specifies how to conjoin clauses and project out variables. We build on DPMC and introduce DPO, a dynamic-programming optimizer that exactly solves Boolean MPE. By using algebraic decision diagrams (ADDs) to represent pseudo-Boolean (PB) functions, DPO is able to handle disjunctive clauses as well as XOR clauses. (Cardinality constraints and PB constraints may also be compactly represented by ADDs, so one can further extend DPO's support for hybrid inputs.) To test the competitiveness of DPO, we generate random XOR-CNF formulas. On these hybrid benchmarks, DPO significantly outperforms MaxHS, UWrMaxSat, and GaussMaxHS, which are state-of-the-art exact solvers for MaxSAT.
DPMS: An ADD-Based Symbolic Approach for Generalized MaxSAT Solving
May 08, 2022
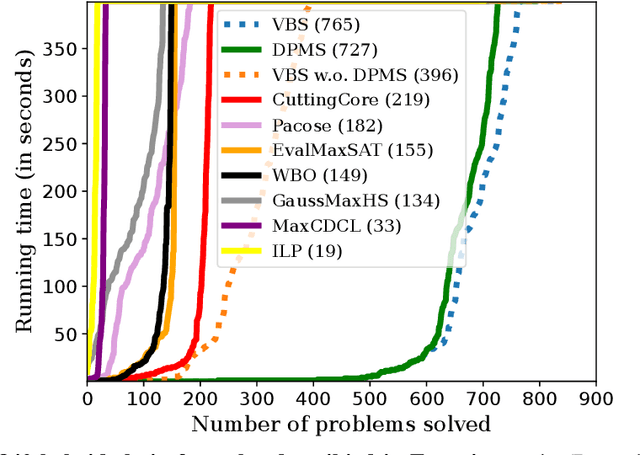
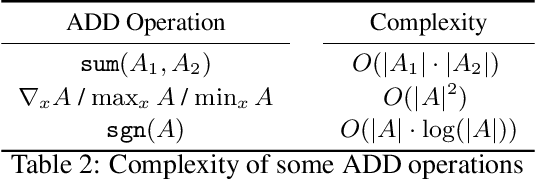

Boolean MaxSAT, as well as generalized formulations such as Min-MaxSAT and Max-hybrid-SAT, are fundamental optimization problems in Boolean reasoning. Existing methods for MaxSAT have been successful in solving benchmarks in CNF format. They lack, however, the ability to handle hybrid and generalized MaxSAT problems natively. To address this issue, we propose a novel dynamic-programming approach for solving generalized MaxSAT problems -- called Dynamic-Programming-MaxSAT or DPMS for short -- based on Algebraic Decision Diagrams (ADDs). With the power of ADDs and the (graded) project-join-tree builder, our versatile framework can handle many generalizations of MaxSAT, such as MaxSAT with non-CNF constraints, Min-MaxSAT and MinSAT. Moreover, DPMS scales provably well on instances with low width. Empirical results indicate that DPMS is able to solve certain problems quickly, where other algorithms based on various techniques all fail. Hence, DPMS is a promising framework and opens a new line of research that desires more investigation in the future.
On Satisficing in Quantitative Games
Jan 06, 2021
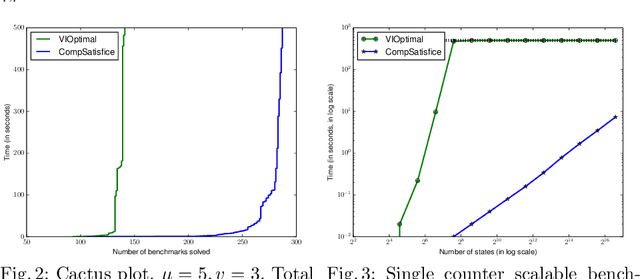
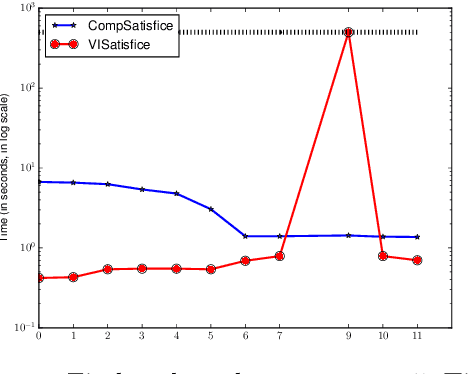
Several problems in planning and reactive synthesis can be reduced to the analysis of two-player quantitative graph games. {\em Optimization} is one form of analysis. We argue that in many cases it may be better to replace the optimization problem with the {\em satisficing problem}, where instead of searching for optimal solutions, the goal is to search for solutions that adhere to a given threshold bound. This work defines and investigates the satisficing problem on a two-player graph game with the discounted-sum cost model. We show that while the satisficing problem can be solved using numerical methods just like the optimization problem, this approach does not render compelling benefits over optimization. When the discount factor is, however, an integer, we present another approach to satisficing, which is purely based on automata methods. We show that this approach is algorithmically more performant -- both theoretically and empirically -- and demonstrates the broader applicability of satisficing overoptimization.
On Continuous Local BDD-Based Search for Hybrid SAT Solving
Dec 14, 2020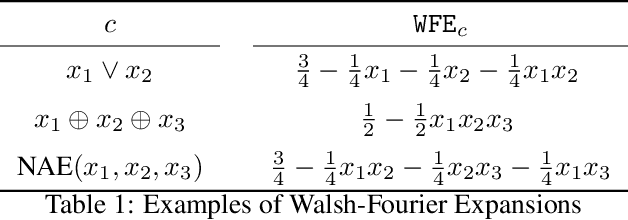
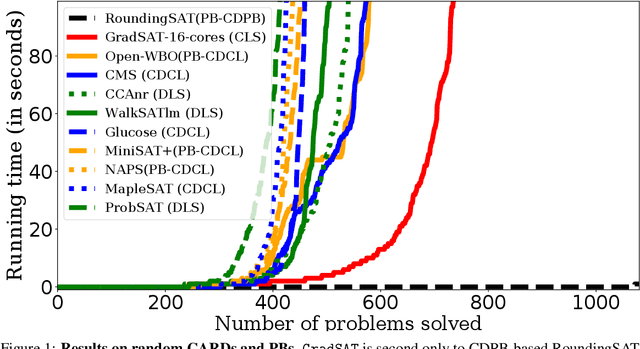

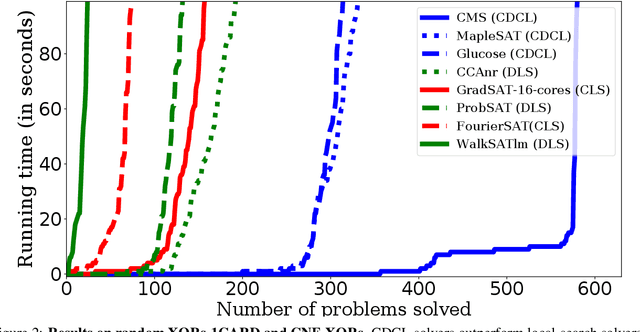
We explore the potential of continuous local search (CLS) in SAT solving by proposing a novel approach for finding a solution of a hybrid system of Boolean constraints. The algorithm is based on CLS combined with belief propagation on binary decision diagrams (BDDs). Our framework accepts all Boolean constraints that admit compact BDDs, including symmetric Boolean constraints and small-coefficient pseudo-Boolean constraints as interesting families. We propose a novel algorithm for efficiently computing the gradient needed by CLS. We study the capabilities and limitations of our versatile CLS solver, GradSAT, by applying it on many benchmark instances. The experimental results indicate that GradSAT can be a useful addition to the portfolio of existing SAT and MaxSAT solvers for solving Boolean satisfiability and optimization problems.
LTLf Synthesis on Probabilistic Systems
Sep 23, 2020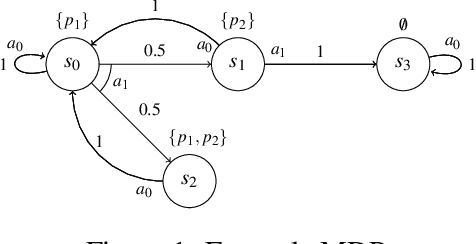

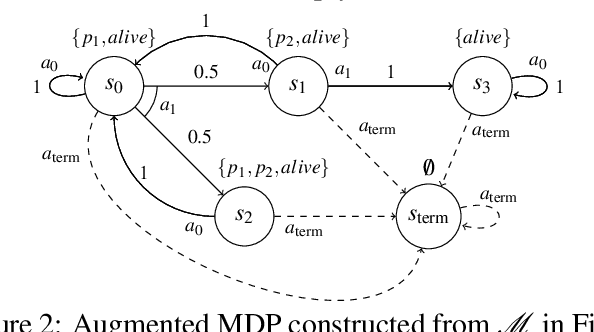
Many systems are naturally modeled as Markov Decision Processes (MDPs), combining probabilities and strategic actions. Given a model of a system as an MDP and some logical specification of system behavior, the goal of synthesis is to find a policy that maximizes the probability of achieving this behavior. A popular choice for defining behaviors is Linear Temporal Logic (LTL). Policy synthesis on MDPs for properties specified in LTL has been well studied. LTL, however, is defined over infinite traces, while many properties of interest are inherently finite. Linear Temporal Logic over finite traces (LTLf) has been used to express such properties, but no tools exist to solve policy synthesis for MDP behaviors given finite-trace properties. We present two algorithms for solving this synthesis problem: the first via reduction of LTLf to LTL and the second using native tools for LTLf. We compare the scalability of these two approaches for synthesis and show that the native approach offers better scalability compared to existing automaton generation tools for LTL.
* In Proceedings GandALF 2020, arXiv:2009.09360
DPMC: Weighted Model Counting by Dynamic Programming on Project-Join Trees
Aug 20, 2020

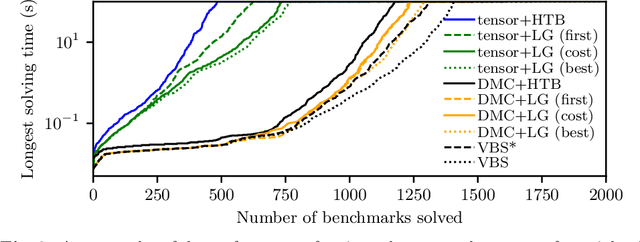
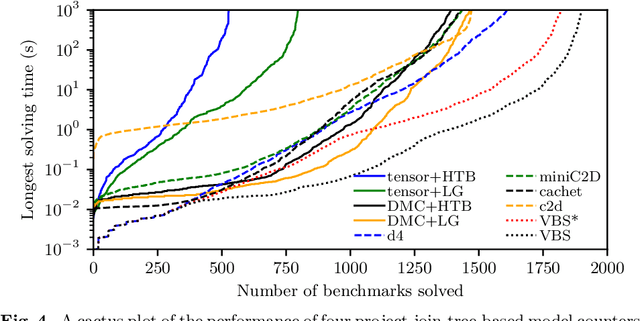
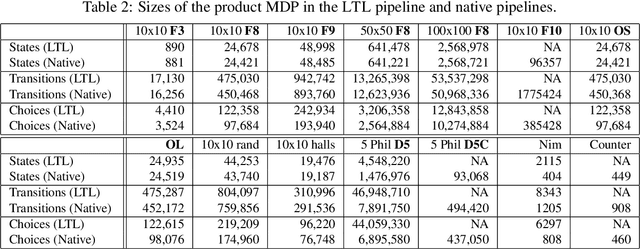
We propose a unifying dynamic-programming framework to compute exact literal-weighted model counts of formulas in conjunctive normal form. At the center of our framework are project-join trees, which specify efficient project-join orders to apply additive projections (variable eliminations) and joins (clause multiplications). In this framework, model counting is performed in two phases. First, the planning phase constructs a project-join tree from a formula. Second, the execution phase computes the model count of the formula, employing dynamic programming as guided by the project-join tree. We empirically evaluate various methods for the planning phase and compare constraint-satisfaction heuristics with tree-decomposition tools. We also investigate the performance of different data structures for the execution phase and compare algebraic decision diagrams with tensors. We show that our dynamic-programming model-counting framework DPMC is competitive with the state-of-the-art exact weighted model counters cachet, c2d, d4, and miniC2D.
On the Power of Unambiguity in Büchi Complementation
May 18, 2020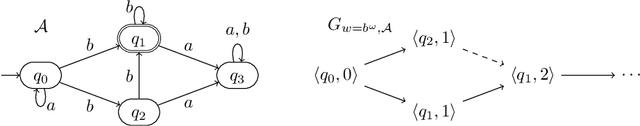
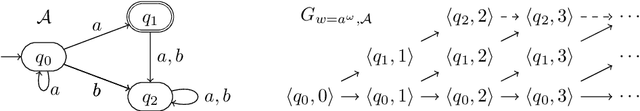
In this work, we exploit the power of unambiguity for the complementation problem of B\"uchi automata by utilizing reduced run directed acyclic graphs (DAGs) over infinite words, in which each vertex has at most one predecessor. Given a B\"uchi automaton with n states and a finite degree of ambiguity, we show that the number of states in the complementary B\"uchi automaton constructed by the classical Rank-based and Slice-based complementation constructions can be improved, respectively, to $2^{\mathcal{O}(n)}$ from $2^{\mathcal{O}( n \log n)}$ and to $\mathcal{O}(4^n)$ from $\mathcal{O}( (3n)^n)$, based on reduced run DAGs. To the best of our knowledge, the improved complexity is exponentially better than best known result of $\mathcal{O}(5^n)$ in [21] for complementing B\"uchi automata with a finite degree of ambiguity.