 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeDocDjinn: Controllable Synthetic Document Generation with VLMs and Handwriting Diffusion
Feb 25, 2026Effective document intelligence models rely on large amounts of annotated training data. However, procuring sufficient and high-quality data poses significant challenges due to the labor-intensive and costly nature of data acquisition. Additionally, leveraging language models to annotate real documents raises concerns about data privacy. Synthetic document generation has emerged as a promising, privacy-preserving alternative. We propose DocDjinn, a novel framework for controllable synthetic document generation using Vision-Language Models (VLMs) that produces annotated documents from unlabeled seed samples. Our approach generates visually plausible and semantically consistent synthetic documents that follow the distribution of an existing source dataset through clustering-based seed selection with parametrized sampling. By enriching documents with realistic diffusion-based handwriting and contextual visual elements via semantic-visual decoupling, we generate diverse, high-quality annotated synthetic documents. We evaluate across eleven benchmarks spanning key information extraction, question answering, document classification, and document layout analysis. To our knowledge, this is the first work demonstrating that VLMs can generate faithful annotated document datasets at scale from unlabeled seeds that can effectively enrich or approximate real, manually annotated data for diverse document understanding tasks. We show that with only 100 real training samples, our framework achieves on average $87\%$ of the performance of the full real-world dataset. We publicly release our code and 140k+ synthetic document samples.
Object Detection for Vehicle Dashcams using Transformers
Aug 28, 2024



The use of intelligent automation is growing significantly in the automotive industry, as it assists drivers and fleet management companies, thus increasing their productivity. Dash cams are now been used for this purpose which enables the instant identification and understanding of multiple objects and occurrences in the surroundings. In this paper, we propose a novel approach for object detection in dashcams using transformers. Our system is based on the state-of-the-art DEtection TRansformer (DETR), which has demonstrated strong performance in a variety of conditions, including different weather and illumination scenarios. The use of transformers allows for the consideration of contextual information in decisionmaking, improving the accuracy of object detection. To validate our approach, we have trained our DETR model on a dataset that represents real-world conditions. Our results show that the use of intelligent automation through transformers can significantly enhance the capabilities of dashcam systems. The model achieves an mAP of 0.95 on detection.
ChartEye: A Deep Learning Framework for Chart Information Extraction
Aug 28, 2024



The widespread use of charts and infographics as a means of data visualization in various domains has inspired recent research in automated chart understanding. However, information extraction from chart images is a complex multitasked process due to style variations and, as a consequence, it is challenging to design an end-to-end system. In this study, we propose a deep learning-based framework that provides a solution for key steps in the chart information extraction pipeline. The proposed framework utilizes hierarchal vision transformers for the tasks of chart-type and text-role classification, while YOLOv7 for text detection. The detected text is then enhanced using Super Resolution Generative Adversarial Networks to improve the recognition output of the OCR. Experimental results on a benchmark dataset show that our proposed framework achieves excellent performance at every stage with F1-scores of 0.97 for chart-type classification, 0.91 for text-role classification, and a mean Average Precision of 0.95 for text detection.
Sequence-based Dynamic Handwriting Analysis for Parkinson's Disease Detection with One-dimensional Convolutions and BiGRUs
Jan 23, 2021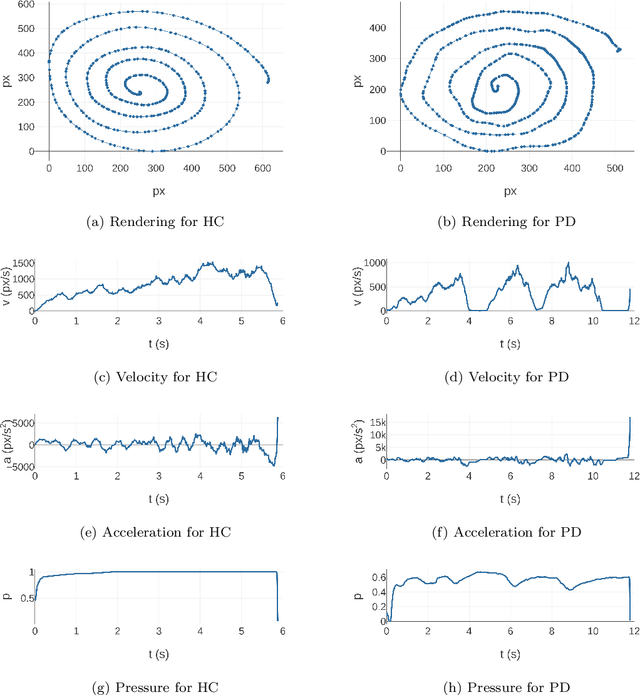

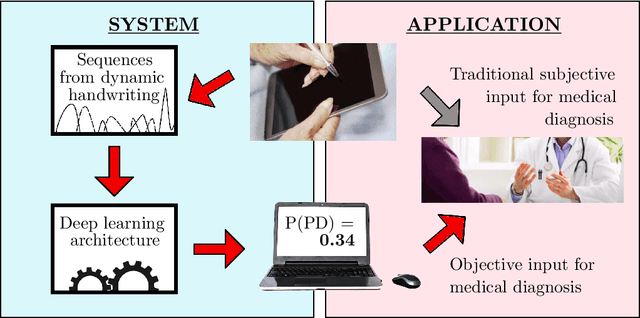
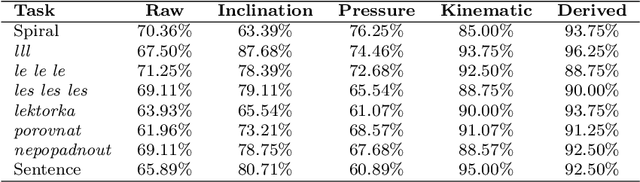
Parkinson's disease (PD) is commonly characterized by several motor symptoms, such as bradykinesia, akinesia, rigidity, and tremor. The analysis of patients' fine motor control, particularly handwriting, is a powerful tool to support PD assessment. Over the years, various dynamic attributes of handwriting, such as pen pressure, stroke speed, in-air time, etc., which can be captured with the help of online handwriting acquisition tools, have been evaluated for the identification of PD. Motion events, and their associated spatio-temporal properties captured in online handwriting, enable effective classification of PD patients through the identification of unique sequential patterns. This paper proposes a novel classification model based on one-dimensional convolutions and Bidirectional Gated Recurrent Units (BiGRUs) to assess the potential of sequential information of handwriting in identifying Parkinsonian symptoms. One-dimensional convolutions are applied to raw sequences as well as derived features; the resulting sequences are then fed to BiGRU layers to achieve the final classification. The proposed method outperformed state-of-the-art approaches on the PaHaW dataset and achieved competitive results on the NewHandPD dataset.