 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeMachine Learning-based Channel Prediction in Wideband Massive MIMO Systems with Small Overhead for Online Training
Aug 22, 2024



Channel prediction compensates for outdated channel state information in multiple-input multiple-output (MIMO) systems. Machine learning (ML) techniques have recently been implemented to design channel predictors by leveraging the temporal correlation of wireless channels. However, most ML-based channel prediction techniques have only considered offline training when generating channel predictors, which can result in poor performance when encountering channel environments different from the ones they were trained on. To ensure prediction performance in varying channel conditions, we propose an online re-training framework that trains the channel predictor from scratch to effectively capture and respond to changes in the wireless environment. The training time includes data collection time and neural network training time, and should be minimized for practical channel predictors. To reduce the training time, especially data collection time, we propose a novel ML-based channel prediction technique called aggregated learning (AL) approach for wideband massive MIMO systems. In the proposed AL approach, the training data can be split and aggregated either in an array domain or frequency domain, which are the channel domains of MIMO-OFDM systems. This processing can significantly reduce the time for data collection. Our numerical results show that the AL approach even improves channel prediction performance in various scenarios with small training time overhead.
Neural Speech and Audio Coding
Aug 13, 2024This paper explores the integration of model-based and data-driven approaches within the realm of neural speech and audio coding systems. It highlights the challenges posed by the subjective evaluation processes of speech and audio codecs and discusses the limitations of purely data-driven approaches, which often require inefficiently large architectures to match the performance of model-based methods. The study presents hybrid systems as a viable solution, offering significant improvements to the performance of conventional codecs through meticulously chosen design enhancements. Specifically, it introduces a neural network-based signal enhancer designed to post-process existing codecs' output, along with the autoencoder-based end-to-end models and LPCNet--hybrid systems that combine linear predictive coding (LPC) with neural networks. Furthermore, the paper delves into predictive models operating within custom feature spaces (TF-Codec) or predefined transform domains (MDCTNet) and examines the use of psychoacoustically calibrated loss functions to train end-to-end neural audio codecs. Through these investigations, the paper demonstrates the potential of hybrid systems to advance the field of speech and audio coding by bridging the gap between traditional model-based approaches and modern data-driven techniques.
Multimodal Representation Loss Between Timed Text and Audio for Regularized Speech Separation
Jun 12, 2024Recent studies highlight the potential of textual modalities in conditioning the speech separation model's inference process. However, regularization-based methods remain underexplored despite their advantages of not requiring auxiliary text data during the test time. To address this gap, we introduce a timed text-based regularization (TTR) method that uses language model-derived semantics to improve speech separation models. Our approach involves two steps. We begin with two pretrained audio and language models, WavLM and BERT, respectively. Then, a Transformer-based audio summarizer is learned to align the audio and word embeddings and to minimize their gap. The summarizer Transformer, incorporated as a regularizer, promotes the separated sources' alignment with the semantics from the timed text. Experimental results show that the proposed TTR method consistently improves the various objective metrics of the separation results over the unregularized baselines.
Personalized Neural Speech Codec
Mar 31, 2024In this paper, we propose a personalized neural speech codec, envisioning that personalization can reduce the model complexity or improve perceptual speech quality. Despite the common usage of speech codecs where only a single talker is involved on each side of the communication, personalizing a codec for the specific user has rarely been explored in the literature. First, we assume speakers can be grouped into smaller subsets based on their perceptual similarity. Then, we also postulate that a group-specific codec can focus on the group's speech characteristics to improve its perceptual quality and computational efficiency. To this end, we first develop a Siamese network that learns the speaker embeddings from the LibriSpeech dataset, which are then grouped into underlying speaker clusters. Finally, we retrain the LPCNet-based speech codec baselines on each of the speaker clusters. Subjective listening tests show that the proposed personalization scheme introduces model compression while maintaining speech quality. In other words, with the same model complexity, personalized codecs produce better speech quality.
A Comparative Analysis of Poetry Reading Audio: Singing, Narrating, or Somewhere In Between?
Mar 31, 2024



This paper provides a computational analysis of poetry reading audio signals at a large scale to unveil the musicality within professionally-read poems. Although the acoustic characteristics of other types of spoken language have been extensively studied, most of the literature is limited to narrative speech or singing voice, discussing how different they are from each other. In this work, we develop signal processing methods, which are tailored to capture the unique acoustic characteristics of poetry reading based on their silence patterns, temporal variations of local pitch, and beat stability. Our large-scale statistical analyses on three big corpora, each of which consists of narration (LibriSpeech), singing voice (Intonation), and poetry reading (from The Poetry Foundation), discover that poetry reading does share some musical characteristics with singing voice, although it may also resemble narrative speech.
Meta-Heuristic Fronthaul Bit Allocation for Cell-free Massive MIMO Systems
Mar 28, 2024Limited capacity of fronthaul links in a cell-free massive multiple-input multiple-output (MIMO) system can cause quantization errors at a central processing unit (CPU) during data transmission, complicating the centralized rate optimization problem. Addressing this challenge, we propose a harmony search (HS)-based algorithm that renders the combinatorial non-convex problem tractable. One of the distinctive features of our algorithm is its hierarchical structure: it first allocates resources at the access point (AP) level and subsequently optimizes for user equipment (UE), ensuring a more efficient and structured approach to resource allocation. Our proposed algorithm deals with rigorous conditions, such as asymmetric fronthaul bit allocation and distinct quantization error levels at each AP, which were not considered in previous works. We derive a closed-form expression of signal-to-interference-plusnoise ratio (SINR), in which additive quantization noise model (AQNM) based distortion error is taken into account, to define the mathematical expression of spectral efficiency (SE) for each UE. Also, we provide analyses on computational complexity and convergence to investigate the practicality of proposed algorithm. By leveraging various performance metrics such as total SE and max-min fairness, we demonstrate that the proposed algorithm can adaptively optimize the fronthaul bit allocation depending on system requirements. Finally, simulation results show that the proposed algorithm can achieve satisfactory performance while maintaining low computational complexity, as compared to the exhaustive search method
BiTT: Bi-directional Texture Reconstruction of Interacting Two Hands from a Single Image
Mar 21, 2024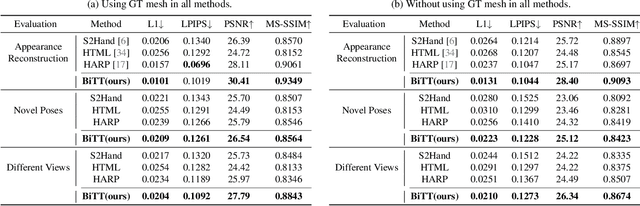
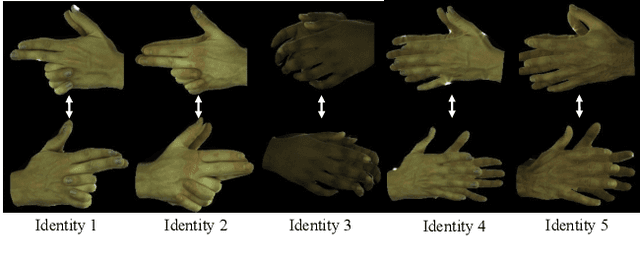
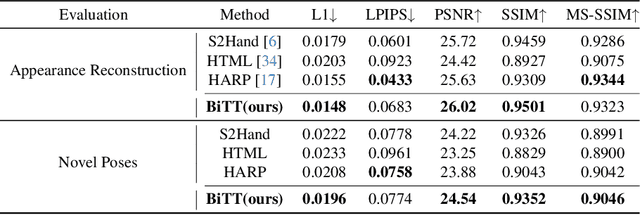
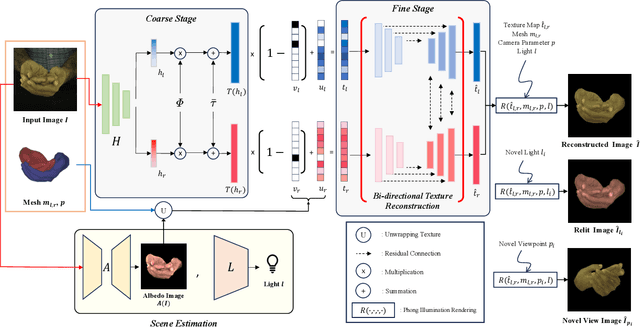
Creating personalized hand avatars is important to offer a realistic experience to users on AR / VR platforms. While most prior studies focused on reconstructing 3D hand shapes, some recent work has tackled the reconstruction of hand textures on top of shapes. However, these methods are often limited to capturing pixels on the visible side of a hand, requiring diverse views of the hand in a video or multiple images as input. In this paper, we propose a novel method, BiTT(Bi-directional Texture reconstruction of Two hands), which is the first end-to-end trainable method for relightable, pose-free texture reconstruction of two interacting hands taking only a single RGB image, by three novel components: 1) bi-directional (left $\leftrightarrow$ right) texture reconstruction using the texture symmetry of left / right hands, 2) utilizing a texture parametric model for hand texture recovery, and 3) the overall coarse-to-fine stage pipeline for reconstructing personalized texture of two interacting hands. BiTT first estimates the scene light condition and albedo image from an input image, then reconstructs the texture of both hands through the texture parametric model and bi-directional texture reconstructor. In experiments using InterHand2.6M and RGB2Hands datasets, our method significantly outperforms state-of-the-art hand texture reconstruction methods quantitatively and qualitatively. The code is available at https://github.com/yunminjin2/BiTT
AiSDF: Structure-aware Neural Signed Distance Fields in Indoor Scenes
Mar 04, 2024



Indoor scenes we are living in are visually homogenous or textureless, while they inherently have structural forms and provide enough structural priors for 3D scene reconstruction. Motivated by this fact, we propose a structure-aware online signed distance fields (SDF) reconstruction framework in indoor scenes, especially under the Atlanta world (AW) assumption. Thus, we dub this incremental SDF reconstruction for AW as AiSDF. Within the online framework, we infer the underlying Atlanta structure of a given scene and then estimate planar surfel regions supporting the Atlanta structure. This Atlanta-aware surfel representation provides an explicit planar map for a given scene. In addition, based on these Atlanta planar surfel regions, we adaptively sample and constrain the structural regularity in the SDF reconstruction, which enables us to improve the reconstruction quality by maintaining a high-level structure while enhancing the details of a given scene. We evaluate the proposed AiSDF on the ScanNet and ReplicaCAD datasets, where we demonstrate that the proposed framework is capable of reconstructing fine details of objects implicitly, as well as structures explicitly in room-scale scenes.
Analyzing Downlink Coverage in Clustered Low Earth Orbit Satellite Constellations: A Stochastic Geometry Approach
Feb 26, 2024



Satellite networks are emerging as vital solutions for global connectivity beyond 5G. As companies such as SpaceX, OneWeb, and Amazon are poised to launch a large number of satellites in low Earth orbit, the heightened inter-satellite interference caused by mega-constellations has become a significant concern. To address this challenge, recent works have introduced the concept of satellite cluster networks where multiple satellites in a cluster collaborate to enhance the network performance. In order to investigate the performance of these networks, we propose mathematical analyses by modeling the locations of satellites and users using Poisson point processes, building on the success of stochastic geometry-based analyses for satellite networks. In particular, we suggest the lower and upper bounds of the coverage probability as functions of the system parameters, including satellite density, satellite altitude, satellite cluster area, path loss exponent, and Nakagami parameter $m$. We validate the analytical expressions by comparing them with simulation results. Our analyses can be used to design reliable satellite cluster networks by effectively estimating the impact of system parameters on the coverage performance.
Hyperbolic Distance-Based Speech Separation
Jan 07, 2024In this work, we explore the task of hierarchical distance-based speech separation defined on a hyperbolic manifold. Based on the recent advent of audio-related tasks performed in non-Euclidean spaces, we propose to make use of the Poincar\'e ball to effectively unveil the inherent hierarchical structure found in complex speaker mixtures. We design two sets of experiments in which the distance-based parent sound classes, namely "near" and "far", can contain up to two or three speakers (i.e., children) each. We show that our hyperbolic approach is suitable for unveiling hierarchical structure from the problem definition, resulting in improved child-level separation. We further show that a clear correlation emerges between the notion of hyperbolic certainty (i.e., the distance to the ball's origin) and acoustic semantics such as speaker density, inter-source location, and microphone-to-speaker distance.