 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeQuantifying Information Leakage from Gradients
May 28, 2021

Sharing deep neural networks' gradients instead of training data could facilitate data privacy in collaborative learning. In practice however, gradients can disclose both private latent attributes and original data. Mathematical metrics are needed to quantify both original and latent information leakages from gradients computed over the training data. In this work, we first use an adaptation of the empirical $\mathcal{V}$-information to present an information-theoretic justification for the attack success rates in a layer-wise manner. We then move towards a deeper understanding of gradient leakages and propose more general and efficient metrics, using sensitivity and subspace distance to quantify the gradient changes w.r.t. original and latent information, respectively. Our empirical results, on six datasets and four models, reveal that gradients of the first layers contain the highest amount of original information, while the classifier/fully-connected layers placed after the feature extractor contain the highest latent information. Further, we show how training hyperparameters such as gradient aggregation can decrease information leakages. Our characterization provides a new understanding on gradient-based information leakages using the gradients' sensitivity w.r.t. changes in private information, and portends possible defenses such as layer-based protection or strong aggregation.
Honest-but-Curious Nets: Sensitive Attributes of Private Inputs can be Secretly Coded into the Entropy of Classifiers' Outputs
May 25, 2021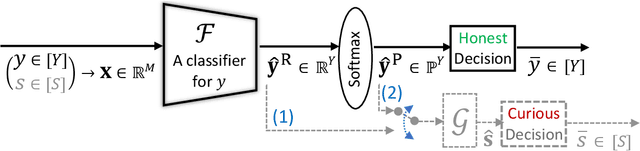
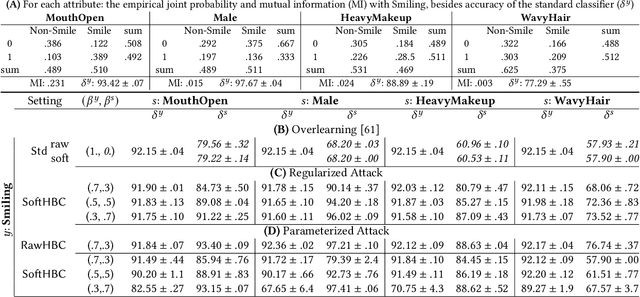
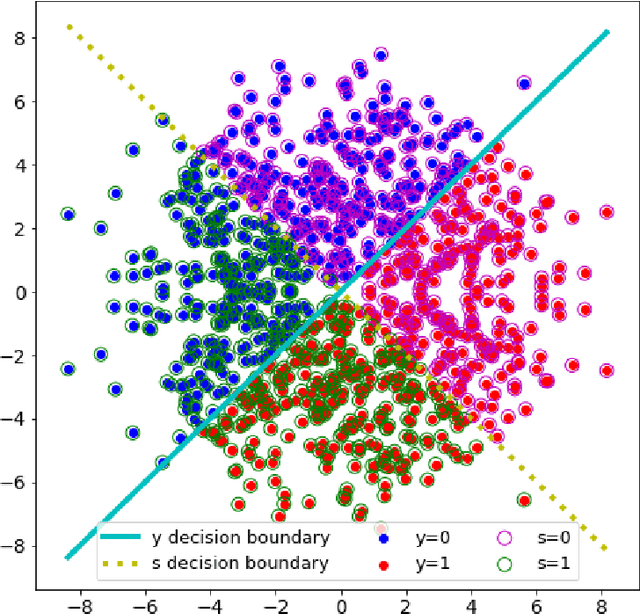
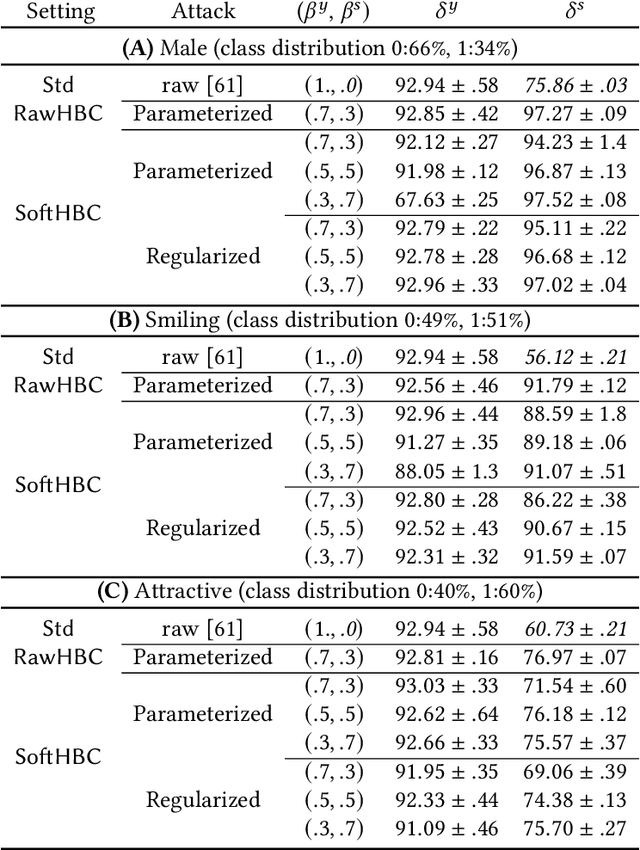
It is known that deep neural networks, trained for the classification of a non-sensitive target attribute, can reveal sensitive attributes of their input data; through features of different granularity extracted by the classifier. We, taking a step forward, show that deep classifiers can be trained to secretly encode a sensitive attribute of users' input data, at inference time, into the classifier's outputs for the target attribute. An attack that works even if users have a white-box view of the classifier, and can keep all internal representations hidden except for the classifier's estimation of the target attribute. We introduce an information-theoretical formulation of such adversaries and present efficient empirical implementations for training honest-but-curious (HBC) classifiers based on this formulation: deep models that can be accurate in predicting the target attribute, but also can utilize their outputs to secretly encode a sensitive attribute. Our evaluations on several tasks in real-world datasets show that a semi-trusted server can build a classifier that is not only perfectly honest but also accurately curious. Our work highlights a vulnerability that can be exploited by malicious machine learning service providers to attack their user's privacy in several seemingly safe scenarios; such as encrypted inferences, computations at the edge, or private knowledge distillation. We conclude by showing the difficulties in distinguishing between standard and HBC classifiers and discussing potential proactive defenses against this vulnerability of deep classifiers.
Dopamine: Differentially Private Federated Learning on Medical Data
Jan 29, 2021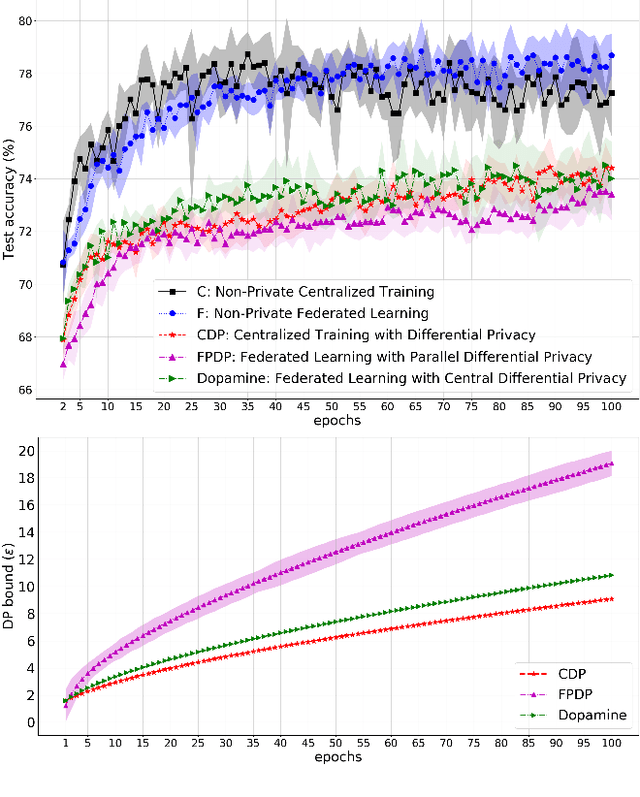
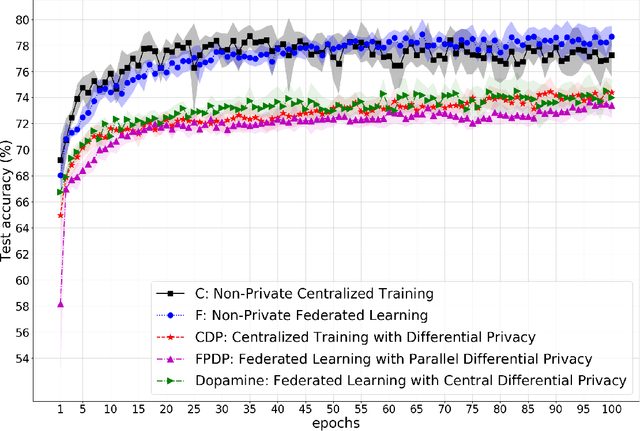
While rich medical datasets are hosted in hospitals distributed across the world, concerns on patients' privacy is a barrier against using such data to train deep neural networks (DNNs) for medical diagnostics. We propose Dopamine, a system to train DNNs on distributed datasets, which employs federated learning (FL) with differentially-private stochastic gradient descent (DPSGD), and, in combination with secure aggregation, can establish a better trade-off between differential privacy (DP) guarantee and DNN's accuracy than other approaches. Results on a diabetic retinopathy~(DR) task show that Dopamine provides a DP guarantee close to the centralized training counterpart, while achieving a better classification accuracy than FL with parallel DP where DPSGD is applied without coordination. Code is available at https://github.com/ipc-lab/private-ml-for-health.
Layer-wise Characterization of Latent Information Leakage in Federated Learning
Oct 17, 2020

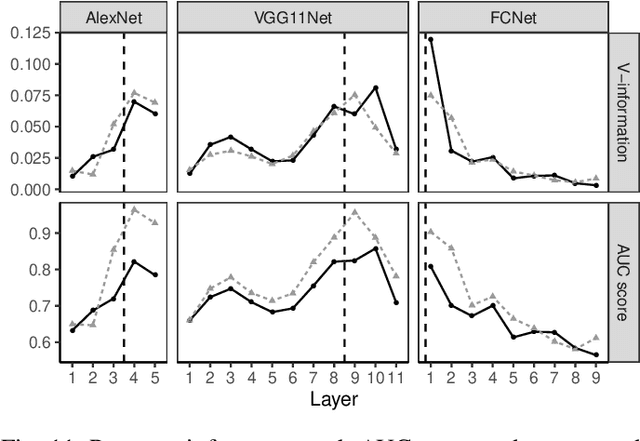
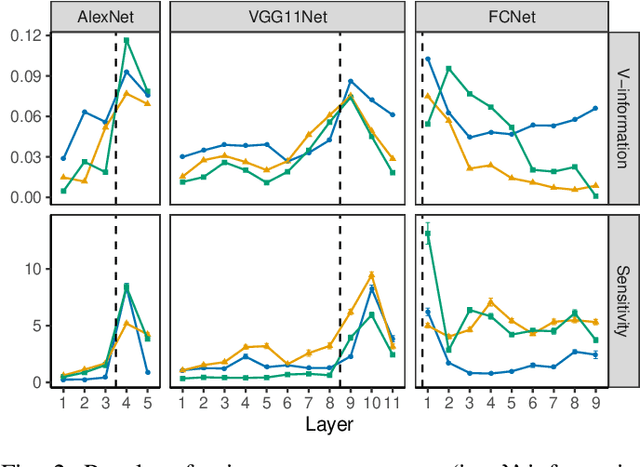
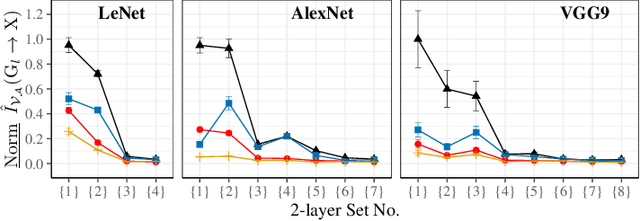
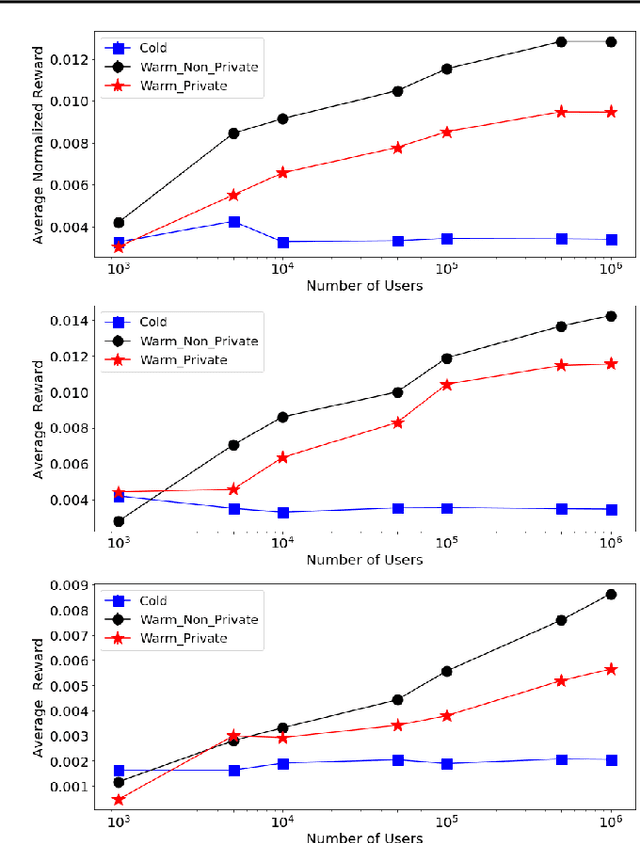
Training a deep neural network (DNN) via federated learning allows participants to share model updates (gradients), instead of the data itself. However, recent studies show that unintended latent information (e.g. gender or race) carried by the gradients can be discovered by attackers, compromising the promised privacy guarantee of federated learning. Existing privacy-preserving techniques (e.g. differential privacy) either have limited defensive capacity against the potential attacks, or suffer from considerable model utility loss. Moreover, characterizing the latent information carried by the gradients and the consequent privacy leakage has been a major theoretical and practical challenge. In this paper, we propose two new metrics to address these challenges: the empirical $\mathcal{V}$-information, a theoretically grounded notion of information which measures the amount of gradient information that is usable for an attacker, and the sensitivity analysis that utilizes the Jacobian matrix to measure the amount of changes in the gradients with respect to latent information which further quantifies private risk. We show that these metrics can localize the private information in each layer of a DNN and quantify the leakage depending on how sensitive the gradients are with respect to the latent information. As a practical application, we design LatenTZ: a federated learning framework that lets the most sensitive layers to run in the clients' Trusted Execution Environments (TEE). The implementation evaluation of LatenTZ shows that TEE-based approaches are promising for defending against powerful property inference attacks without a significant overhead in the clients' computing resources nor trading off the model's utility.
Running Neural Networks on the NIC
Sep 04, 2020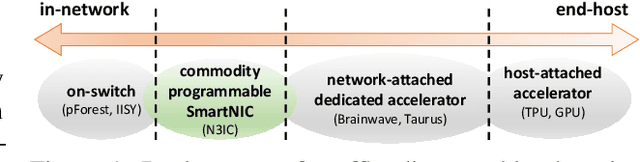
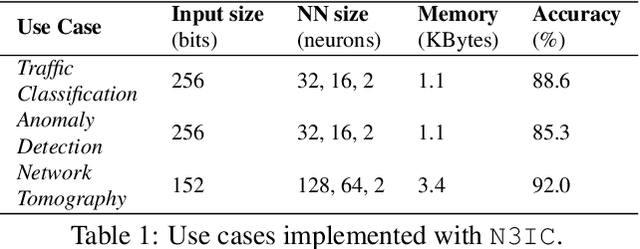

In this paper we show that the data plane of commodity programmable (Network Interface Cards) NICs can run neural network inference tasks required by packet monitoring applications, with low overhead. This is particularly important as the data transfer costs to the host system and dedicated machine learning accelerators, e.g., GPUs, can be more expensive than the processing task itself. We design and implement our system -- N3IC -- on two different NICs and we show that it can greatly benefit three different network monitoring use cases that require machine learning inference as first-class-primitive. N3IC can perform inference for millions of network flows per second, while forwarding traffic at 40Gb/s. Compared to an equivalent solution implemented on a general purpose CPU, N3IC can provide 100x lower processing latency, with 1.5x increase in throughput.
DANA: Dimension-Adaptive Neural Architecture for Multivariate Sensor Data
Aug 05, 2020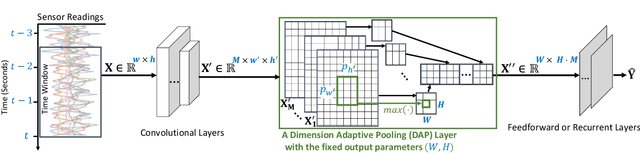
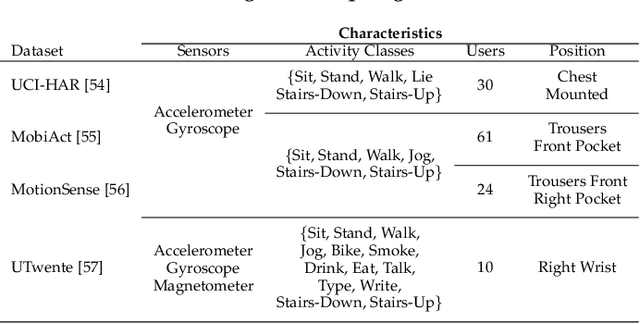
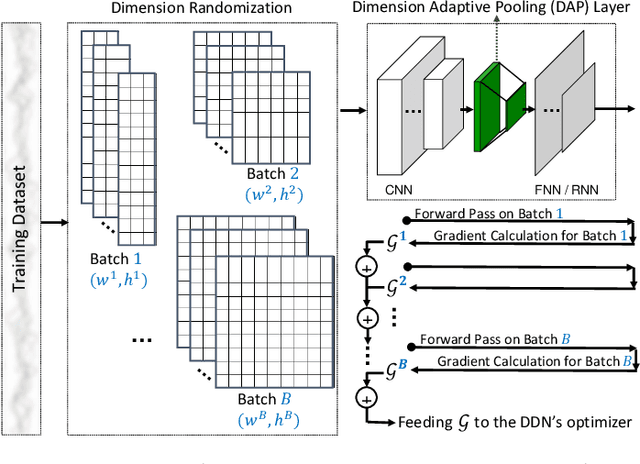
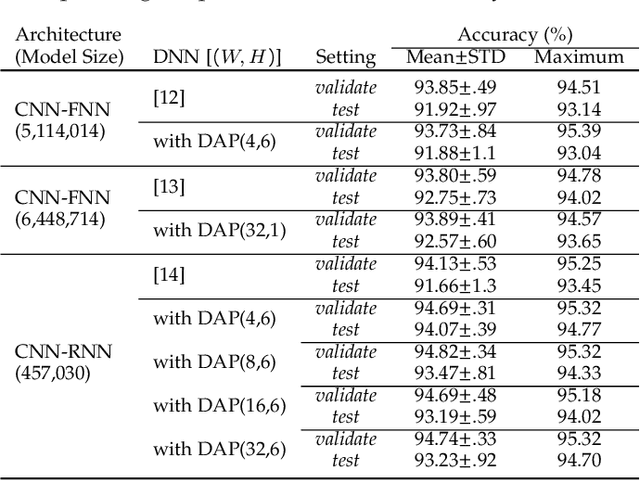
Current deep neural architectures for processing sensor data are mainly designed for data coming from a fixed set of sensors, with a fixed sampling rate. Changing the dimensions of the input data causes considerable accuracy loss, unnecessary computations, or application failures. To address this problem, we introduce a {\em dimension-adaptive pooling}~(DAP) layer that makes deep architectures robust to temporal changes in sampling rate and in sensor availability. DAP operates on convolutional filter maps of variable dimensions and produces an input of fixed dimensions suitable for feedforward and recurrent layers. Building on this architectural improvement, we propose a {\em dimension-adaptive training}~(DAT) procedure to generalize over the entire space of feasible data dimensions at the inference time. DAT comprises the random selection of dimensions during the forward passes and optimization with accumulated gradients of several backward passes. We then combine DAP and DAT to transform existing non-adaptive deep architectures into a {\em Dimension-Adaptive Neural Architecture}~(DANA) without altering other architectural aspects. Our solution does not need up-sampling or imputation, thus reduces unnecessary computations at inference time. Experimental results on public datasets show that DANA prevents losses in classification accuracy of the state-of-the-art deep architectures, under dynamic sensor availability and varying sampling rates.
Privacy and Utility Preserving Sensor-Data Transformations
Nov 14, 2019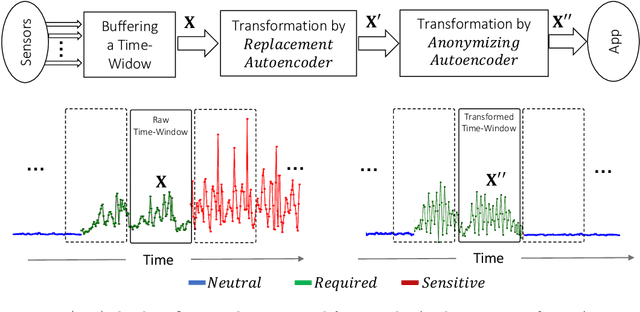
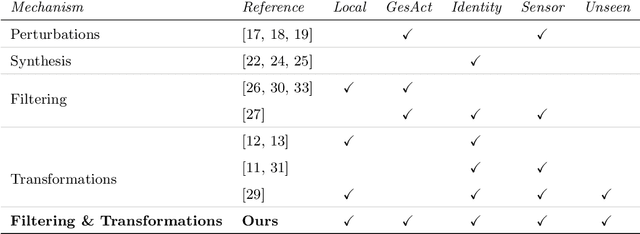

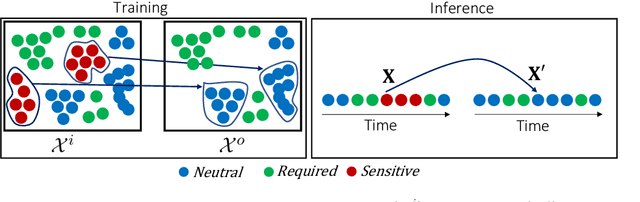
Sensitive inferences and user re-identification are major threats to privacy when raw sensor data from wearable or portable devices are shared with cloud-assisted applications. To mitigate these threats, we propose mechanisms to transform sensor data before sharing them with applications running on users' devices. These transformations aim at eliminating patterns that can be used for user re-identification or for inferring potentially sensitive activities, while introducing a minor utility loss for the target application (or task). We show that, on gesture and activity recognition tasks, we can prevent inference of potentially sensitive activities while keeping the reduction in recognition accuracy of non-sensitive activities to less than 5 percentage points. We also show that we can reduce the accuracy of user re-identification and of the potential inference of gender to the level of a random guess, while keeping the accuracy of activity recognition comparable to that obtained on the original data.
Privacy-Preserving Bandits
Sep 12, 2019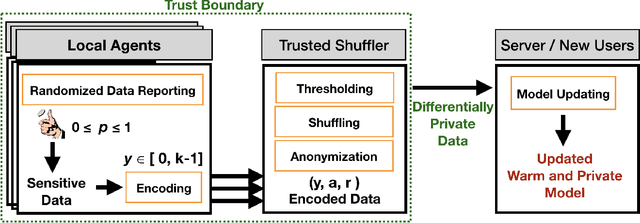
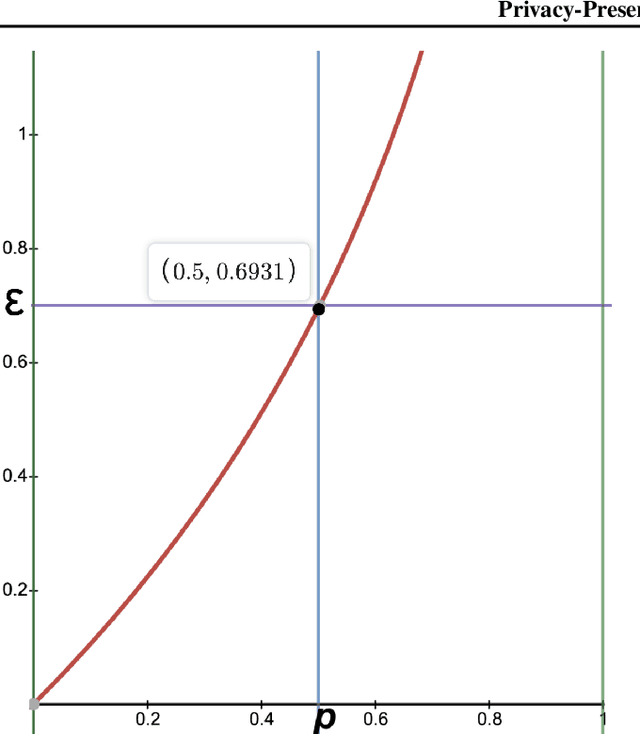
Contextual bandit algorithms (CBAs) often rely on personal data to provide recommendations. This means that potentially sensitive data from past interactions are utilized to provide personalization to end-users. Using a local agent on the user's device protects the user's privacy, by keeping the data locally, however, the agent requires longer to produce useful recommendations, as it does not leverage feedback from other users. This paper proposes a technique we call Privacy-Preserving Bandits (P2B), a system that updates local agents by collecting feedback from other agents in a differentially-private manner. Comparisons of our proposed approach with a non-private, as well as a fully-private (local) system, show competitive performance on both synthetic benchmarks and real-world data. Specifically, we observed a decrease of 2.6% and 3.6% in multi-label classification accuracy, and a CTR increase of 0.0025 in online advertising for a privacy budget $\epsilon \approx$ 0.693. These results suggest P2B is an effective approach to problems arising in on-device privacy-preserving personalization.
Modeling and Forecasting Art Movements with CGANs
Jun 21, 2019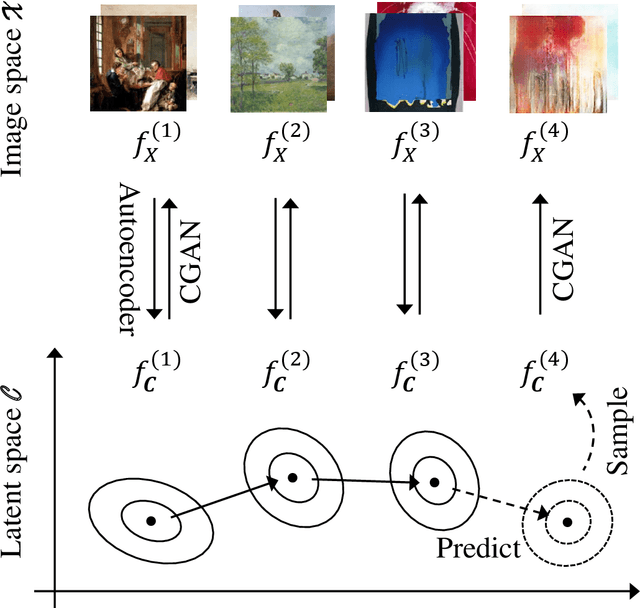


Conditional Generative Adversarial Networks (CGANs) are a recent and popular method for generating samples from a probability distribution conditioned on latent information. The latent information often comes in the form of a discrete label from a small set. We propose a novel method for training CGANs which allows us to condition on a sequence of continuous latent distributions $f^{(1)}, \ldots, f^{(K)}$. This training allows CGANs to generate samples from a sequence of distributions. We apply our method to paintings from a sequence of artistic movements, where each movement is considered to be its own distribution. Exploiting the temporal aspect of the data, a vector autoregressive (VAR) model is fitted to the means of the latent distributions that we learn, and used for one-step-ahead forecasting, to predict the latent distribution of a future art movement $f^{{(K+1)}}$. Realisations from this distribution can be used by the CGAN to generate "future" paintings. In experiments, this novel methodology generates accurate predictions of the evolution of art. The training set consists of a large dataset of past paintings. While there is no agreement on exactly what current art period we find ourselves in, we test on plausible candidate sets of present art, and show that the mean distance to our predictions is small.
Mobile Sensor Data Anonymization
Oct 26, 2018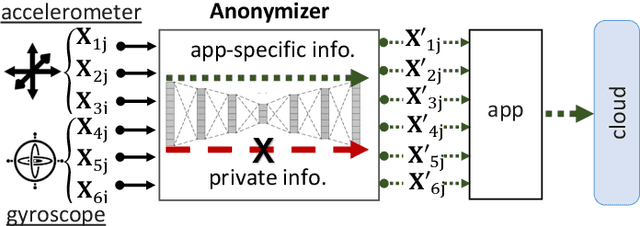
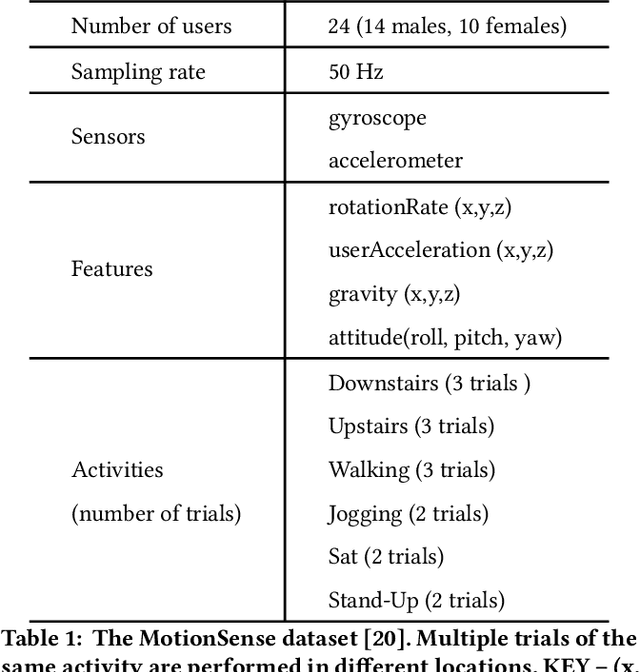
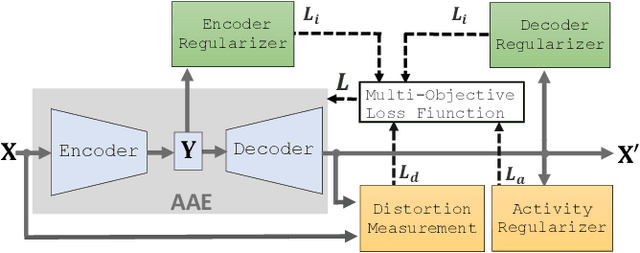
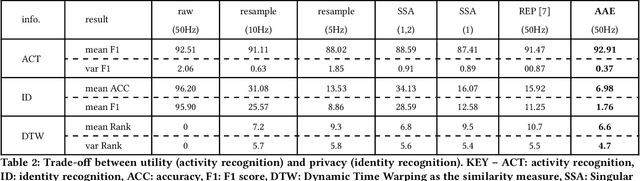
Data from motion sensors such as accelerometers and gyroscopes embedded in our devices can reveal secondary undesired, private information about our activities. This information can be used for malicious purposes such as user identification by application developers. To address this problem, we propose a data transformation mechanism that enables a device to share data for specific applications (e.g.~monitoring their daily activities) without revealing private user information (e.g.~ user identity). We formulate this anonymization process based on an information theoretic approach and propose a new multi-objective loss function for training convolutional auto-encoders~(CAEs) to provide a practical approximation to our anonymization problem. This effective loss function forces the transformed data to minimize the information about the user's identity, as well as the data distortion to preserve application-specific utility. Our training process regulates the encoder to disregard user-identifiable patterns and tunes the decoder to shape the final output independently of users in the training set. Then, a trained CAE can be deployed on a user's mobile device to anonymize sensor data before sharing with an app, even for users who are not included in the training dataset. The results, on a dataset of 24 users for activity recognition, show a promising trade-off on transformed data between utility and privacy, with an accuracy for activity recognition over 92%, while reducing the chance of identifying a user to less than 7%.