 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeStoryScope: Investigating idiosyncrasies in AI fiction
Apr 03, 2026As AI-generated fiction becomes increasingly prevalent, questions of authorship and originality are becoming central to how written work is evaluated. While most existing work in this space focuses on identifying surface-level signatures of AI writing, we ask instead whether AI-generated stories can be distinguished from human ones without relying on stylistic signals, focusing on discourse-level narrative choices such as character agency and chronological discontinuity. We propose StoryScope, a pipeline that automatically induces a fine-grained, interpretable feature space of discourse-level narrative features across 10 dimensions. We apply StoryScope to a parallel corpus of 10,272 writing prompts, each written by a human author and five LLMs, yielding 61,608 stories, each ~5,000 words, and 304 extracted features per story. Narrative features alone achieve 93.2% macro-F1 for human vs. AI detection and 68.4% macro-F1 for six-way authorship attribution, retaining over 97% of the performance of models that include stylistic cues. A compact set of 30 core narrative features captures much of this signal: AI stories over-explain themes and favor tidy, single-track plots while human stories frame protagonist' choices as more morally ambiguous and have increased temporal complexity. Per-model fingerprint features enable six-way attribution: for example, Claude produces notably flat event escalation, GPT over-indexes on dream sequences, and Gemini defaults to external character description. We find that AI-generated stories cluster in a shared region of narrative space, while human-authored stories exhibit greater diversity. More broadly, these results suggest that differences in underlying narrative construction, not just writing style, can be used to separate human-written original works from AI-generated fiction.
Frankentext: Stitching random text fragments into long-form narratives
May 23, 2025

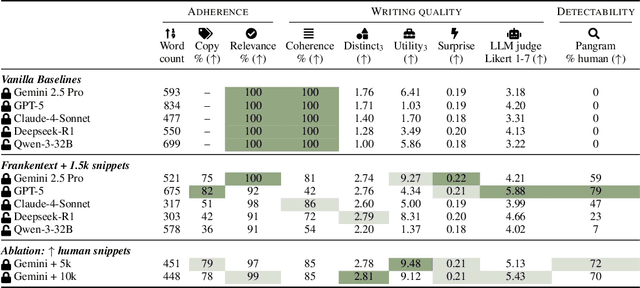
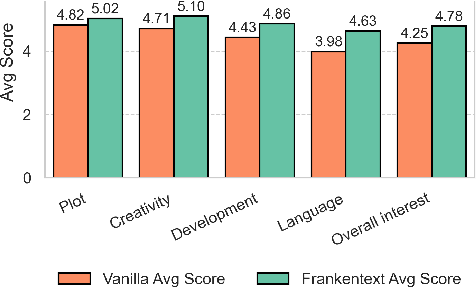
We introduce Frankentexts, a new type of long-form narratives produced by LLMs under the extreme constraint that most tokens (e.g., 90%) must be copied verbatim from human writings. This task presents a challenging test of controllable generation, requiring models to satisfy a writing prompt, integrate disparate text fragments, and still produce a coherent narrative. To generate Frankentexts, we instruct the model to produce a draft by selecting and combining human-written passages, then iteratively revise the draft while maintaining a user-specified copy ratio. We evaluate the resulting Frankentexts along three axes: writing quality, instruction adherence, and detectability. Gemini-2.5-Pro performs surprisingly well on this task: 81% of its Frankentexts are coherent and 100% relevant to the prompt. Notably, up to 59% of these outputs are misclassified as human-written by detectors like Pangram, revealing limitations in AI text detectors. Human annotators can sometimes identify Frankentexts through their abrupt tone shifts and inconsistent grammar between segments, especially in longer generations. Beyond presenting a challenging generation task, Frankentexts invite discussion on building effective detectors for this new grey zone of authorship, provide training data for mixed authorship detection, and serve as a sandbox for studying human-AI co-writing processes.
One ruler to measure them all: Benchmarking multilingual long-context language models
Mar 03, 2025



We present ONERULER, a multilingual benchmark designed to evaluate long-context language models across 26 languages. ONERULER adapts the English-only RULER benchmark (Hsieh et al., 2024) by including seven synthetic tasks that test both retrieval and aggregation, including new variations of the "needle-in-a-haystack" task that allow for the possibility of a nonexistent needle. We create ONERULER through a two-step process, first writing English instructions for each task and then collaborating with native speakers to translate them into 25 additional languages. Experiments with both open-weight and closed LLMs reveal a widening performance gap between low- and high-resource languages as context length increases from 8K to 128K tokens. Surprisingly, English is not the top-performing language on long-context tasks (ranked 6th out of 26), with Polish emerging as the top language. Our experiments also show that many LLMs (particularly OpenAI's o3-mini-high) incorrectly predict the absence of an answer, even in high-resource languages. Finally, in cross-lingual scenarios where instructions and context appear in different languages, performance can fluctuate by up to 20% depending on the instruction language. We hope the release of ONERULER will facilitate future research into improving multilingual and cross-lingual long-context training pipelines.
People who frequently use ChatGPT for writing tasks are accurate and robust detectors of AI-generated text
Jan 26, 2025

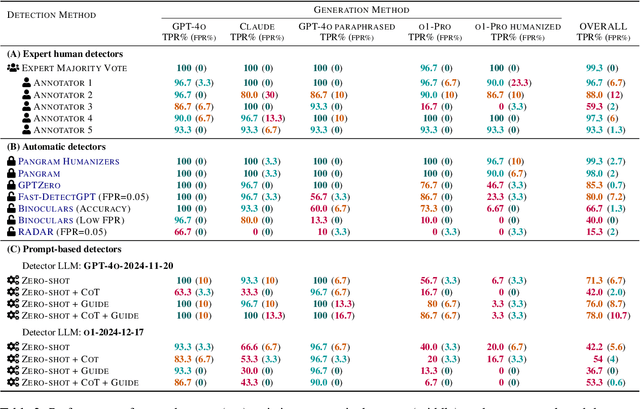
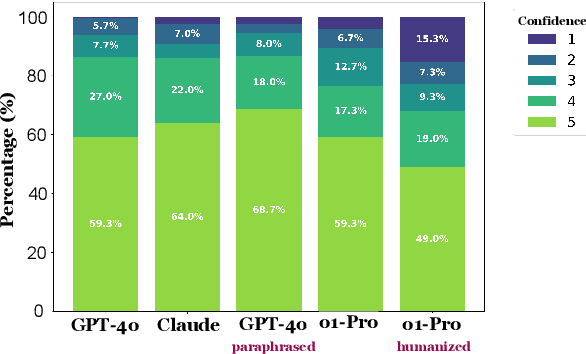
In this paper, we study how well humans can detect text generated by commercial LLMs (GPT-4o, Claude, o1). We hire annotators to read 300 non-fiction English articles, label them as either human-written or AI-generated, and provide paragraph-length explanations for their decisions. Our experiments show that annotators who frequently use LLMs for writing tasks excel at detecting AI-generated text, even without any specialized training or feedback. In fact, the majority vote among five such "expert" annotators misclassifies only 1 of 300 articles, significantly outperforming most commercial and open-source detectors we evaluated even in the presence of evasion tactics like paraphrasing and humanization. Qualitative analysis of the experts' free-form explanations shows that while they rely heavily on specific lexical clues ('AI vocabulary'), they also pick up on more complex phenomena within the text (e.g., formality, originality, clarity) that are challenging to assess for automatic detectors. We release our annotated dataset and code to spur future research into both human and automated detection of AI-generated text.