 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeLearning to Discover Knowledge: A Weakly-Supervised Partial Domain Adaptation Approach
Jun 20, 2024



Domain adaptation has shown appealing performance by leveraging knowledge from a source domain with rich annotations. However, for a specific target task, it is cumbersome to collect related and high-quality source domains. In real-world scenarios, large-scale datasets corrupted with noisy labels are easy to collect, stimulating a great demand for automatic recognition in a generalized setting, i.e., weakly-supervised partial domain adaptation (WS-PDA), which transfers a classifier from a large source domain with noises in labels to a small unlabeled target domain. As such, the key issues of WS-PDA are: 1) how to sufficiently discover the knowledge from the noisy labeled source domain and the unlabeled target domain, and 2) how to successfully adapt the knowledge across domains. In this paper, we propose a simple yet effective domain adaptation approach, termed as self-paced transfer classifier learning (SP-TCL), to address the above issues, which could be regarded as a well-performing baseline for several generalized domain adaptation tasks. The proposed model is established upon the self-paced learning scheme, seeking a preferable classifier for the target domain. Specifically, SP-TCL learns to discover faithful knowledge via a carefully designed prudent loss function and simultaneously adapts the learned knowledge to the target domain by iteratively excluding source examples from training under the self-paced fashion. Extensive evaluations on several benchmark datasets demonstrate that SP-TCL significantly outperforms state-of-the-art approaches on several generalized domain adaptation tasks.
Large receptive field strategy and important feature extraction strategy in 3D object detection
Jan 22, 2024The enhancement of 3D object detection is pivotal for precise environmental perception and improved task execution capabilities in autonomous driving. LiDAR point clouds, offering accurate depth information, serve as a crucial information for this purpose. Our study focuses on key challenges in 3D target detection. To tackle the challenge of expanding the receptive field of a 3D convolutional kernel, we introduce the Dynamic Feature Fusion Module (DFFM). This module achieves adaptive expansion of the 3D convolutional kernel's receptive field, balancing the expansion with acceptable computational loads. This innovation reduces operations, expands the receptive field, and allows the model to dynamically adjust to different object requirements. Simultaneously, we identify redundant information in 3D features. Employing the Feature Selection Module (FSM) quantitatively evaluates and eliminates non-important features, achieving the separation of output box fitting and feature extraction. This innovation enables the detector to focus on critical features, resulting in model compression, reduced computational burden, and minimized candidate frame interference. Extensive experiments confirm that both DFFM and FSM not only enhance current benchmarks, particularly in small target detection, but also accelerate network performance. Importantly, these modules exhibit effective complementarity.
A Generalized Multi-Modal Fusion Detection Framework
Mar 13, 2023LiDAR point clouds have become the most common data source in autonomous driving. However, due to the sparsity of point clouds, accurate and reliable detection cannot be achieved in specific scenarios. Because of their complementarity with point clouds, images are getting increasing attention. Although with some success, existing fusion methods either perform hard fusion or do not fuse in a direct manner. In this paper, we propose a generic 3D detection framework called MMFusion, using multi-modal features. The framework aims to achieve accurate fusion between LiDAR and images to improve 3D detection in complex scenes. Our framework consists of two separate streams: the LiDAR stream and the camera stream, which can be compatible with any single-modal feature extraction network. The Voxel Local Perception Module in the LiDAR stream enhances local feature representation, and then the Multi-modal Feature Fusion Module selectively combines feature output from different streams to achieve better fusion. Extensive experiments have shown that our framework not only outperforms existing benchmarks but also improves their detection, especially for detecting cyclists and pedestrians on KITTI benchmarks, with strong robustness and generalization capabilities. Hopefully, our work will stimulate more research into multi-modal fusion for autonomous driving tasks.
A Survey of Decision Making in Adversarial Games
Jul 16, 2022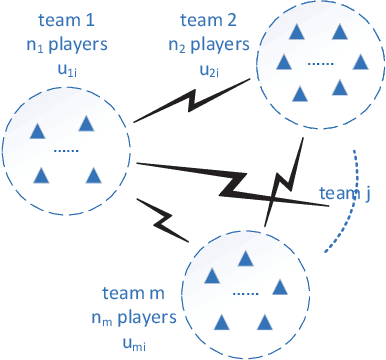
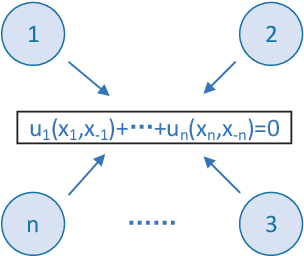
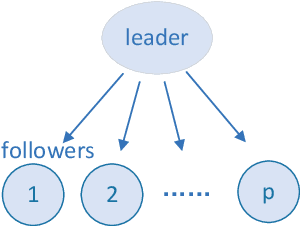
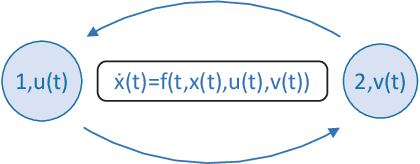
Game theory has by now found numerous applications in various fields, including economics, industry, jurisprudence, and artificial intelligence, where each player only cares about its own interest in a noncooperative or cooperative manner, but without obvious malice to other players. However, in many practical applications, such as poker, chess, evader pursuing, drug interdiction, coast guard, cyber-security, and national defense, players often have apparently adversarial stances, that is, selfish actions of each player inevitably or intentionally inflict loss or wreak havoc on other players. Along this line, this paper provides a systematic survey on three main game models widely employed in adversarial games, i.e., zero-sum normal-form and extensive-form games, Stackelberg (security) games, zero-sum differential games, from an array of perspectives, including basic knowledge of game models, (approximate) equilibrium concepts, problem classifications, research frontiers, (approximate) optimal strategy seeking techniques, prevailing algorithms, and practical applications. Finally, promising future research directions are also discussed for relevant adversarial games.
Composition and Application of Current Advanced Driving Assistance System: A Review
Jun 10, 2021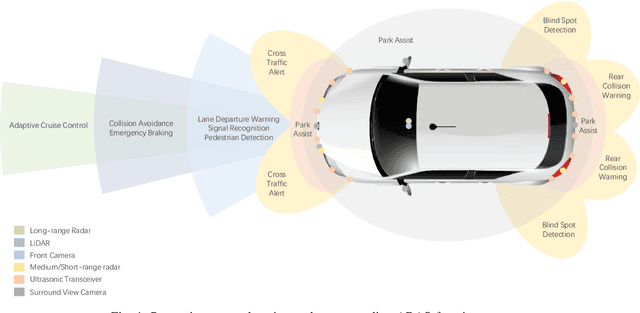
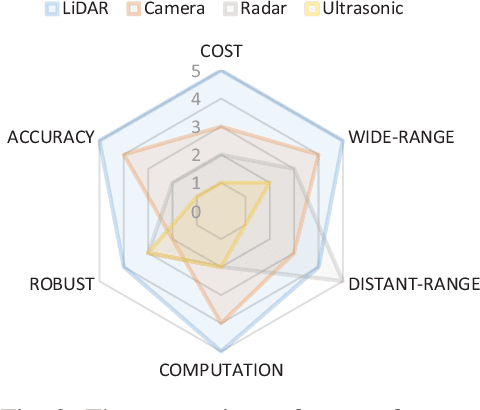
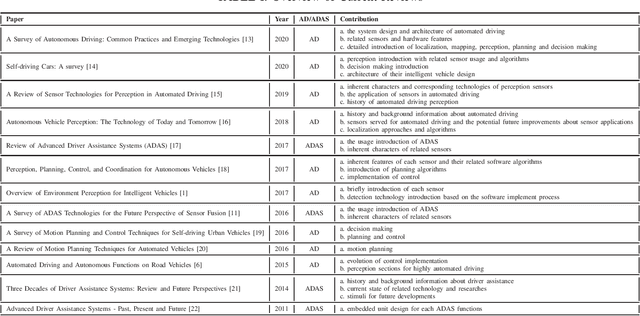

Due to the growing awareness of driving safety and the development of sophisticated technologies, advanced driving assistance system (ADAS) has been equipped in more and more vehicles with higher accuracy and lower price. The latest progress in this field has called for a review to sum up the conventional knowledge of ADAS, the state-of-the-art researches, and novel applications in real-world. With the help of this kind of review, newcomers in this field can get basic knowledge easier and other researchers may be inspired with potential future development possibility. This paper makes a general introduction about ADAS by analyzing its hardware support and computation algorithms. Different types of perception sensors are introduced from their interior feature classifications, installation positions, supporting ADAS functions, and pros and cons. The comparisons between different sensors are concluded and illustrated from their inherent characters and specific usages serving for each ADAS function. The current algorithms for ADAS functions are also collected and briefly presented in this paper from both traditional methods and novel ideas. Additionally, discussions about the definition of ADAS from different institutes are reviewed in this paper, and future approaches about ADAS in China are introduced in particular.