 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeNavigating the Conceptual Multiverse
Apr 21, 2026When language models answer open-ended problems, they implicitly make hidden decisions that shape their outputs, leaving users with uncontextualized answers rather than a working map of the problem; drawing on multiverse analysis from statistics, we build and evaluate the conceptual multiverse, an interactive system that represents conceptual decisions such as how to frame a question or what to value as a space users can transparently inspect, intervenably change, and check against principled domain reasoning; for this structure to be worth navigating rather than misleading, it must be rigorous and checkable against domain reasoning norms, so we develop a general verification framework that enforces properties of good decision structures like unambiguity and completeness calibrated by expert-level reasoning; across three domains, the conceptual multiverse helped participants develop a working map of the problem, with philosophy students rewriting essays with sharper framings and reversed theses, alignment annotators moving from surface preferences to reasoning about user intent and harm, and poets identifying compositional patterns that clarified their taste.
Penalizing Transparency? How AI Disclosure and Author Demographics Shape Human and AI Judgments About Writing
Jul 02, 2025


As AI integrates in various types of human writing, calls for transparency around AI assistance are growing. However, if transparency operates on uneven ground and certain identity groups bear a heavier cost for being honest, then the burden of openness becomes asymmetrical. This study investigates how AI disclosure statement affects perceptions of writing quality, and whether these effects vary by the author's race and gender. Through a large-scale controlled experiment, both human raters (n = 1,970) and LLM raters (n = 2,520) evaluated a single human-written news article while disclosure statements and author demographics were systematically varied. This approach reflects how both human and algorithmic decisions now influence access to opportunities (e.g., hiring, promotion) and social recognition (e.g., content recommendation algorithms). We find that both human and LLM raters consistently penalize disclosed AI use. However, only LLM raters exhibit demographic interaction effects: they favor articles attributed to women or Black authors when no disclosure is present. But these advantages disappear when AI assistance is revealed. These findings illuminate the complex relationships between AI disclosure and author identity, highlighting disparities between machine and human evaluation patterns.
Using Natural Sentences for Understanding Biases in Language Models
May 12, 2022
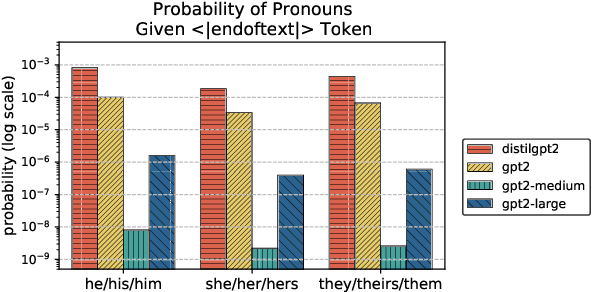

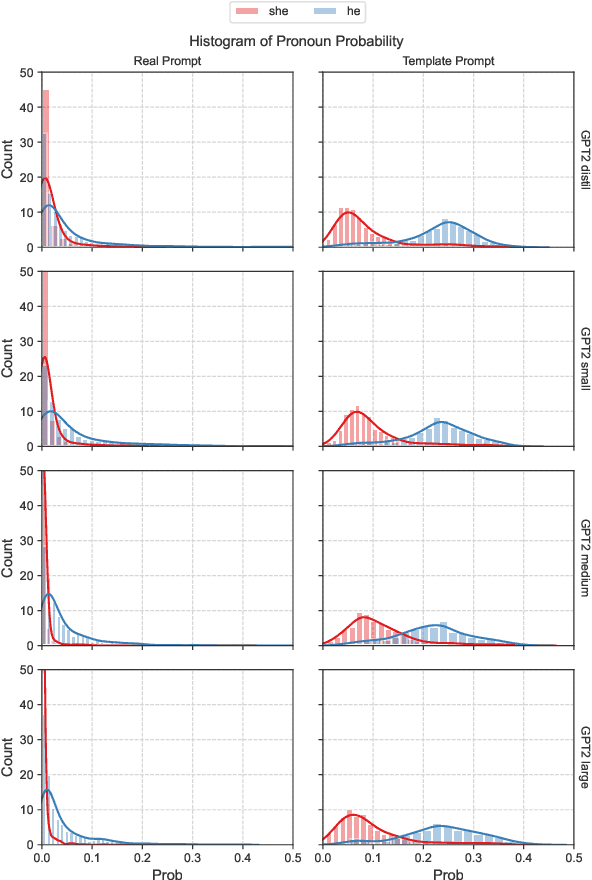
Evaluation of biases in language models is often limited to synthetically generated datasets. This dependence traces back to the need for a prompt-style dataset to trigger specific behaviors of language models. In this paper, we address this gap by creating a prompt dataset with respect to occupations collected from real-world natural sentences present in Wikipedia. We aim to understand the differences between using template-based prompts and natural sentence prompts when studying gender-occupation biases in language models. We find bias evaluations are very sensitive to the design choices of template prompts, and we propose using natural sentence prompts for systematic evaluations to step away from design choices that could introduce bias in the observations.