 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeAdvancing Mathematics Research with AI-Driven Formal Proof Search
May 21, 2026Large language models (LLMs) increasingly excel at mathematical reasoning, but their unreliability limits their utility in mathematics research. A mitigation is using LLMs to generate formal proofs in languages like Lean. We perform the first large-scale evaluation of this method's ability to solve open problems. Our most capable agent autonomously resolved 9 of 353 open Erdős problems at the per-problem cost of a few hundred dollars, proved 44/492 OEIS conjectures, and is being deployed in combinatorics, optimization, graph theory, algebraic geometry, and quantum optics research. A basic agent alternating LLM-based generation with Lean-based verification replicated the Erdős successes but proved costlier on the hardest problems. These findings demonstrate the power of AI-aided formal proof search and shed light on the agent designs that enable it.
Formal Conjectures: An Open and Evolving Benchmark for Verified Discovery in Mathematics
May 13, 2026As automated reasoning systems advance rapidly, there is a growing need for research-level formal mathematical problems to accurately evaluate their capabilities. To address this, we present Formal Conjectures, an evolving benchmark of currently 2615 mathematical problem statements formalized in Lean 4. Sourced from areas of active mathematical research, the dataset features 1029 open research conjectures providing a zero-contamination benchmark for mathematical proof discovery, and 836 solved problems for proof autoformalization. Notably, the repository provides a structured interface connecting mathematicians who formalize and clarify problems with the AI systems and humans attempting to solve them. Demonstrating its immediate utility, the benchmark has already been leveraged to make new mathematical discoveries, including the resolution of open research conjectures. We describe our approach to ensuring the correctness of these formalizations in a collaborative open-source project where contributions stem from an active community. In this framework, AI-generated proofs and disproofs serve as a valuable auditing mechanism to iteratively improve the fidelity of the benchmark. Finally, we provide a standardized evaluation setup and report baseline results on frozen evaluation subsets, demonstrating a climbable signal that measures the current frontier of automated reasoning on research-level mathematics.
(De-)Randomized Smoothing for Decision Stump Ensembles
May 27, 2022



Tree-based models are used in many high-stakes application domains such as finance and medicine, where robustness and interpretability are of utmost importance. Yet, methods for improving and certifying their robustness are severely under-explored, in contrast to those focusing on neural networks. Targeting this important challenge, we propose deterministic smoothing for decision stump ensembles. Whereas most prior work on randomized smoothing focuses on evaluating arbitrary base models approximately under input randomization, the key insight of our work is that decision stump ensembles enable exact yet efficient evaluation via dynamic programming. Importantly, we obtain deterministic robustness certificates, even jointly over numerical and categorical features, a setting ubiquitous in the real world. Further, we derive an MLE-optimal training method for smoothed decision stumps under randomization and propose two boosting approaches to improve their provable robustness. An extensive experimental evaluation shows that our approach yields significantly higher certified accuracies than the state-of-the-art for tree-based models. We release all code and trained models at ANONYMIZED.
Robust and Accurate -- Compositional Architectures for Randomized Smoothing
Apr 01, 2022



Randomized Smoothing (RS) is considered the state-of-the-art approach to obtain certifiably robust models for challenging tasks. However, current RS approaches drastically decrease standard accuracy on unperturbed data, severely limiting their real-world utility. To address this limitation, we propose a compositional architecture, ACES, which certifiably decides on a per-sample basis whether to use a smoothed model yielding predictions with guarantees or a more accurate standard model without guarantees. This, in contrast to prior approaches, enables both high standard accuracies and significant provable robustness. On challenging tasks such as ImageNet, we obtain, e.g., $80.0\%$ natural accuracy and $28.2\%$ certifiable accuracy against $\ell_2$ perturbations with $r=1.0$. We release our code and models at https://github.com/eth-sri/aces.
Boosting Randomized Smoothing with Variance Reduced Classifiers
Jun 13, 2021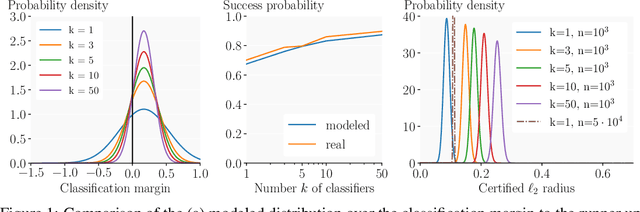
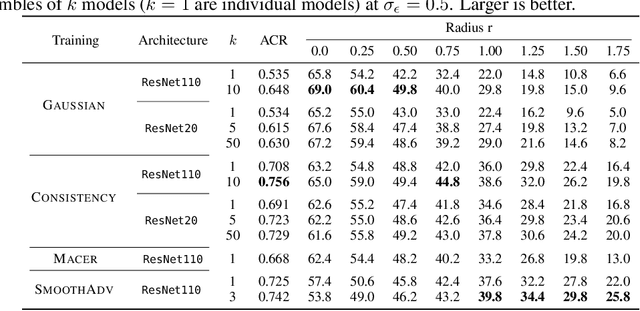
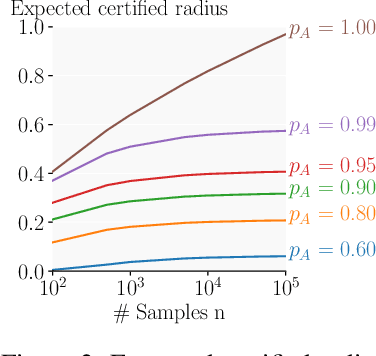
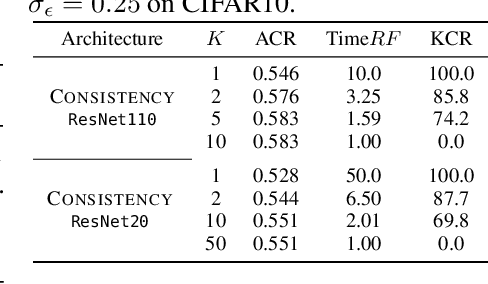
Randomized Smoothing (RS) is a promising method for obtaining robustness certificates by evaluating a base model under noise. In this work we: (i) theoretically motivate why ensembles are a particularly suitable choice as base models for RS, and (ii) empirically confirm this choice, obtaining state of the art results in multiple settings. The key insight of our work is that the reduced variance of ensembles over the perturbations introduced in RS leads to significantly more consistent classifications for a given input, in turn leading to substantially increased certifiable radii for difficult samples. We also introduce key optimizations which enable an up to 50-fold decrease in sample complexity of RS, thus drastically reducing its computational overhead. Experimentally, we show that ensembles of only 3 to 10 classifiers consistently improve on the strongest single model with respect to their average certified radius (ACR) by 5% to 21% on both CIFAR-10 and ImageNet. On the latter, we achieve a state-of-the-art ACR of 1.11. We release all code and models required to reproduce our results upon publication.