 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeTopology-Informed Graph Transformer
Feb 03, 2024



Transformers have revolutionized performance in Natural Language Processing and Vision, paving the way for their integration with Graph Neural Networks (GNNs). One key challenge in enhancing graph transformers is strengthening the discriminative power of distinguishing isomorphisms of graphs, which plays a crucial role in boosting their predictive performances. To address this challenge, we introduce 'Topology-Informed Graph Transformer (TIGT)', a novel transformer enhancing both discriminative power in detecting graph isomorphisms and the overall performance of Graph Transformers. TIGT consists of four components: A topological positional embedding layer using non-isomorphic universal covers based on cyclic subgraphs of graphs to ensure unique graph representation: A dual-path message-passing layer to explicitly encode topological characteristics throughout the encoder layers: A global attention mechanism: And a graph information layer to recalibrate channel-wise graph features for better feature representation. TIGT outperforms previous Graph Transformers in classifying synthetic dataset aimed at distinguishing isomorphism classes of graphs. Additionally, mathematical analysis and empirical evaluations highlight our model's competitive edge over state-of-the-art Graph Transformers across various benchmark datasets.
A Gated MLP Architecture for Learning Topological Dependencies in Spatio-Temporal Graphs
Jan 29, 2024Graph Neural Networks (GNNs) and Transformer have been increasingly adopted to learn the complex vector representations of spatio-temporal graphs, capturing intricate spatio-temporal dependencies crucial for applications such as traffic datasets. Although many existing methods utilize multi-head attention mechanisms and message-passing neural networks (MPNNs) to capture both spatial and temporal relations, these approaches encode temporal and spatial relations independently, and reflect the graph's topological characteristics in a limited manner. In this work, we introduce the Cycle to Mixer (Cy2Mixer), a novel spatio-temporal GNN based on topological non-trivial invariants of spatio-temporal graphs with gated multi-layer perceptrons (gMLP). The Cy2Mixer is composed of three blocks based on MLPs: A message-passing block for encapsulating spatial information, a cycle message-passing block for enriching topological information through cyclic subgraphs, and a temporal block for capturing temporal properties. We bolster the effectiveness of Cy2Mixer with mathematical evidence emphasizing that our cycle message-passing block is capable of offering differentiated information to the deep learning model compared to the message-passing block. Furthermore, empirical evaluations substantiate the efficacy of the Cy2Mixer, demonstrating state-of-the-art performances across various traffic benchmark datasets.
Model-Free Reconstruction of Capacity Degradation Trajectory of Lithium-Ion Batteries Using Early Cycle Data
Mar 31, 2023



Early degradation prediction of lithium-ion batteries is crucial for ensuring safety and preventing unexpected failure in manufacturing and diagnostic processes. Long-term capacity trajectory predictions can fail due to cumulative errors and noise. To address this issue, this study proposes a data-centric method that uses early single-cycle data to predict the capacity degradation trajectory of lithium-ion cells. The method involves predicting a few knots at specific retention levels using a deep learning-based model and interpolating them to reconstruct the trajectory. Two approaches are used to identify the retention levels of two to four knots: uniformly dividing the retention up to the end of life and finding optimal locations using Bayesian optimization. The proposed model is validated with experimental data from 169 cells using five-fold cross-validation. The results show that mean absolute percentage errors in trajectory prediction are less than 1.60% for all cases of knots. By predicting only the cycle numbers of at least two knots based on early single-cycle charge and discharge data, the model can directly estimate the overall capacity degradation trajectory. Further experiments suggest using three-cycle input data to achieve robust and efficient predictions, even in the presence of noise. The method is then applied to predict various shapes of capacity degradation patterns using additional experimental data from 82 cells. The study demonstrates that collecting only the cycle information of a few knots during model training and a few early cycle data points for predictions is sufficient for predicting capacity degradation. This can help establish appropriate warranties or replacement cycles in battery manufacturing and diagnosis processes.
Biomedical image analysis competitions: The state of current participation practice
Dec 16, 2022The number of international benchmarking competitions is steadily increasing in various fields of machine learning (ML) research and practice. So far, however, little is known about the common practice as well as bottlenecks faced by the community in tackling the research questions posed. To shed light on the status quo of algorithm development in the specific field of biomedical imaging analysis, we designed an international survey that was issued to all participants of challenges conducted in conjunction with the IEEE ISBI 2021 and MICCAI 2021 conferences (80 competitions in total). The survey covered participants' expertise and working environments, their chosen strategies, as well as algorithm characteristics. A median of 72% challenge participants took part in the survey. According to our results, knowledge exchange was the primary incentive (70%) for participation, while the reception of prize money played only a minor role (16%). While a median of 80 working hours was spent on method development, a large portion of participants stated that they did not have enough time for method development (32%). 25% perceived the infrastructure to be a bottleneck. Overall, 94% of all solutions were deep learning-based. Of these, 84% were based on standard architectures. 43% of the respondents reported that the data samples (e.g., images) were too large to be processed at once. This was most commonly addressed by patch-based training (69%), downsampling (37%), and solving 3D analysis tasks as a series of 2D tasks. K-fold cross-validation on the training set was performed by only 37% of the participants and only 50% of the participants performed ensembling based on multiple identical models (61%) or heterogeneous models (39%). 48% of the respondents applied postprocessing steps.
Adversarial Lagrangian Integrated Contrastive Embedding for Limited Size Datasets
Oct 06, 2022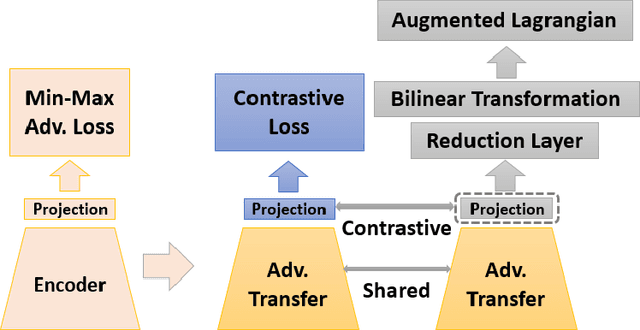
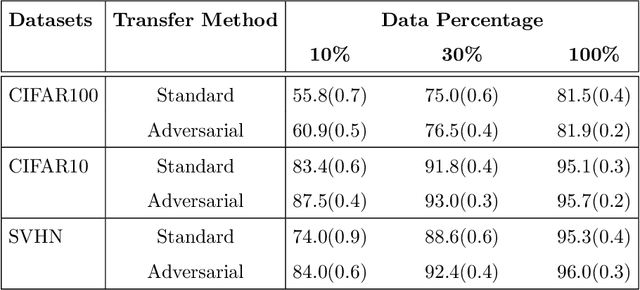

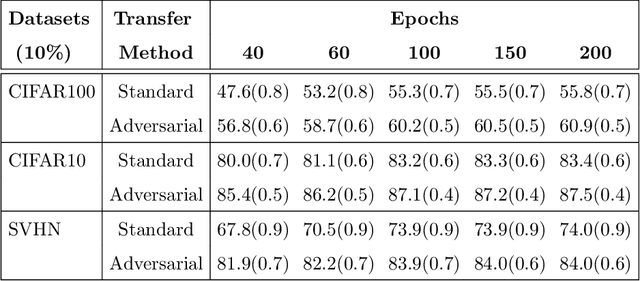
Certain datasets contain a limited number of samples with highly various styles and complex structures. This study presents a novel adversarial Lagrangian integrated contrastive embedding (ALICE) method for small-sized datasets. First, the accuracy improvement and training convergence of the proposed pre-trained adversarial transfer are shown on various subsets of datasets with few samples. Second, a novel adversarial integrated contrastive model using various augmentation techniques is investigated. The proposed structure considers the input samples with different appearances and generates a superior representation with adversarial transfer contrastive training. Finally, multi-objective augmented Lagrangian multipliers encourage the low-rank and sparsity of the presented adversarial contrastive embedding to adaptively estimate the coefficients of the regularizers automatically to the optimum weights. The sparsity constraint suppresses less representative elements in the feature space. The low-rank constraint eliminates trivial and redundant components and enables superior generalization. The performance of the proposed model is verified by conducting ablation studies by using benchmark datasets for scenarios with small data samples.
Where is VALDO? VAscular Lesions Detection and segmentatiOn challenge at MICCAI 2021
Aug 15, 2022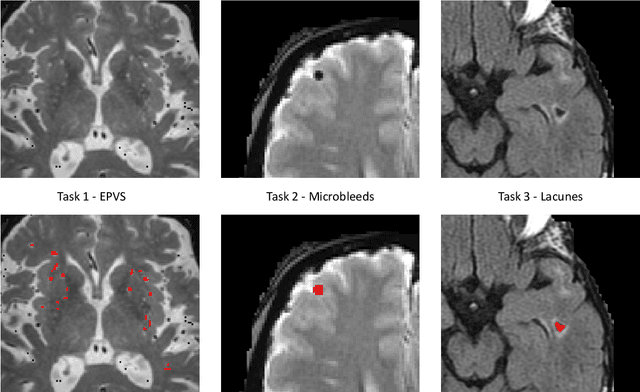
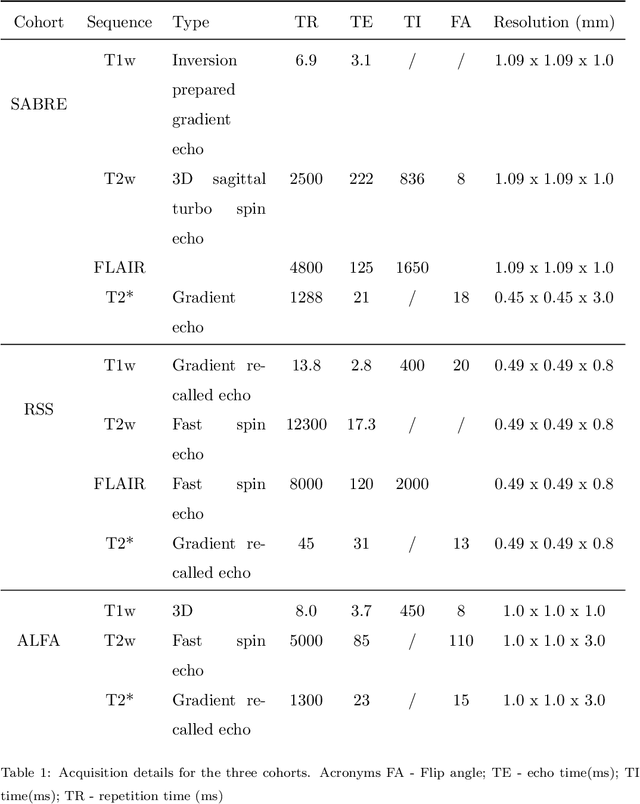
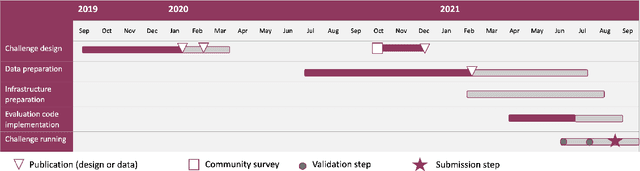
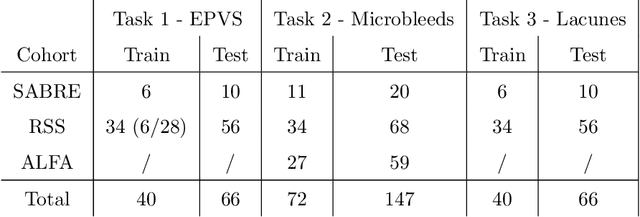
Imaging markers of cerebral small vessel disease provide valuable information on brain health, but their manual assessment is time-consuming and hampered by substantial intra- and interrater variability. Automated rating may benefit biomedical research, as well as clinical assessment, but diagnostic reliability of existing algorithms is unknown. Here, we present the results of the \textit{VAscular Lesions DetectiOn and Segmentation} (\textit{Where is VALDO?}) challenge that was run as a satellite event at the international conference on Medical Image Computing and Computer Aided Intervention (MICCAI) 2021. This challenge aimed to promote the development of methods for automated detection and segmentation of small and sparse imaging markers of cerebral small vessel disease, namely enlarged perivascular spaces (EPVS) (Task 1), cerebral microbleeds (Task 2) and lacunes of presumed vascular origin (Task 3) while leveraging weak and noisy labels. Overall, 12 teams participated in the challenge proposing solutions for one or more tasks (4 for Task 1 - EPVS, 9 for Task 2 - Microbleeds and 6 for Task 3 - Lacunes). Multi-cohort data was used in both training and evaluation. Results showed a large variability in performance both across teams and across tasks, with promising results notably for Task 1 - EPVS and Task 2 - Microbleeds and not practically useful results yet for Task 3 - Lacunes. It also highlighted the performance inconsistency across cases that may deter use at an individual level, while still proving useful at a population level.
Meta-Learned Invariant Risk Minimization
Mar 24, 2021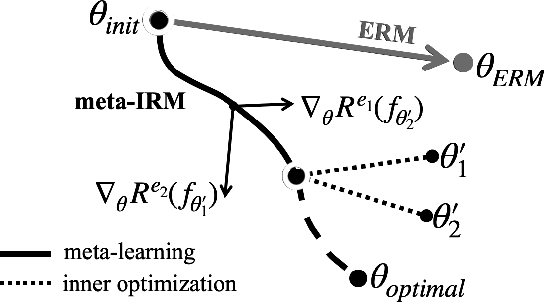
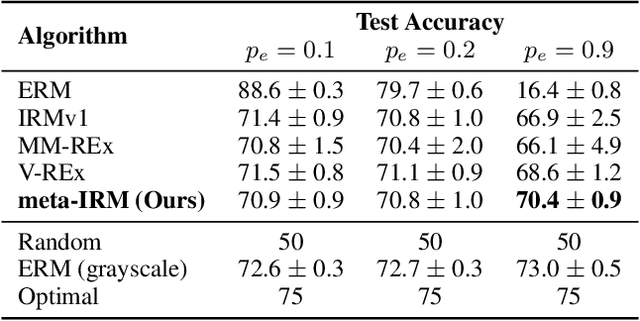
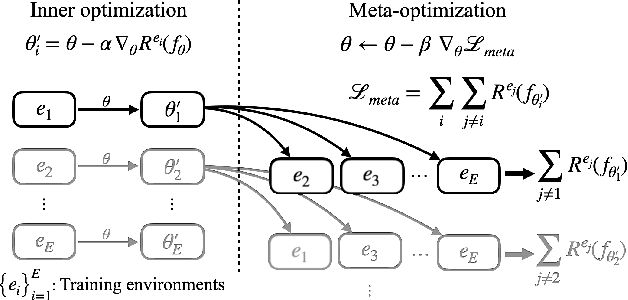
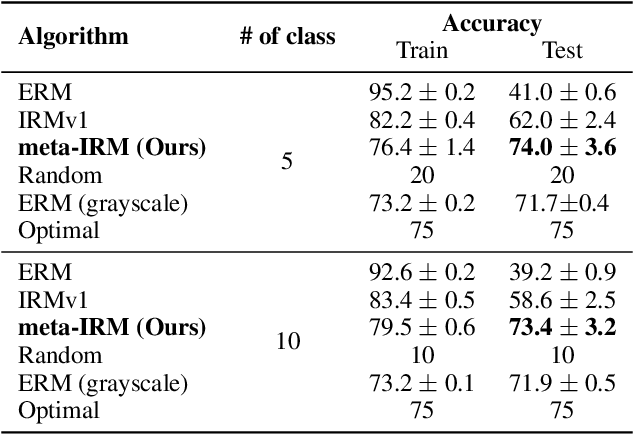
Empirical Risk Minimization (ERM) based machine learning algorithms have suffered from weak generalization performance on data obtained from out-of-distribution (OOD). To address this problem, Invariant Risk Minimization (IRM) objective was suggested to find invariant optimal predictor which is less affected by the changes in data distribution. However, even with such progress, IRMv1, the practical formulation of IRM, still shows performance degradation when there are not enough training data, and even fails to generalize to OOD, if the number of spurious correlations is larger than the number of environments. In this paper, to address such problems, we propose a novel meta-learning based approach for IRM. In this method, we do not assume the linearity of classifier for the ease of optimization, and solve ideal bi-level IRM objective with Model-Agnostic Meta-Learning (MAML) framework. Our method is more robust to the data with spurious correlations and can provide an invariant optimal classifier even when data from each distribution are scarce. In experiments, we demonstrate that our algorithm not only has better OOD generalization performance than IRMv1 and all IRM variants, but also addresses the weakness of IRMv1 with improved stability.
Distributed Memory based Self-Supervised Differentiable Neural Computer
Jul 21, 2020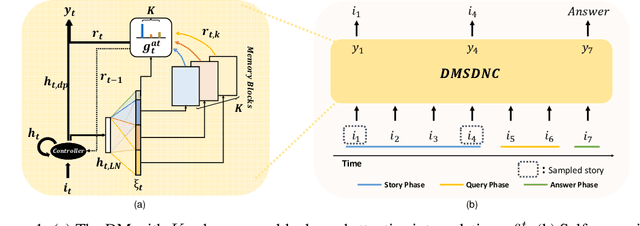

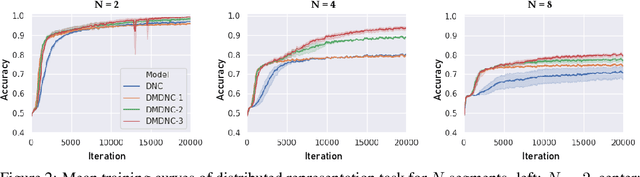

A differentiable neural computer (DNC) is a memory augmented neural network devised to solve a wide range of algorithmic and question answering tasks and it showed promising performance in a variety of domains. However, its single memory-based operations are not enough to store and retrieve diverse informative representations existing in many tasks. Furthermore, DNC does not explicitly consider the memorization itself as a target objective, which inevitably leads to a very slow learning speed of the model. To address those issues, we propose a novel distributed memory-based self-supervised DNC architecture for enhanced memory augmented neural network performance. We introduce (i) a multiple distributed memory block mechanism that stores information independently to each memory block and uses stored information in a cooperative way for diverse representation and (ii) a self-supervised memory loss term which ensures how well a given input is written to the memory. Our experiments on algorithmic and question answering tasks show that the proposed model outperforms all other variations of DNC in a large margin, and also matches the performance of other state-of-the-art memory-based network models.
Emotional Video to Audio Transformation Using Deep Recurrent Neural Networks and a Neuro-Fuzzy System
Apr 05, 2020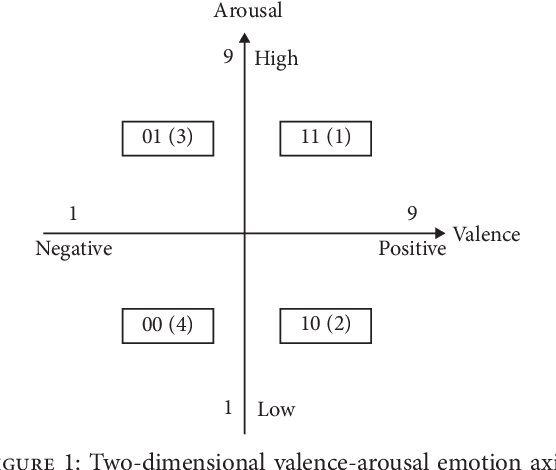

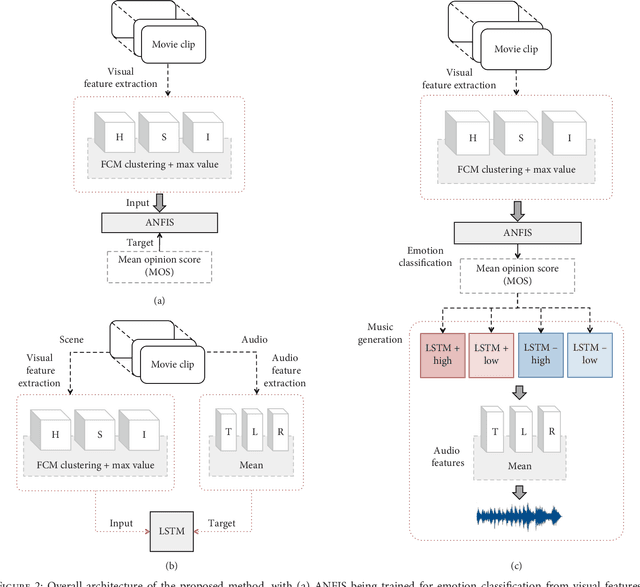
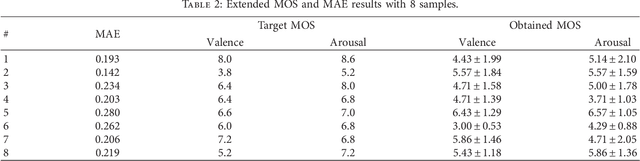
Generating music with emotion similar to that of an input video is a very relevant issue nowadays. Video content creators and automatic movie directors benefit from maintaining their viewers engaged, which can be facilitated by producing novel material eliciting stronger emotions in them. Moreover, there's currently a demand for more empathetic computers to aid humans in applications such as augmenting the perception ability of visually and/or hearing impaired people. Current approaches overlook the video's emotional characteristics in the music generation step, only consider static images instead of videos, are unable to generate novel music, and require a high level of human effort and skills. In this study, we propose a novel hybrid deep neural network that uses an Adaptive Neuro-Fuzzy Inference System to predict a video's emotion from its visual features and a deep Long Short-Term Memory Recurrent Neural Network to generate its corresponding audio signals with similar emotional inkling. The former is able to appropriately model emotions due to its fuzzy properties, and the latter is able to model data with dynamic time properties well due to the availability of the previous hidden state information. The novelty of our proposed method lies in the extraction of visual emotional features in order to transform them into audio signals with corresponding emotional aspects for users. Quantitative experiments show low mean absolute errors of 0.217 and 0.255 in the Lindsey and DEAP datasets respectively, and similar global features in the spectrograms. This indicates that our model is able to appropriately perform domain transformation between visual and audio features. Based on experimental results, our model can effectively generate audio that matches the scene eliciting a similar emotion from the viewer in both datasets, and music generated by our model is also chosen more often.
* Published (https://www.hindawi.com/journals/mpe/2020/8478527/)
Vocoder-free End-to-End Voice Conversion with Transformer Network
Feb 05, 2020
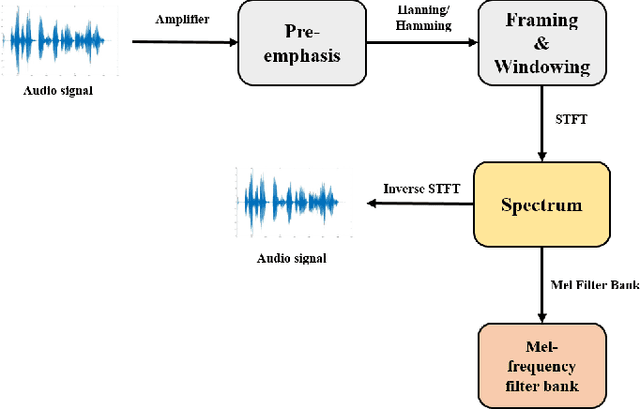
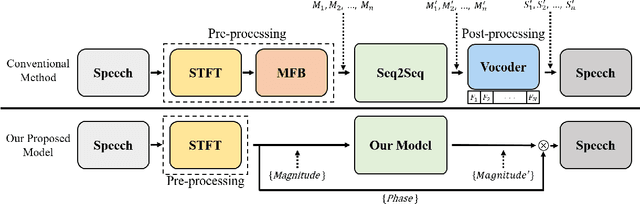
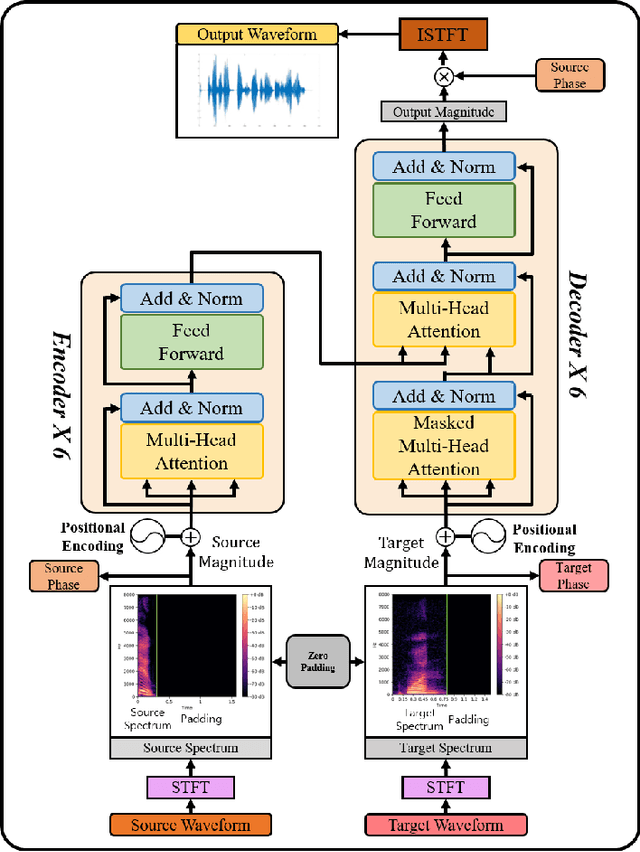
Mel-frequency filter bank (MFB) based approaches have the advantage of learning speech compared to raw spectrum since MFB has less feature size. However, speech generator with MFB approaches require additional vocoder that needs a huge amount of computation expense for training process. The additional pre/post processing such as MFB and vocoder is not essential to convert real human speech to others. It is possible to only use the raw spectrum along with the phase to generate different style of voices with clear pronunciation. In this regard, we propose a fast and effective approach to convert realistic voices using raw spectrum in a parallel manner. Our transformer-based model architecture which does not have any CNN or RNN layers has shown the advantage of learning fast and solved the limitation of sequential computation of conventional RNN. In this paper, we introduce a vocoder-free end-to-end voice conversion method using transformer network. The presented conversion model can also be used in speaker adaptation for speech recognition. Our approach can convert the source voice to a target voice without using MFB and vocoder. We can get an adapted MFB for speech recognition by multiplying the converted magnitude with phase. We perform our voice conversion experiments on TIDIGITS dataset using the metrics such as naturalness, similarity, and clarity with mean opinion score, respectively.