 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeProvable Gaussian Embedding with One Observation
Oct 25, 2018
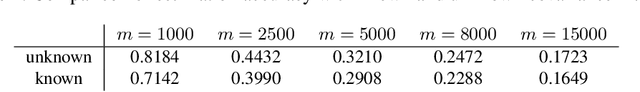
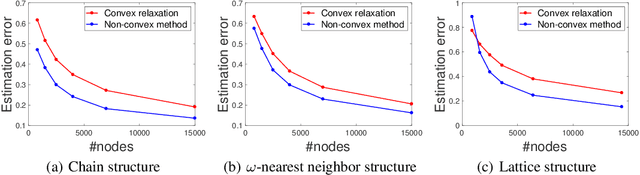
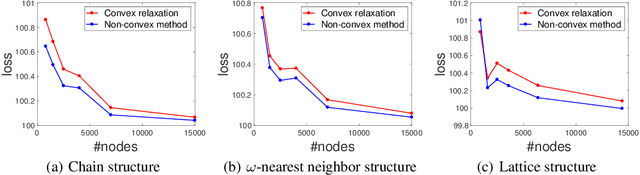
The success of machine learning methods heavily relies on having an appropriate representation for data at hand. Traditionally, machine learning approaches relied on user-defined heuristics to extract features encoding structural information about data. However, recently there has been a surge in approaches that learn how to encode the data automatically in a low dimensional space. Exponential family embedding provides a probabilistic framework for learning low-dimensional representation for various types of high-dimensional data. Though successful in practice, theoretical underpinnings for exponential family embeddings have not been established. In this paper, we study the Gaussian embedding model and develop the first theoretical results for exponential family embedding models. First, we show that, under mild condition, the embedding structure can be learned from one observation by leveraging the parameter sharing between different contexts even though the data are dependent with each other. Second, we study properties of two algorithms used for learning the embedding structure and establish convergence results for each of them. The first algorithm is based on a convex relaxation, while the other solved the non-convex formulation of the problem directly. Experiments demonstrate the effectiveness of our approach.
High-dimensional Varying Index Coefficient Models via Stein's Identity
Oct 21, 2018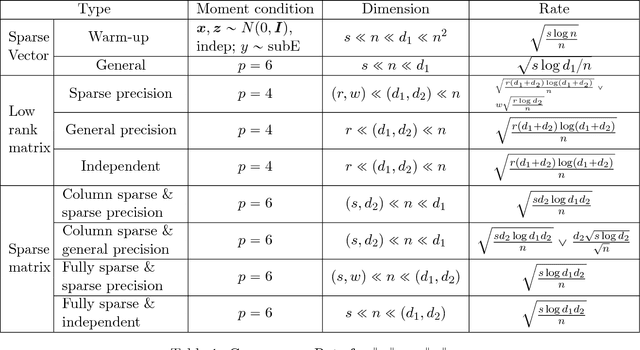
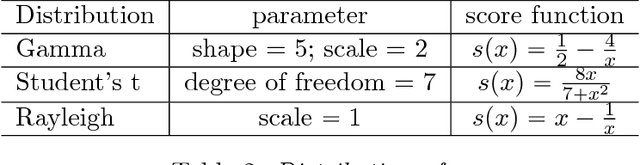
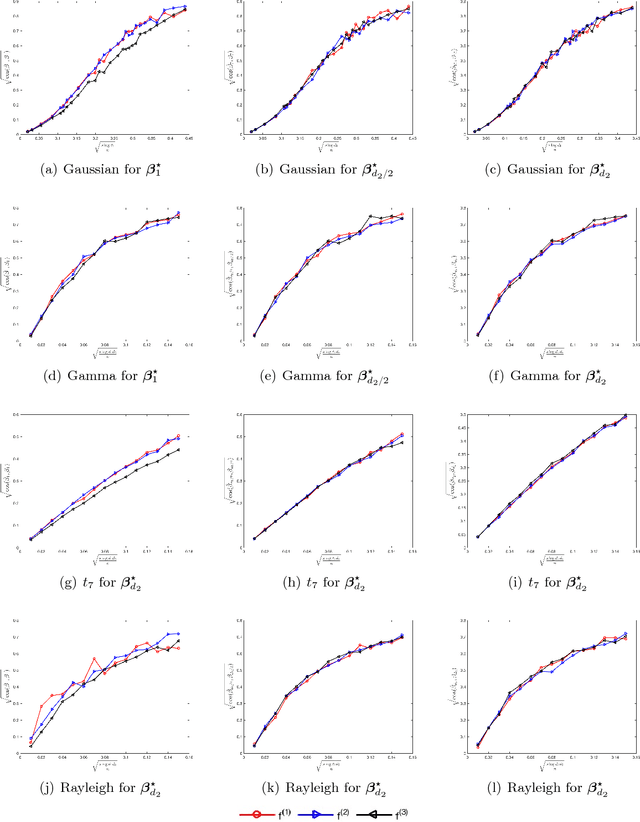
We study the parameter estimation problem for a varying index coefficient model in high dimensions. Unlike the most existing works that simultaneously estimate the parameters and link functions, based on the generalized Stein's identity, we propose computationally efficient estimators for the high dimensional parameters without estimating the link functions. We consider two different setups where we either estimate each sparse parameter vector individually or estimate the parameters simultaneously as a sparse or low-rank matrix. For all these cases, our estimators are shown to achieve optimal statistical rates of convergence (up to logarithmic terms in the low-rank setting). Moreover, throughout our analysis, we only require the covariate to satisfy certain moment conditions, which is significantly weaker than the Gaussian or elliptically symmetric assumptions that are commonly made in the existing literature. Finally, we conduct extensive numerical experiments to corroborate the theoretical results.
Joint Nonparametric Precision Matrix Estimation with Confounding
Oct 16, 2018
We consider the problem of precision matrix estimation where, due to extraneous confounding of the underlying precision matrix, the data are independent but not identically distributed. While such confounding occurs in many scientific problems, our approach is inspired by recent neuroscientific research suggesting that brain function, as measured using functional magnetic resonance imagine (fMRI), is susceptible to confounding by physiological noise such as breathing and subject motion. Following the scientific motivation, we propose a graphical model, which in turn motivates a joint nonparametric estimator. We provide theoretical guarantees for the consistency and the convergence rate of the proposed estimator. In addition, we demonstrate that the optimization of the proposed estimator can be transformed into a series of linear programming problems, and thus be efficiently solved in parallel. Empirical results are presented using simulated and real brain imaging data, which suggest that our approach improves precision matrix estimation, as compared to baselines, when confounding is present.
Learning Influence-Receptivity Network Structure with Guarantee
Jun 14, 2018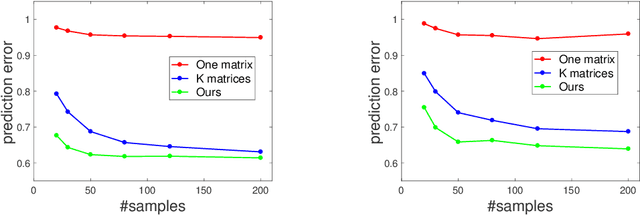
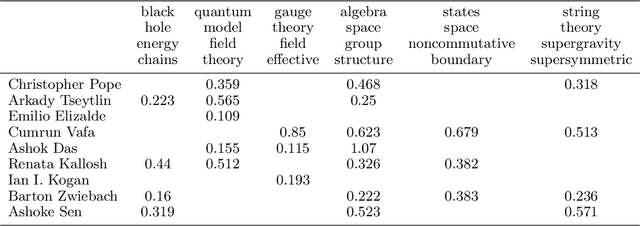


Traditional works on community detection from observations of information cascade assume that a single adjacency matrix parametrizes all the observed cascades. However, in reality the connection structure usually does not stay the same across cascades. For example, different people have different topics of interest, therefore the connection structure would depend on the information/topic content of the cascade. In this paper we consider the case where we observe a sequence of noisy adjacency matrices triggered by information/events with different topic distributions. We propose a novel latent model using the intuition that the connection is more likely to exist between two nodes if they are interested in similar topics, which are common with the information/event. Specifically, we endow each node two node-topic vectors: an influence vector that measures how much influential/authoritative they are on each topic; and a receptivity vector that measures how much receptive/susceptible they are to each topic. We show how these two node-topic structures can be estimated from observed adjacency matrices with theoretical guarantee, in cases where the topic distributions of the information/events are known, as well as when they are unknown. Extensive experiments on synthetic and real data demonstrate the effectiveness of our model.
Recovery of simultaneous low rank and two-way sparse coefficient matrices, a nonconvex approach
Feb 20, 2018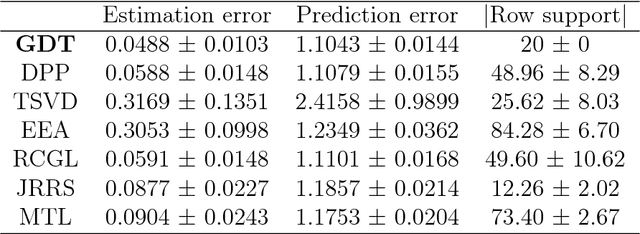
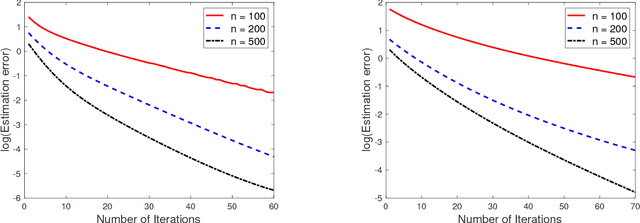
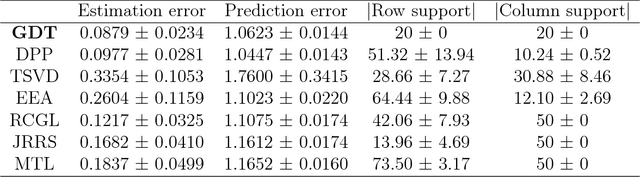
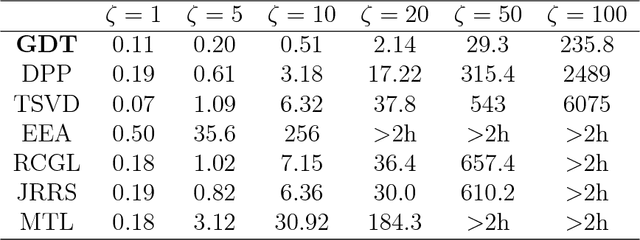
We study the problem of recovery of matrices that are simultaneously low rank and row and/or column sparse. Such matrices appear in recent applications in cognitive neuroscience, imaging, computer vision, macroeconomics, and genetics. We propose a GDT (Gradient Descent with hard Thresholding) algorithm to efficiently recover matrices with such structure, by minimizing a bi-convex function over a nonconvex set of constraints. We show linear convergence of the iterates obtained by GDT to a region within statistical error of an optimal solution. As an application of our method, we consider multi-task learning problems and show that the statistical error rate obtained by GDT is near optimal compared to minimax rate. Experiments demonstrate competitive performance and much faster running speed compared to existing methods, on both simulations and real data sets.
Post-Regularization Inference for Time-Varying Nonparanormal Graphical Models
Feb 12, 2018

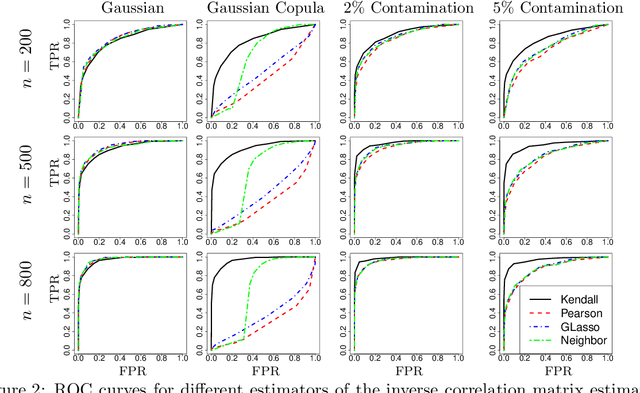

We propose a novel class of time-varying nonparanormal graphical models, which allows us to model high dimensional heavy-tailed systems and the evolution of their latent network structures. Under this model, we develop statistical tests for presence of edges both locally at a fixed index value and globally over a range of values. The tests are developed for a high-dimensional regime, are robust to model selection mistakes and do not require commonly assumed minimum signal strength. The testing procedures are based on a high dimensional, debiasing-free moment estimator, which uses a novel kernel smoothed Kendall's tau correlation matrix as an input statistic. The estimator consistently estimates the latent inverse Pearson correlation matrix uniformly in both the index variable and kernel bandwidth. Its rate of convergence is shown to be minimax optimal. Our method is supported by thorough numerical simulations and an application to a neural imaging data set.
Kernel Meets Sieve: Post-Regularization Confidence Bands for Sparse Additive Model
Feb 12, 2018
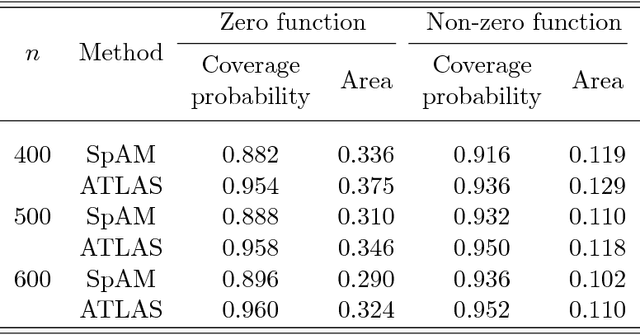
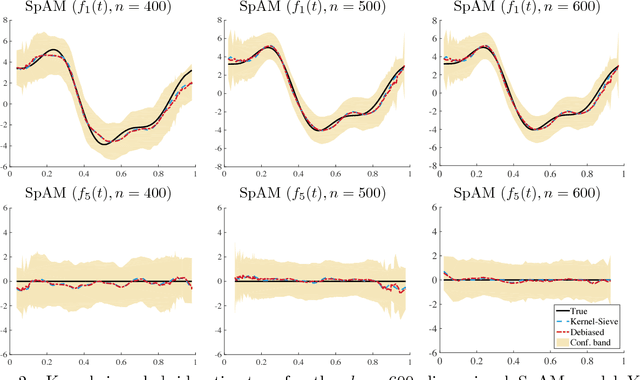
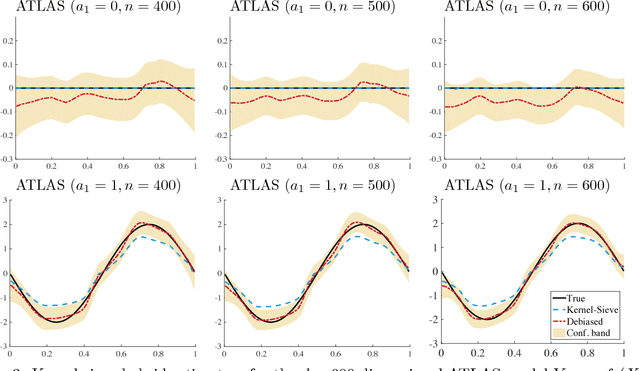
We develop a novel procedure for constructing confidence bands for components of a sparse additive model. Our procedure is based on a new kernel-sieve hybrid estimator that combines two most popular nonparametric estimation methods in the literature, the kernel regression and the spline method, and is of interest in its own right. Existing methods for fitting sparse additive model are primarily based on sieve estimators, while the literature on confidence bands for nonparametric models are primarily based upon kernel or local polynomial estimators. Our kernel-sieve hybrid estimator combines the best of both worlds and allows us to provide a simple procedure for constructing confidence bands in high-dimensional sparse additive models. We prove that the confidence bands are asymptotically honest by studying approximation with a Gaussian process. Thorough numerical results on both synthetic data and real-world neuroscience data are provided to demonstrate the efficacy of the theory.
Distributed Stochastic Multi-Task Learning with Graph Regularization
Feb 11, 2018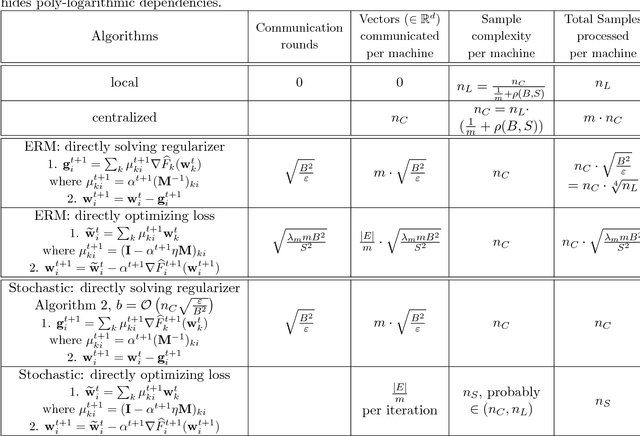
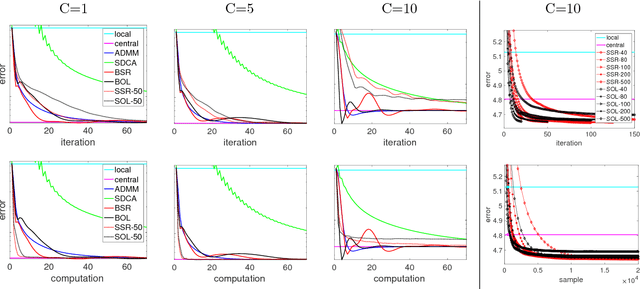
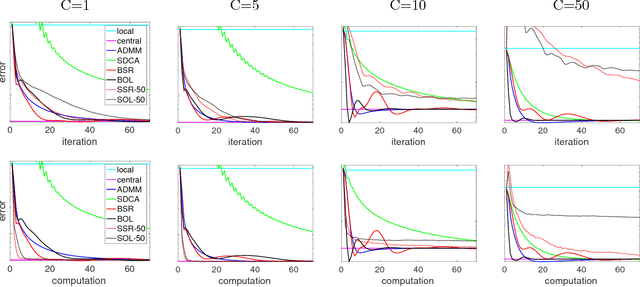
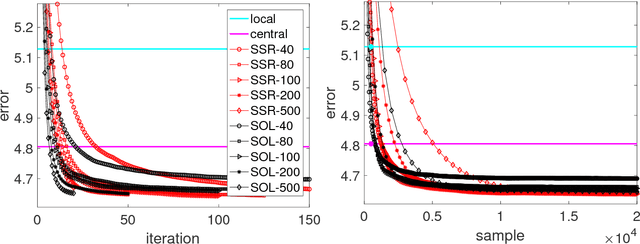
We propose methods for distributed graph-based multi-task learning that are based on weighted averaging of messages from other machines. Uniform averaging or diminishing stepsize in these methods would yield consensus (single task) learning. We show how simply skewing the averaging weights or controlling the stepsize allows learning different, but related, tasks on the different machines.
Scalable Peaceman-Rachford Splitting Method with Proximal Terms
Feb 10, 2018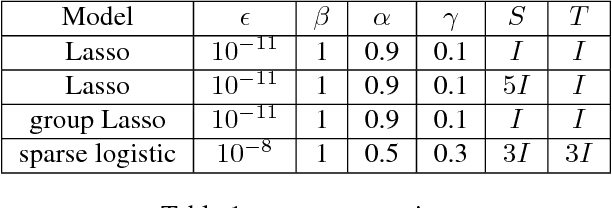
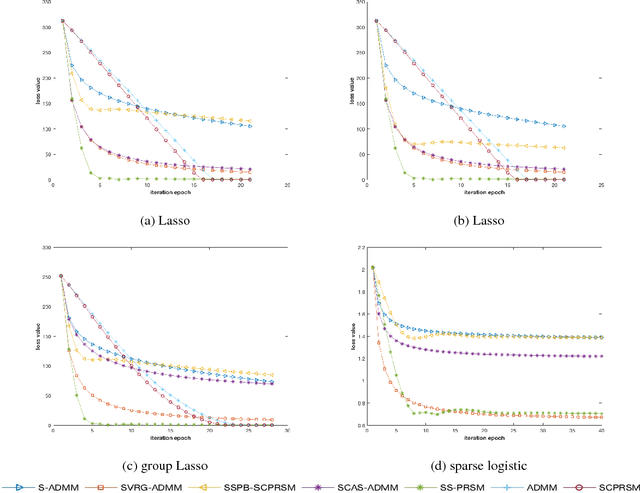

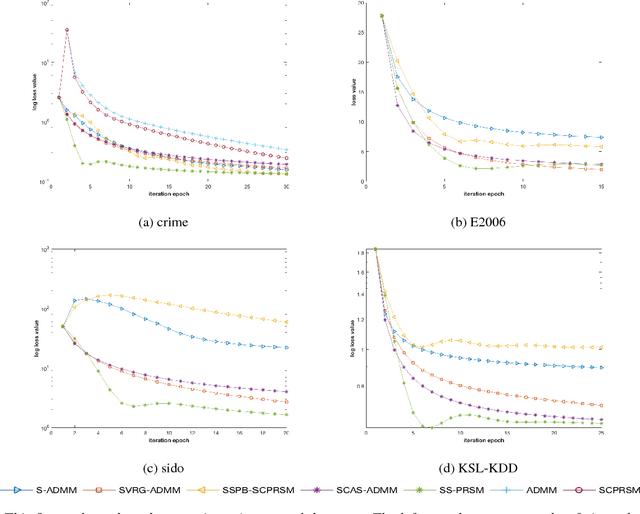
Along with developing of Peaceman-Rachford Splittling Method (PRSM), many batch algorithms based on it have been studied very deeply. But almost no algorithm focused on the performance of stochastic version of PRSM. In this paper, we propose a new stochastic algorithm based on PRSM, prove its convergence rate in ergodic sense, and test its performance on both artificial and real data. We show that our proposed algorithm, Stochastic Scalable PRSM (SS-PRSM), enjoys the $O(1/K)$ convergence rate, which is the same as those newest stochastic algorithms that based on ADMM but faster than general Stochastic ADMM (which is $O(1/\sqrt{K})$). Our algorithm also owns wide flexibility, outperforms many state-of-the-art stochastic algorithms coming from ADMM, and has low memory cost in large-scale splitting optimization problems.
An Influence-Receptivity Model for Topic based Information Cascades
Sep 06, 2017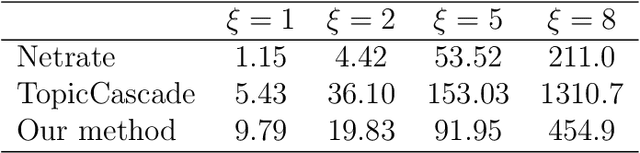
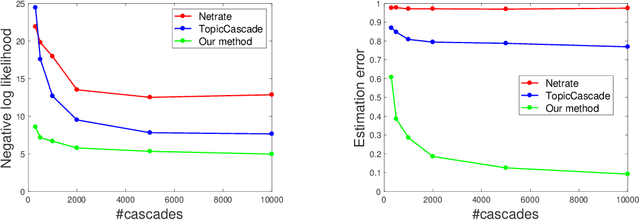

We consider the problem of estimating the latent structure of a social network based on observational data on information diffusion processes, or {\it cascades}. Here for a given cascade, we only observe the time a node/agent is infected but not the source of infection. Existing literature has focused on estimating network diffusion matrix without any underlying assumptions on the structure of the network. We propose a novel model for inferring network diffusion matrix based on the intuition that an information datum is more likely to propagate among two nodes if they are interested in similar topics, which are common with the information. In particular, our model endows each node with an influence vector (how authoritative they are on each topic) and a receptivity vector (how susceptible they are on each topic). We show how this node-topic structure can be estimated from observed cascades. The estimated model can be used to build recommendation system based on the receptivity vectors, as well as for marketing based on the influence vectors.