 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeExploring Overall Contextual Information for Image Captioning in Human-Like Cognitive Style
Oct 15, 2019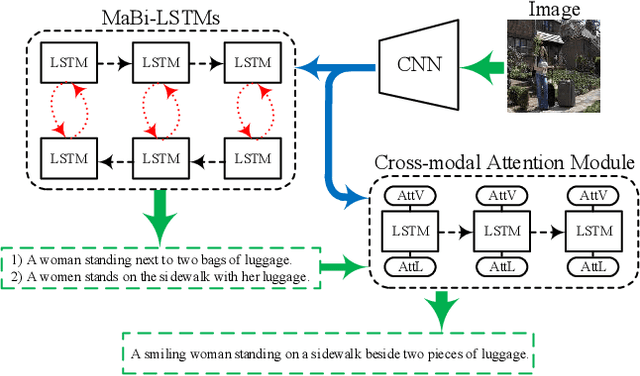
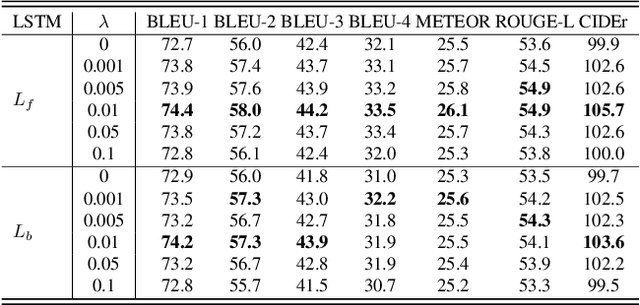
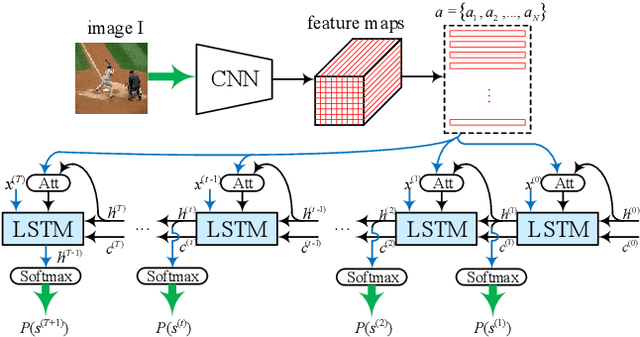
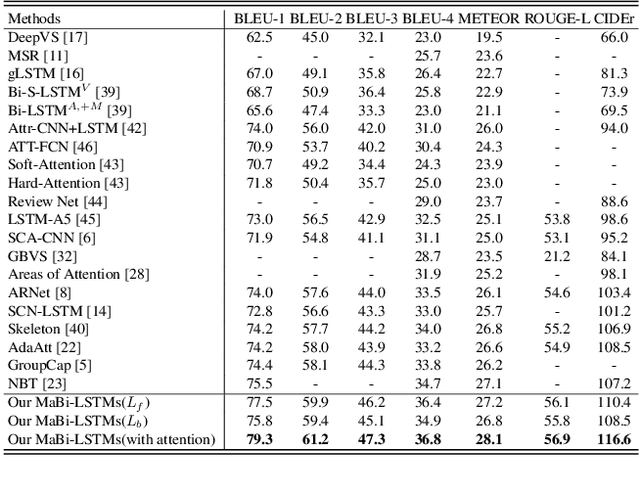
Image captioning is a research hotspot where encoder-decoder models combining convolutional neural network (CNN) and long short-term memory (LSTM) achieve promising results. Despite significant progress, these models generate sentences differently from human cognitive styles. Existing models often generate a complete sentence from the first word to the end, without considering the influence of the following words on the whole sentence generation. In this paper, we explore the utilization of a human-like cognitive style, i.e., building overall cognition for the image to be described and the sentence to be constructed, for enhancing computer image understanding. This paper first proposes a Mutual-aid network structure with Bidirectional LSTMs (MaBi-LSTMs) for acquiring overall contextual information. In the training process, the forward and backward LSTMs encode the succeeding and preceding words into their respective hidden states by simultaneously constructing the whole sentence in a complementary manner. In the captioning process, the LSTM implicitly utilizes the subsequent semantic information contained in its hidden states. In fact, MaBi-LSTMs can generate two sentences in forward and backward directions. To bridge the gap between cross-domain models and generate a sentence with higher quality, we further develop a cross-modal attention mechanism to retouch the two sentences by fusing their salient parts as well as the salient areas of the image. Experimental results on the Microsoft COCO dataset show that the proposed model improves the performance of encoder-decoder models and achieves state-of-the-art results.
Break the Ceiling: Stronger Multi-scale Deep Graph Convolutional Networks
Jun 21, 2019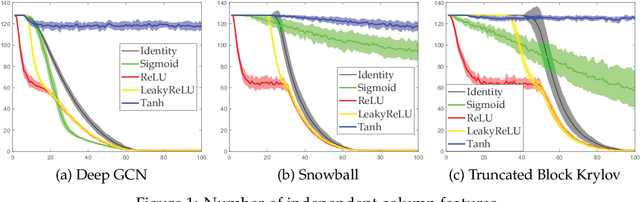
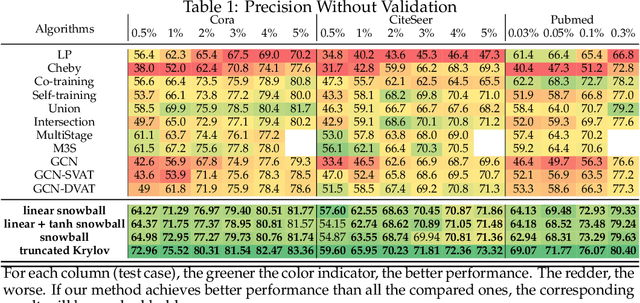
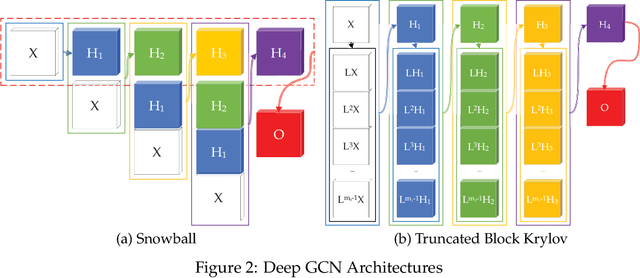
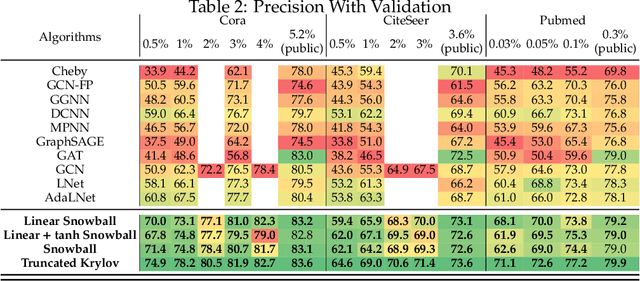
Recently, neural network based approaches have achieved significant improvement for solving large, complex, graph-structured problems. However, their bottlenecks ] still need to be addressed, and the advantages of multi-scale information and deep architectures have not been sufficiently exploited. In this paper, we theoretically analyze how existing Graph Convolutional Networks (GCNs) have limited expressive power due to the constraint of the activation functions and their architectures. We generalize spectral graph convolution and deep GCN in block Krylov subspace forms and devise two architectures, both with the potential to be scaled deeper but each making use of the multi-scale information in different ways. We further show that the equivalence of these two architectures can be established under certain conditions. On several node classification tasks, with or without the help of validation, the two new architectures achieve better performance compared to many state-of-the-art methods.
Faster and More Accurate Trace-based Policy Evaluation via Overall Target Error Meta-Optimization
May 25, 2019
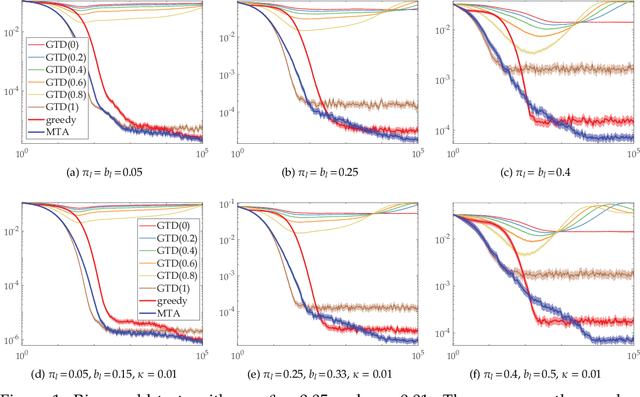
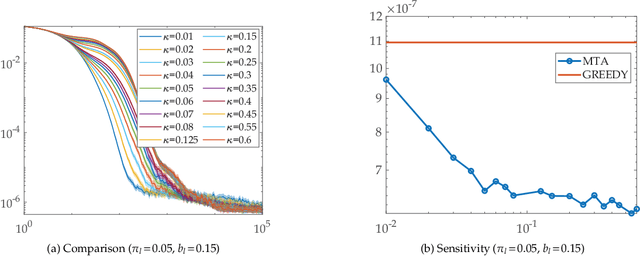
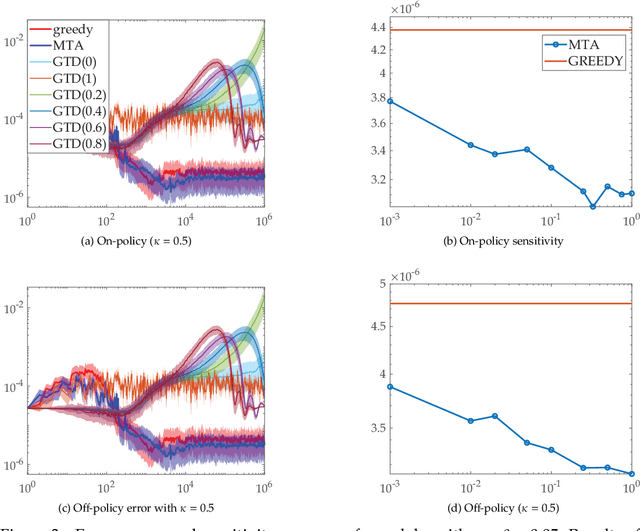
To improve the speed and accuracy of the trace based policy evaluation method TD({\lambda}), under appropriate assumptions, we derive and propose an off-policy compatible method of meta-learning state-based {\lambda}'s online with efficient incremental updates. Furthermore, we prove the derived bias-variance tradeoff minimization method, with slight adjustments, is equivalent to minimizing the overall target error in terms of state based {\lambda}'s. In experiments, the method shows significantly better performance when compared to the existing method and the baselines.
A Reference Vector based Many-Objective Evolutionary Algorithm with Feasibility-aware Adaptation
Apr 12, 2019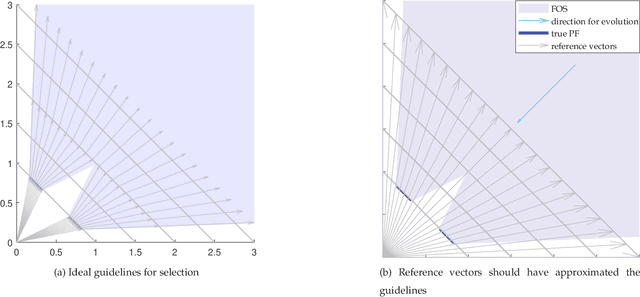
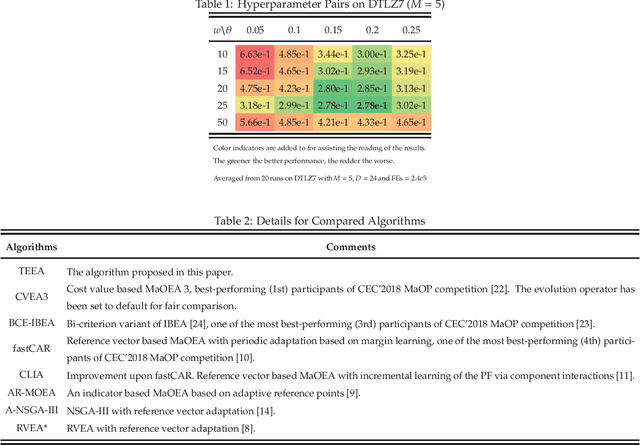
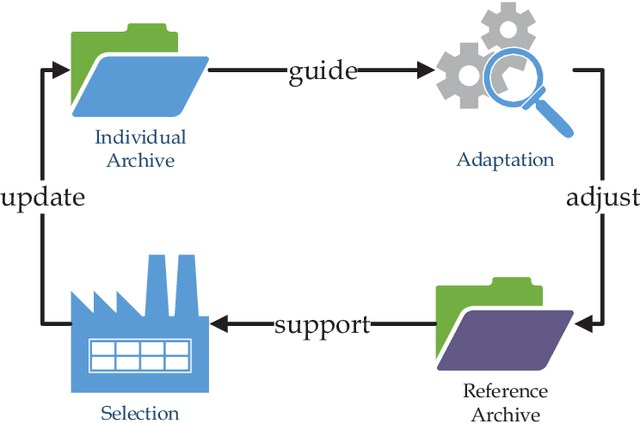
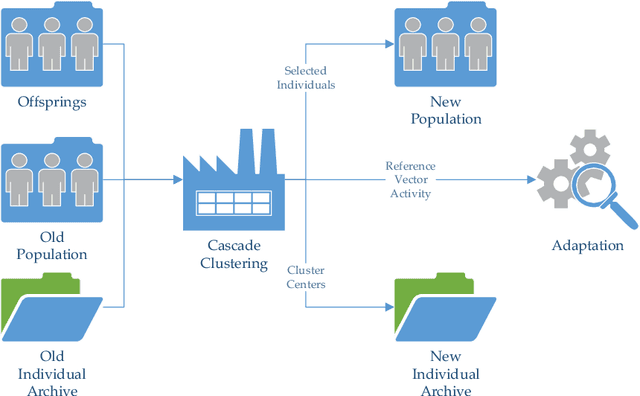
The infeasible parts of the objective space in difficult many-objective optimization problems cause trouble for evolutionary algorithms. This paper proposes a reference vector based algorithm which uses two interacting engines to adapt the reference vectors and to evolve the population towards the true Pareto Front (PF) s.t. the reference vectors are always evenly distributed within the current PF to provide appropriate guidance for selection. The current PF is tracked by maintaining an archive of undominated individuals, and adaptation of reference vectors is conducted with the help of another archive that contains layers of reference vectors corresponding to different density. Experimental results show the expected characteristics and competitive performance of the proposed algorithm TEEA.
Online Decisioning Meta-Heuristic Framework for Large Scale Black-Box Optimization
Dec 17, 2018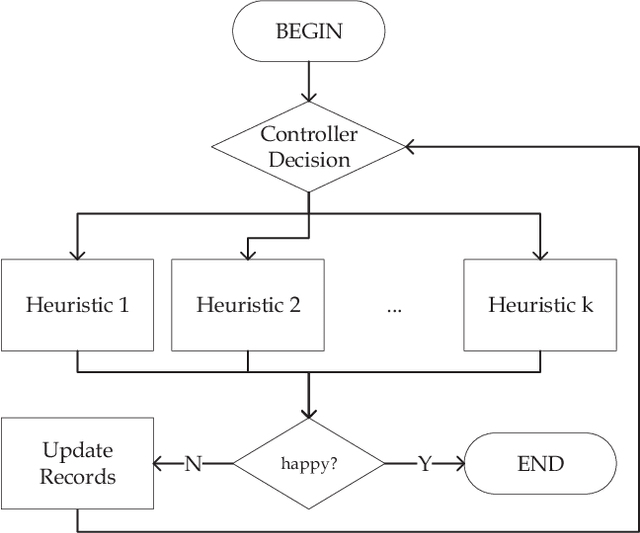
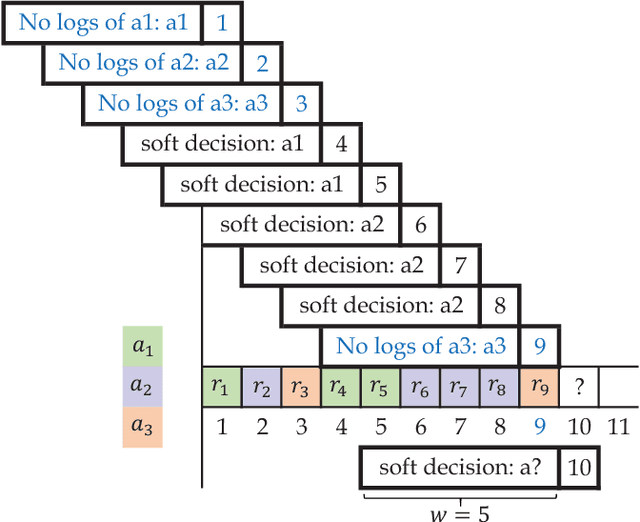
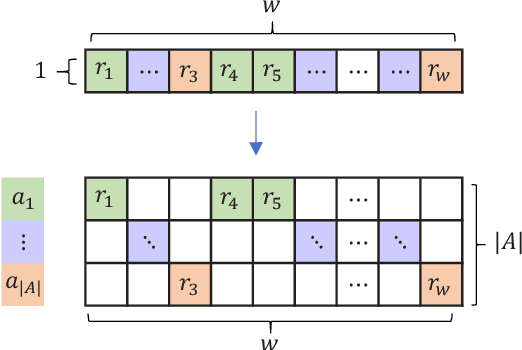
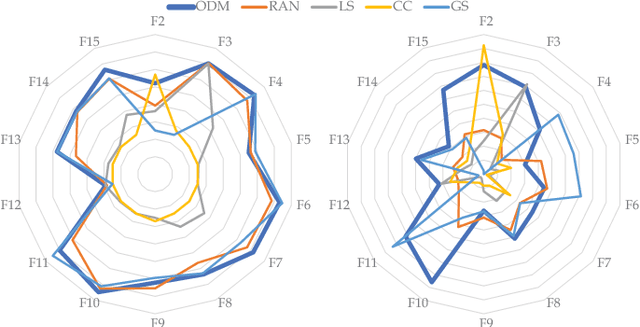
Out of practical concerns and with the expectation to achieve high overall efficiency of the resource utilization, this paper transforms the large scale black-box optimization problems with limited resources into online decision problems from the perspective of dynamic multi-armed bandits, a simplified view of Markov decision processes. The proposed Online Decisioning Meta-heuristic framework (ODM) is particularly well suited for real-world applications, with flexible compatibility for various kinds of costs, interfaces for easy heuristic articulation as well as fewer hyper-parameters for less variance in performance. Experimental results on benchmark functions suggest that ODM has demonstrated significant capabilities for online decisioning. Furthermore, when ODM is articulated with three heuristics, competitive performance can be achieved on benchmark problems with search dimensions up to 10000.
A Many-Objective Evolutionary Algorithm with Two Interacting Processes: Cascade Clustering and Reference Point Incremental Learning
Oct 04, 2018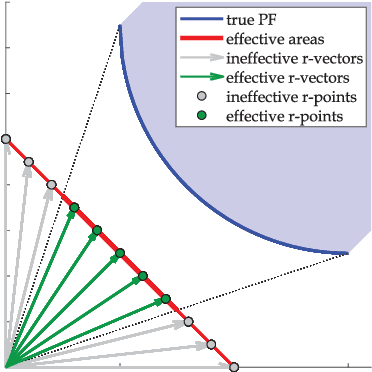
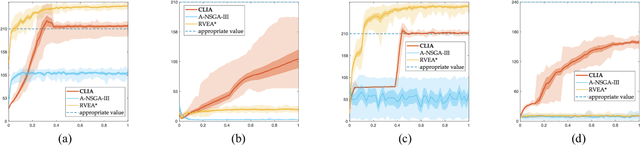
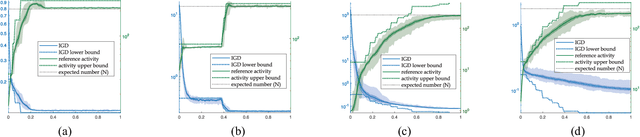
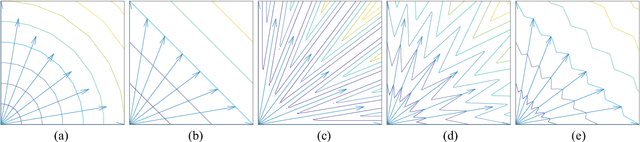
Researches have shown difficulties in obtaining proximity while maintaining diversity for solving many-objective optimization problems (MaOPs). The complexities of the true Pareto Front (PF) pose serious challenges for the reference vector based algorithms for their insufficient adaptability to the characteristics of the true PF with no priori. This paper proposes a many-objective optimization Algorithm with two Interacting processes: cascade Clustering and reference point incremental Learning (CLIA). In the population selection process based on cascade clustering, using the reference vectors provided by the incremental learning process, the non-dominated and the dominated individuals are clustered and sorted with different manners in a cascade style and are selected by round-robin for better proximity and diversity. In the reference vector adaptation process based on reference point incremental learning, using the feedbacks from the clustering process, the proper distribution of reference points is gradually obtained by incremental learning and the reference vectors are accordingly repositioned. The advantages of CLIA lie not only in its effective and efficient performance, but also in the versatility to deal with diverse characteristics of the true PF, only using the interactions between the two processes without incurring extra evaluations. The experimental studies on many benchmark problems show that CLIA is competitive, efficient and versatile compared with the state-of-the-art algorithms.
* 15 pages