 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgePredMapNet: Future and Historical Reasoning for Consistent Online HD Vectorized Map Construction
Feb 18, 2026High-definition (HD) maps are crucial to autonomous driving, providing structured representations of road elements to support navigation and planning. However, existing query-based methods often employ random query initialization and depend on implicit temporal modeling, which lead to temporal inconsistencies and instabilities during the construction of a global map. To overcome these challenges, we introduce a novel end-to-end framework for consistent online HD vectorized map construction, which jointly performs map instance tracking and short-term prediction. First, we propose a Semantic-Aware Query Generator that initializes queries with spatially aligned semantic masks to capture scene-level context globally. Next, we design a History Rasterized Map Memory to store fine-grained instance-level maps for each tracked instance, enabling explicit historical priors. A History-Map Guidance Module then integrates rasterized map information into track queries, improving temporal continuity. Finally, we propose a Short-Term Future Guidance module to forecast the immediate motion of map instances based on the stored history trajectories. These predicted future locations serve as hints for tracked instances to further avoid implausible predictions and keep temporal consistency. Extensive experiments on the nuScenes and Argoverse2 datasets demonstrate that our proposed method outperforms state-of-the-art (SOTA) methods with good efficiency.
DiSa: Saliency-Aware Foreground-Background Disentangled Framework for Open-Vocabulary Semantic Segmentation
Jan 27, 2026Open-vocabulary semantic segmentation aims to assign labels to every pixel in an image based on text labels. Existing approaches typically utilize vision-language models (VLMs), such as CLIP, for dense prediction. However, VLMs, pre-trained on image-text pairs, are biased toward salient, object-centric regions and exhibit two critical limitations when adapted to segmentation: (i) Foreground Bias, which tends to ignore background regions, and (ii) Limited Spatial Localization, resulting in blurred object boundaries. To address these limitations, we introduce DiSa, a novel saliency-aware foreground-background disentangled framework. By explicitly incorporating saliency cues in our designed Saliency-aware Disentanglement Module (SDM), DiSa separately models foreground and background ensemble features in a divide-and-conquer manner. Additionally, we propose a Hierarchical Refinement Module (HRM) that leverages pixel-wise spatial contexts and enables channel-wise feature refinement through multi-level updates. Extensive experiments on six benchmarks demonstrate that DiSa consistently outperforms state-of-the-art methods.
Is Perturbation-Based Image Protection Disruptive to Image Editing?
Jun 04, 2025The remarkable image generation capabilities of state-of-the-art diffusion models, such as Stable Diffusion, can also be misused to spread misinformation and plagiarize copyrighted materials. To mitigate the potential risks associated with image editing, current image protection methods rely on adding imperceptible perturbations to images to obstruct diffusion-based editing. A fully successful protection for an image implies that the output of editing attempts is an undesirable, noisy image which is completely unrelated to the reference image. In our experiments with various perturbation-based image protection methods across multiple domains (natural scene images and artworks) and editing tasks (image-to-image generation and style editing), we discover that such protection does not achieve this goal completely. In most scenarios, diffusion-based editing of protected images generates a desirable output image which adheres precisely to the guidance prompt. Our findings suggest that adding noise to images may paradoxically increase their association with given text prompts during the generation process, leading to unintended consequences such as better resultant edits. Hence, we argue that perturbation-based methods may not provide a sufficient solution for robust image protection against diffusion-based editing.
Rethinking RGB-Event Semantic Segmentation with a Novel Bidirectional Motion-enhanced Event Representation
May 02, 2025



Event cameras capture motion dynamics, offering a unique modality with great potential in various computer vision tasks. However, RGB-Event fusion faces three intrinsic misalignments: (i) temporal, (ii) spatial, and (iii) modal misalignment. Existing voxel grid representations neglect temporal correlations between consecutive event windows, and their formulation with simple accumulation of asynchronous and sparse events is incompatible with the synchronous and dense nature of RGB modality. To tackle these challenges, we propose a novel event representation, Motion-enhanced Event Tensor (MET), which transforms sparse event voxels into a dense and temporally coherent form by leveraging dense optical flows and event temporal features. In addition, we introduce a Frequency-aware Bidirectional Flow Aggregation Module (BFAM) and a Temporal Fusion Module (TFM). BFAM leverages the frequency domain and MET to mitigate modal misalignment, while bidirectional flow aggregation and temporal fusion mechanisms resolve spatiotemporal misalignment. Experimental results on two large-scale datasets demonstrate that our framework significantly outperforms state-of-the-art RGB-Event semantic segmentation approaches. Our code is available at: https://github.com/zyaocoder/BRENet.
Event-guided Low-light Video Semantic Segmentation
Nov 01, 2024



Recent video semantic segmentation (VSS) methods have demonstrated promising results in well-lit environments. However, their performance significantly drops in low-light scenarios due to limited visibility and reduced contextual details. In addition, unfavorable low-light conditions make it harder to incorporate temporal consistency across video frames and thus, lead to video flickering effects. Compared with conventional cameras, event cameras can capture motion dynamics, filter out temporal-redundant information, and are robust to lighting conditions. To this end, we propose EVSNet, a lightweight framework that leverages event modality to guide the learning of a unified illumination-invariant representation. Specifically, we leverage a Motion Extraction Module to extract short-term and long-term temporal motions from event modality and a Motion Fusion Module to integrate image features and motion features adaptively. Furthermore, we use a Temporal Decoder to exploit video contexts and generate segmentation predictions. Such designs in EVSNet result in a lightweight architecture while achieving SOTA performance. Experimental results on 3 large-scale datasets demonstrate our proposed EVSNet outperforms SOTA methods with up to 11x higher parameter efficiency.
Latent Disentanglement for Low Light Image Enhancement
Aug 12, 2024



Many learning-based low-light image enhancement (LLIE) algorithms are based on the Retinex theory. However, the Retinex-based decomposition techniques in such models introduce corruptions which limit their enhancement performance. In this paper, we propose a Latent Disentangle-based Enhancement Network (LDE-Net) for low light vision tasks. The latent disentanglement module disentangles the input image in latent space such that no corruption remains in the disentangled Content and Illumination components. For LLIE task, we design a Content-Aware Embedding (CAE) module that utilizes Content features to direct the enhancement of the Illumination component. For downstream tasks (e.g. nighttime UAV tracking and low-light object detection), we develop an effective light-weight enhancer based on the latent disentanglement framework. Comprehensive quantitative and qualitative experiments demonstrate that our LDE-Net significantly outperforms state-of-the-art methods on various LLIE benchmarks. In addition, the great results obtained by applying our framework on the downstream tasks also demonstrate the usefulness of our latent disentanglement design.
CrackNex: a Few-shot Low-light Crack Segmentation Model Based on Retinex Theory for UAV Inspections
Mar 05, 2024



Routine visual inspections of concrete structures are imperative for upholding the safety and integrity of critical infrastructure. Such visual inspections sometimes happen under low-light conditions, e.g., checking for bridge health. Crack segmentation under such conditions is challenging due to the poor contrast between cracks and their surroundings. However, most deep learning methods are designed for well-illuminated crack images and hence their performance drops dramatically in low-light scenes. In addition, conventional approaches require many annotated low-light crack images which is time-consuming. In this paper, we address these challenges by proposing CrackNex, a framework that utilizes reflectance information based on Retinex Theory to help the model learn a unified illumination-invariant representation. Furthermore, we utilize few-shot segmentation to solve the inefficient training data problem. In CrackNex, both a support prototype and a reflectance prototype are extracted from the support set. Then, a prototype fusion module is designed to integrate the features from both prototypes. CrackNex outperforms the SOTA methods on multiple datasets. Additionally, we present the first benchmark dataset, LCSD, for low-light crack segmentation. LCSD consists of 102 well-illuminated crack images and 41 low-light crack images. The dataset and code are available at https://github.com/zy1296/CrackNex.
GRIP: Graph-based Interaction-aware Trajectory Prediction
Jul 17, 2019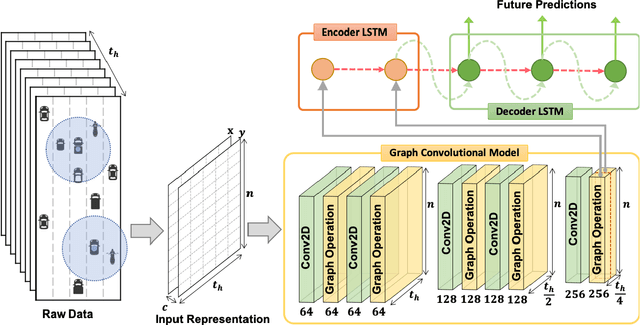
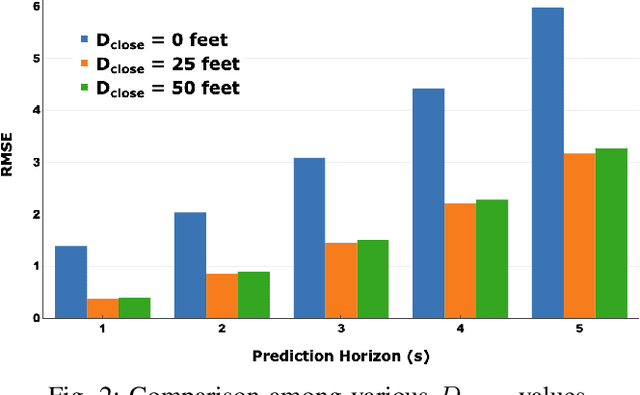
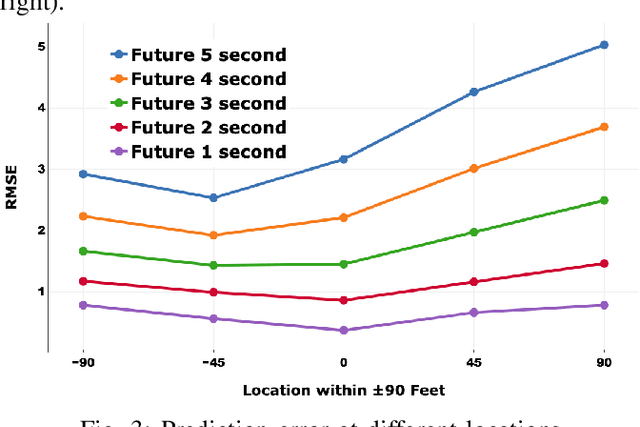
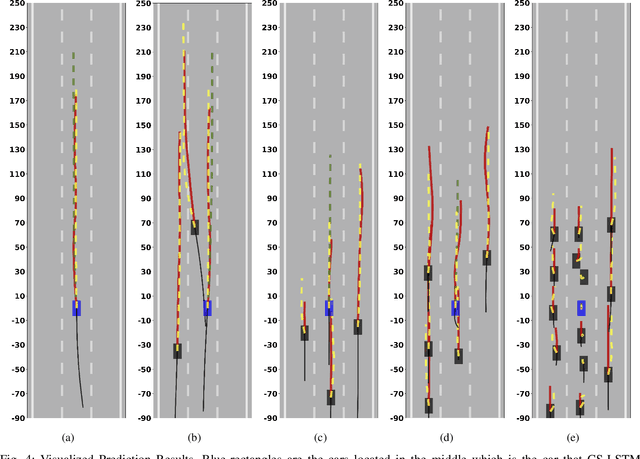
Nowadays, autonomous driving cars have become commercially available. However, the safety of a self-driving car is still a challenging problem that has not been well studied. Motion prediction is one of the core functions of an autonomous driving car. In this paper, we propose a novel scheme called GRIP which is designed to predict trajectories for traffic agents around an autonomous car efficiently. GRIP uses a graph to represent the interactions of close objects, applies several graph convolutional blocks to extract features, and subsequently uses an encoder-decoder long short-term memory (LSTM) model to make predictions. The experimental results on two well-known public datasets show that our proposed model improves the prediction accuracy of the state-of-the-art solution by 30%. The prediction error of GRIP is one meter shorter than existing schemes. Such an improvement can help autonomous driving cars avoid many traffic accidents. In addition, the proposed GRIP runs 5x faster than state-of-the-art schemes.
DAC: Data-free Automatic Acceleration of Convolutional Networks
Dec 27, 2018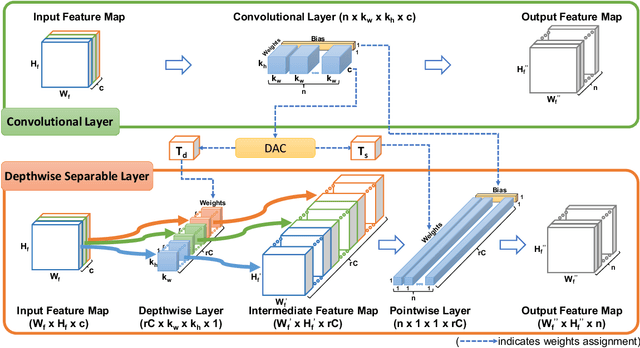
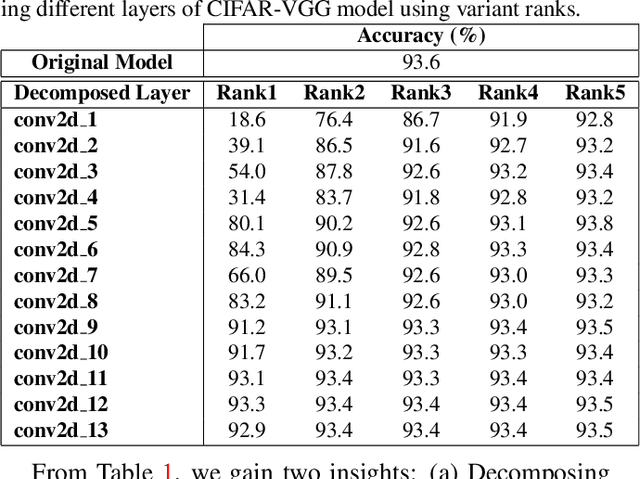
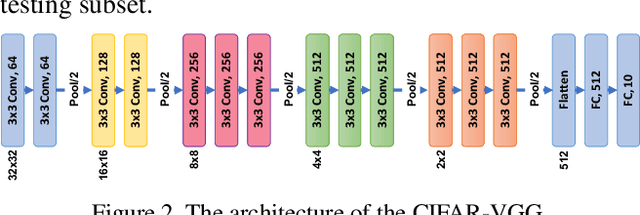
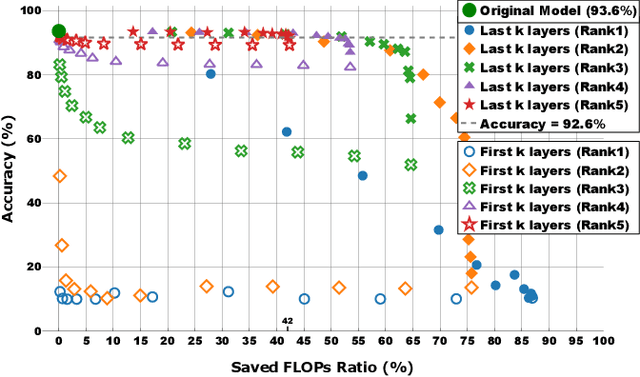
Deploying a deep learning model on mobile/IoT devices is a challenging task. The difficulty lies in the trade-off between computation speed and accuracy. A complex deep learning model with high accuracy runs slowly on resource-limited devices, while a light-weight model that runs much faster loses accuracy. In this paper, we propose a novel decomposition method, namely DAC, that is capable of factorizing an ordinary convolutional layer into two layers with much fewer parameters. DAC computes the corresponding weights for the newly generated layers directly from the weights of the original convolutional layer. Thus, no training (or fine-tuning) or any data is needed. The experimental results show that DAC reduces a large number of floating-point operations (FLOPs) while maintaining high accuracy of a pre-trained model. If 2% accuracy drop is acceptable, DAC saves 53% FLOPs of VGG16 image classification model on ImageNet dataset, 29% FLOPS of SSD300 object detection model on PASCAL VOC2007 dataset, and 46% FLOPS of a multi-person pose estimation model on Microsoft COCO dataset. Compared to other existing decomposition methods, DAC achieves better performance.
Recurrent Neural Networks based Obesity Status Prediction Using Activity Data
Sep 20, 2018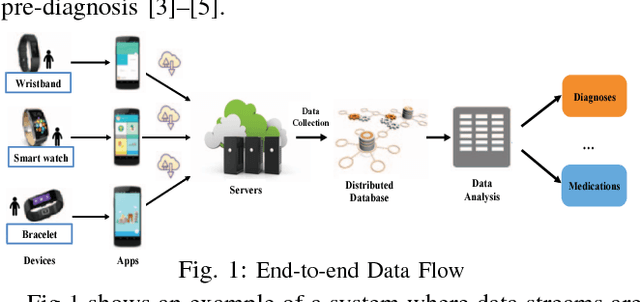

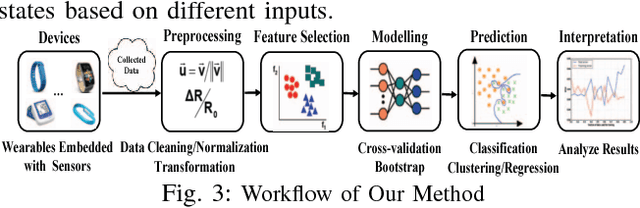
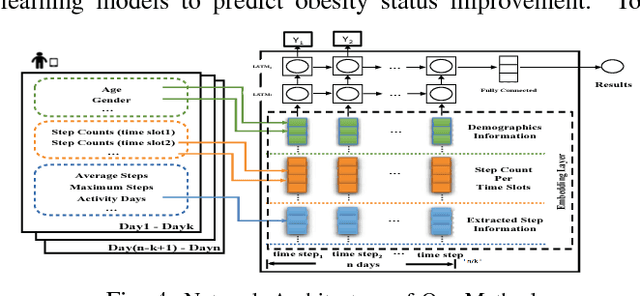
Obesity is a serious public health concern world-wide, which increases the risk of many diseases, including hypertension, stroke, and type 2 diabetes. To tackle this problem, researchers across the health ecosystem are collecting diverse types of data, which includes biomedical, behavioral and activity, and utilizing machine learning techniques to mine hidden patterns for obesity status improvement prediction. While existing machine learning methods such as Recurrent Neural Networks (RNNs) can provide exceptional results, it is challenging to discover hidden patterns of the sequential data due to the irregular observation time instances. Meanwhile, the lack of understanding of why those learning models are effective also limits further improvements on their architectures. Thus, in this work, we develop a RNN based time-aware architecture to tackle the challenging problem of handling irregular observation times and relevant feature extractions from longitudinal patient records for obesity status improvement prediction. To improve the prediction performance, we train our model using two data sources: (i) electronic medical records containing information regarding lab tests, diagnoses, and demographics; (ii) continuous activity data collected from popular wearables. Evaluations of real-world data demonstrate that our proposed method can capture the underlying structures in users' time sequences with irregularities, and achieve an accuracy of 77-86% in predicting the obesity status improvement.