 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeFrankentext: Stitching random text fragments into long-form narratives
May 23, 2025

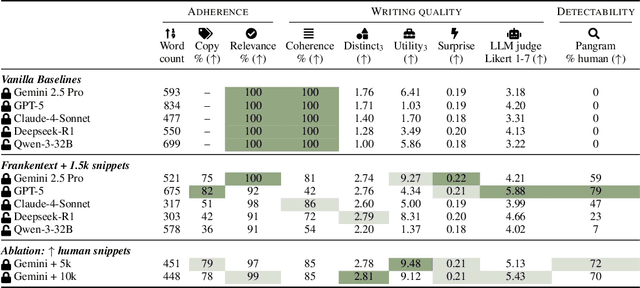
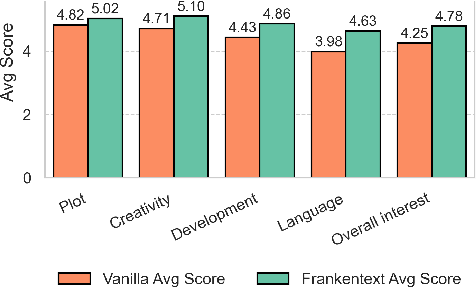
We introduce Frankentexts, a new type of long-form narratives produced by LLMs under the extreme constraint that most tokens (e.g., 90%) must be copied verbatim from human writings. This task presents a challenging test of controllable generation, requiring models to satisfy a writing prompt, integrate disparate text fragments, and still produce a coherent narrative. To generate Frankentexts, we instruct the model to produce a draft by selecting and combining human-written passages, then iteratively revise the draft while maintaining a user-specified copy ratio. We evaluate the resulting Frankentexts along three axes: writing quality, instruction adherence, and detectability. Gemini-2.5-Pro performs surprisingly well on this task: 81% of its Frankentexts are coherent and 100% relevant to the prompt. Notably, up to 59% of these outputs are misclassified as human-written by detectors like Pangram, revealing limitations in AI text detectors. Human annotators can sometimes identify Frankentexts through their abrupt tone shifts and inconsistent grammar between segments, especially in longer generations. Beyond presenting a challenging generation task, Frankentexts invite discussion on building effective detectors for this new grey zone of authorship, provide training data for mixed authorship detection, and serve as a sandbox for studying human-AI co-writing processes.
Can Large Language Models Really Recognize Your Name?
May 20, 2025



Large language models (LLMs) are increasingly being used to protect sensitive user data. However, current LLM-based privacy solutions assume that these models can reliably detect personally identifiable information (PII), particularly named entities. In this paper, we challenge that assumption by revealing systematic failures in LLM-based privacy tasks. Specifically, we show that modern LLMs regularly overlook human names even in short text snippets due to ambiguous contexts, which cause the names to be misinterpreted or mishandled. We propose AMBENCH, a benchmark dataset of seemingly ambiguous human names, leveraging the name regularity bias phenomenon, embedded within concise text snippets along with benign prompt injections. Our experiments on modern LLMs tasked to detect PII as well as specialized tools show that recall of ambiguous names drops by 20--40% compared to more recognizable names. Furthermore, ambiguous human names are four times more likely to be ignored in supposedly privacy-preserving summaries generated by LLMs when benign prompt injections are present. These findings highlight the underexplored risks of relying solely on LLMs to safeguard user privacy and underscore the need for a more systematic investigation into their privacy failure modes.
RAIFLE: Reconstruction Attacks on Interaction-based Federated Learning with Active Data Manipulation
Oct 29, 2023Federated learning (FL) has recently emerged as a privacy-preserving approach for machine learning in domains that rely on user interactions, particularly recommender systems (RS) and online learning to rank (OLTR). While there has been substantial research on the privacy of traditional FL, little attention has been paid to studying the privacy properties of these interaction-based FL (IFL) systems. In this work, we show that IFL can introduce unique challenges concerning user privacy, particularly when the central server has knowledge and control over the items that users interact with. Specifically, we demonstrate the threat of reconstructing user interactions by presenting RAIFLE, a general optimization-based reconstruction attack framework customized for IFL. RAIFLE employs Active Data Manipulation (ADM), a novel attack technique unique to IFL, where the server actively manipulates the training features of the items to induce adversarial behaviors in the local FL updates. We show that RAIFLE is more impactful than existing FL privacy attacks in the IFL context, and describe how it can undermine privacy defenses like secure aggregation and private information retrieval. Based on our findings, we propose and discuss countermeasure guidelines to mitigate our attack in the context of federated RS/OLTR specifically and IFL more broadly.