 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeUnderstanding new tasks through the lens of training data via exponential tilting
May 26, 2022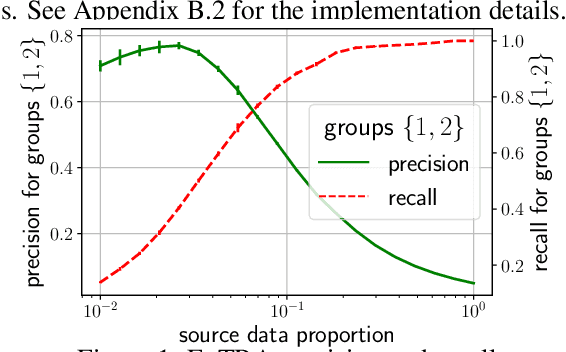
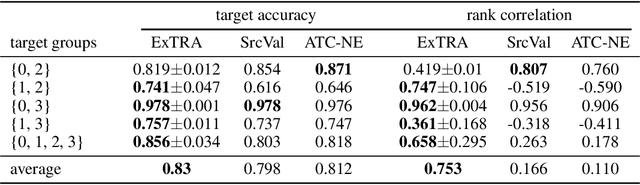
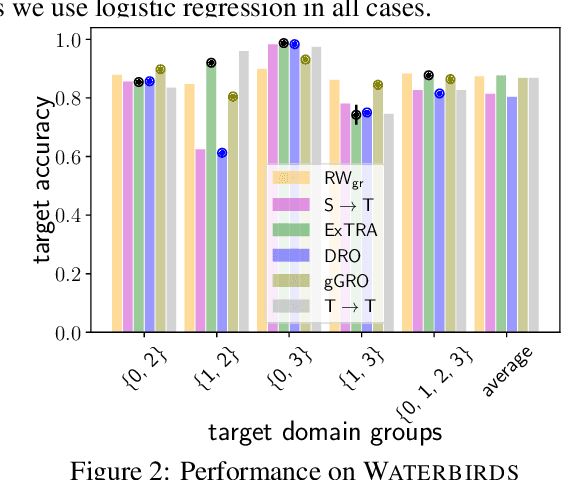
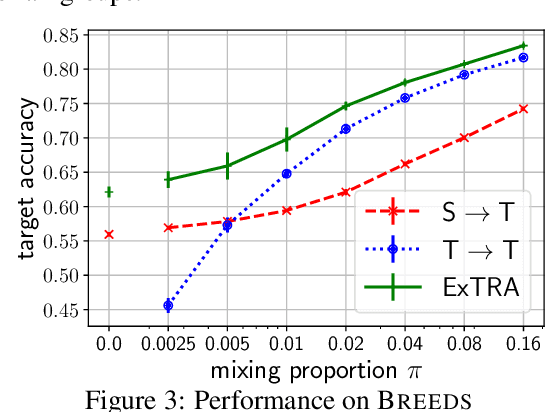
Deploying machine learning models to new tasks is a major challenge despite the large size of the modern training datasets. However, it is conceivable that the training data can be reweighted to be more representative of the new (target) task. We consider the problem of reweighing the training samples to gain insights into the distribution of the target task. Specifically, we formulate a distribution shift model based on the exponential tilt assumption and learn train data importance weights minimizing the KL divergence between labeled train and unlabeled target datasets. The learned train data weights can then be used for downstream tasks such as target performance evaluation, fine-tuning, and model selection. We demonstrate the efficacy of our method on Waterbirds and Breeds benchmarks.
Domain Adaptation meets Individual Fairness. And they get along
May 01, 2022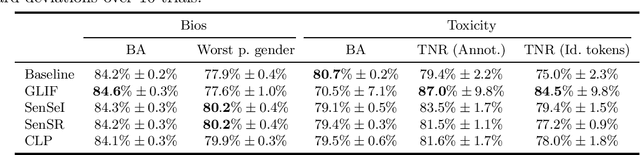
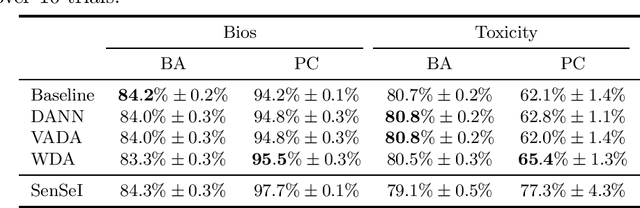
Many instances of algorithmic bias are caused by distributional shifts. For example, machine learning (ML) models often perform worse on demographic groups that are underrepresented in the training data. In this paper, we leverage this connection between algorithmic fairness and distribution shifts to show that algorithmic fairness interventions can help ML models overcome distribution shifts, and that domain adaptation methods (for overcoming distribution shifts) can mitigate algorithmic biases. In particular, we show that (i) enforcing suitable notions of individual fairness (IF) can improve the out-of-distribution accuracy of ML models, and that (ii) it is possible to adapt representation alignment methods for domain adaptation to enforce (individual) fairness. The former is unexpected because IF interventions were not developed with distribution shifts in mind. The latter is also unexpected because representation alignment is not a common approach in the IF literature.
Log-Euclidean Signatures for Intrinsic Distances Between Unaligned Datasets
Feb 03, 2022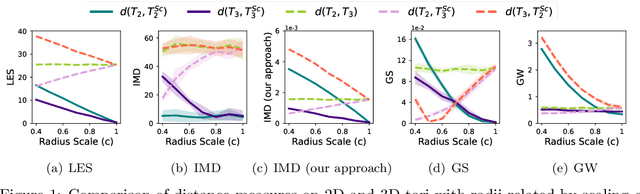

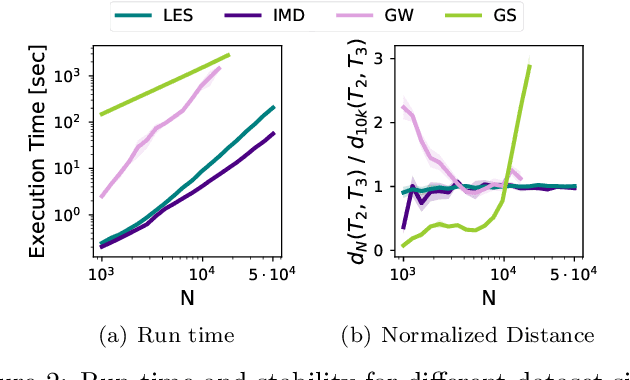

The need for efficiently comparing and representing datasets with unknown alignment spans various fields, from model analysis and comparison in machine learning to trend discovery in collections of medical datasets. We use manifold learning to compare the intrinsic geometric structures of different datasets by comparing their diffusion operators, symmetric positive-definite (SPD) matrices that relate to approximations of the continuous Laplace-Beltrami operator from discrete samples. Existing methods typically compare such operators in a pointwise manner or assume known data alignment. Instead, we exploit the Riemannian geometry of SPD matrices to compare these operators and define a new theoretically-motivated distance based on a lower bound of the log-Euclidean metric. Our framework facilitates comparison of data manifolds expressed in datasets with different sizes, numbers of features, and measurement modalities. Our log-Euclidean signature (LES) distance recovers meaningful structural differences, outperforming competing methods in various application domains.
Rewiring with Positional Encodings for Graph Neural Networks
Feb 02, 2022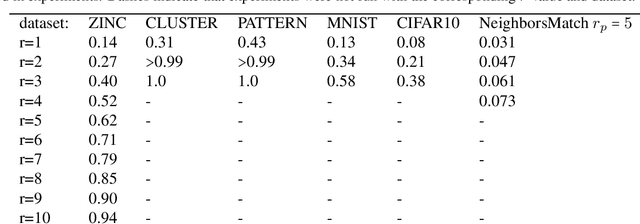
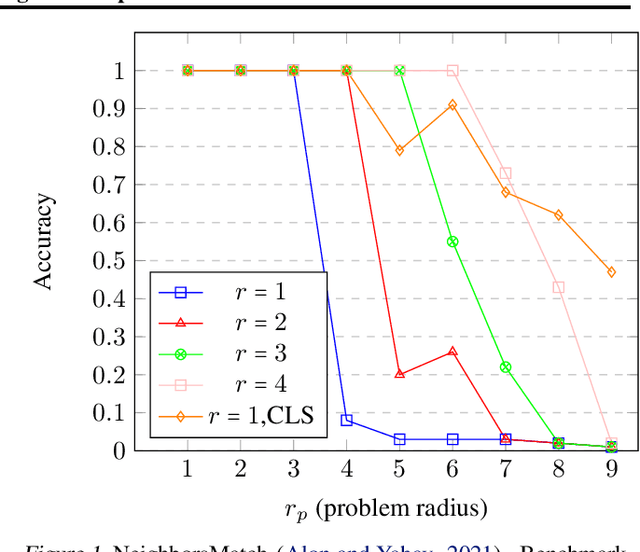
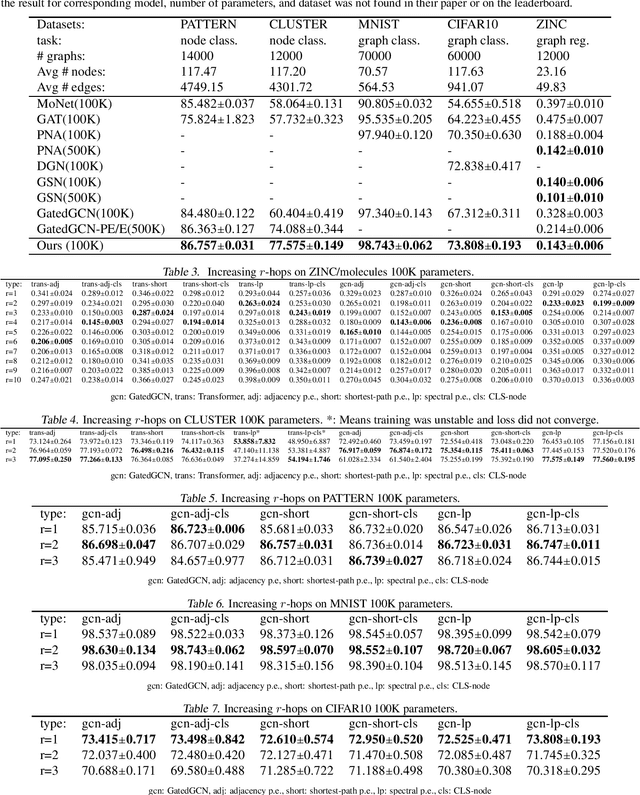
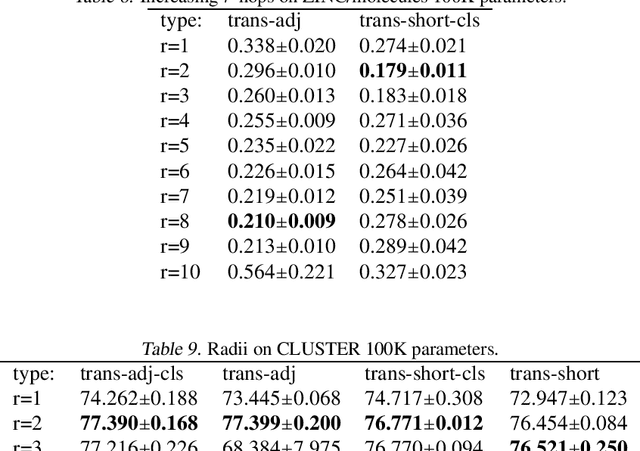
Several recent works use positional encodings to extend the receptive fields of graph neural network (GNN) layers equipped with attention mechanisms. These techniques, however, extend receptive fields to the complete graph, at substantial computational cost and risking a change in the inductive biases of conventional GNNs, or require complex architecture adjustments. As a conservative alternative, we use positional encodings to expand receptive fields to any r-ring. Our method augments the input graph with additional nodes/edges and uses positional encodings as node and/or edge features. Thus, it is compatible with many existing GNN architectures. We also provide examples of positional encodings that are non-invasive, i.e., there is a one-to-one map between the original and the modified graphs. Our experiments demonstrate that extending receptive fields via positional encodings and a virtual fully-connected node significantly improves GNN performance and alleviates over-squashing using small r. We obtain improvements across models, showing state-of-the-art performance even using older architectures than recent Transformer models adapted to graphs.
Learning Proximal Operators to Discover Multiple Optima
Jan 28, 2022
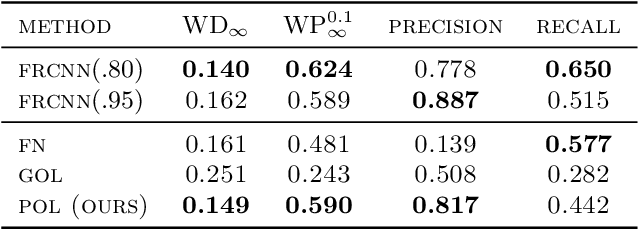

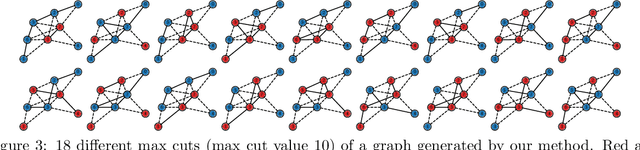
Finding multiple solutions of non-convex optimization problems is a ubiquitous yet challenging task. Typical existing solutions either apply single-solution optimization methods from multiple random initial guesses or search in the vicinity of found solutions using ad hoc heuristics. We present an end-to-end method to learn the proximal operator across a family of non-convex problems, which can then be used to recover multiple solutions for unseen problems at test time. Our method only requires access to the objectives without needing the supervision of ground truth solutions. Notably, the added proximal regularization term elevates the convexity of our formulation: by applying recent theoretical results, we show that for weakly-convex objectives and under mild regularity conditions, training of the proximal operator converges globally in the over-parameterized setting. We further present a benchmark for multi-solution optimization including a wide range of applications and evaluate our method to demonstrate its effectiveness.
On sensitivity of meta-learning to support data
Oct 26, 2021
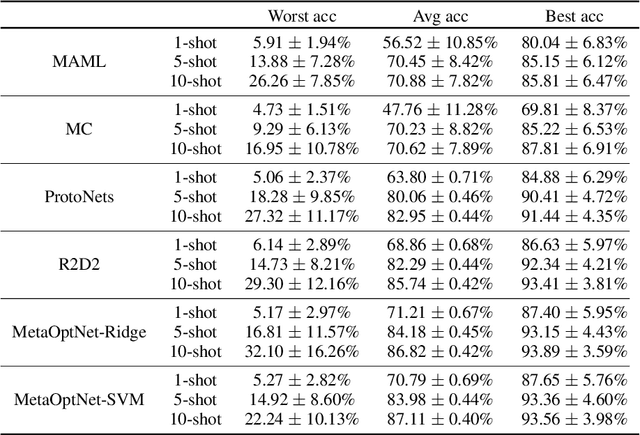

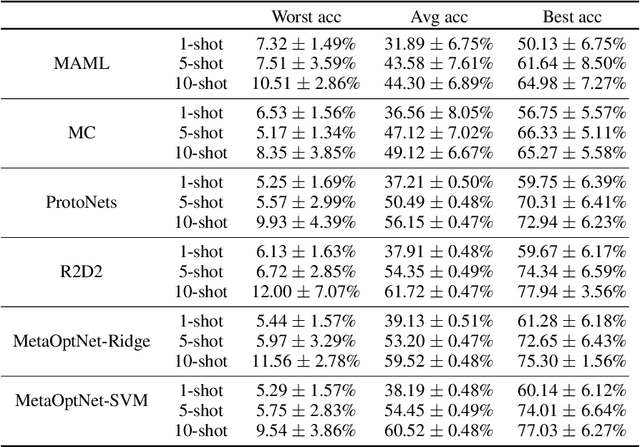
Meta-learning algorithms are widely used for few-shot learning. For example, image recognition systems that readily adapt to unseen classes after seeing only a few labeled examples. Despite their success, we show that modern meta-learning algorithms are extremely sensitive to the data used for adaptation, i.e. support data. In particular, we demonstrate the existence of (unaltered, in-distribution, natural) images that, when used for adaptation, yield accuracy as low as 4\% or as high as 95\% on standard few-shot image classification benchmarks. We explain our empirical findings in terms of class margins, which in turn suggests that robust and safe meta-learning requires larger margins than supervised learning.
Post-processing for Individual Fairness
Oct 26, 2021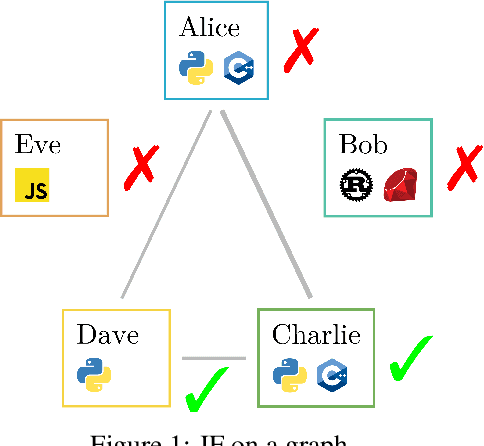
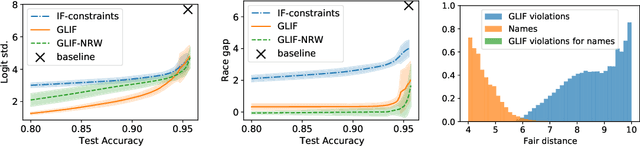

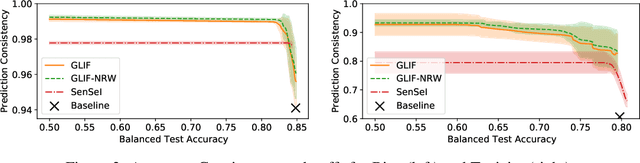
Post-processing in algorithmic fairness is a versatile approach for correcting bias in ML systems that are already used in production. The main appeal of post-processing is that it avoids expensive retraining. In this work, we propose general post-processing algorithms for individual fairness (IF). We consider a setting where the learner only has access to the predictions of the original model and a similarity graph between individuals, guiding the desired fairness constraints. We cast the IF post-processing problem as a graph smoothing problem corresponding to graph Laplacian regularization that preserves the desired "treat similar individuals similarly" interpretation. Our theoretical results demonstrate the connection of the new objective function to a local relaxation of the original individual fairness. Empirically, our post-processing algorithms correct individual biases in large-scale NLP models such as BERT, while preserving accuracy.
Your fairness may vary: Group fairness of pretrained language models in toxic text classification
Aug 03, 2021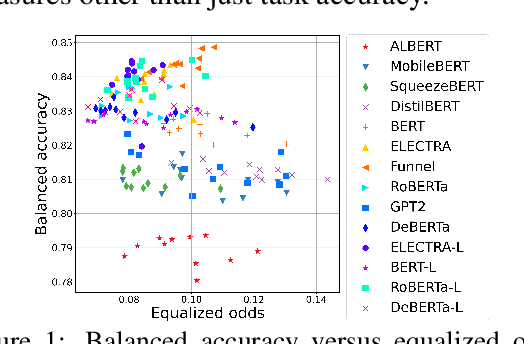
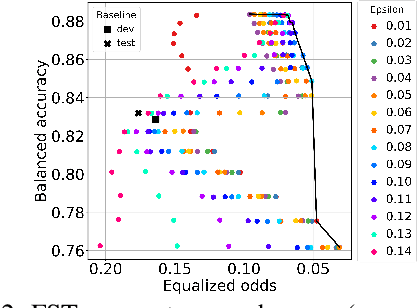
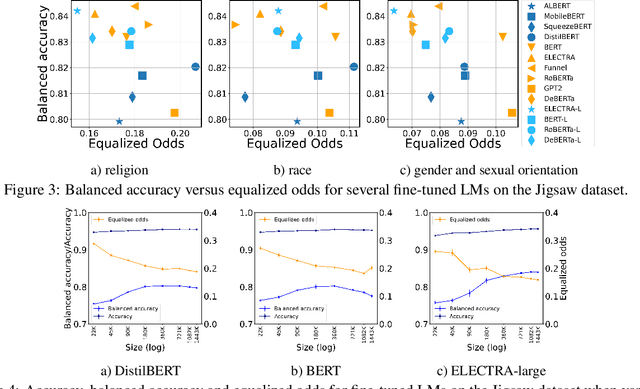
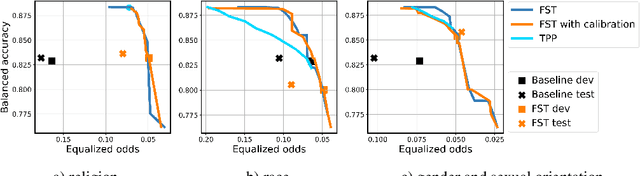
We study the performance-fairness trade-off in more than a dozen fine-tuned LMs for toxic text classification. We empirically show that no blanket statement can be made with respect to the bias of large versus regular versus compressed models. Moreover, we find that focusing on fairness-agnostic performance metrics can lead to models with varied fairness characteristics.
Measuring the sensitivity of Gaussian processes to kernel choice
Jun 11, 2021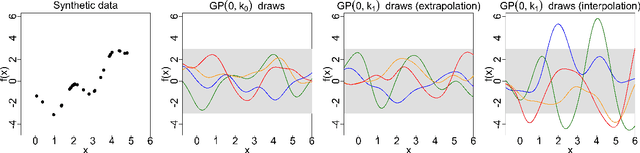
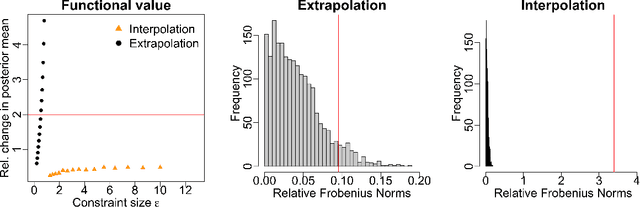
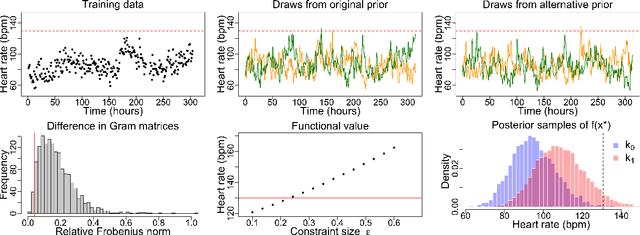
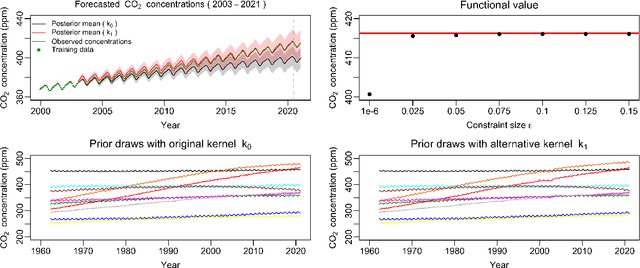
Gaussian processes (GPs) are used to make medical and scientific decisions, including in cardiac care and monitoring of carbon dioxide emissions. But the choice of GP kernel is often somewhat arbitrary. In particular, uncountably many kernels typically align with qualitative prior knowledge (e.g. function smoothness or stationarity). But in practice, data analysts choose among a handful of convenient standard kernels (e.g. squared exponential). In the present work, we ask: Would decisions made with a GP differ under other, qualitatively interchangeable kernels? We show how to formulate this sensitivity analysis as a constrained optimization problem over a finite-dimensional space. We can then use standard optimizers to identify substantive changes in relevant decisions made with a GP. We demonstrate in both synthetic and real-world examples that decisions made with a GP can exhibit substantial sensitivity to kernel choice, even when prior draws are qualitatively interchangeable to a user.
k-Mixup Regularization for Deep Learning via Optimal Transport
Jun 05, 2021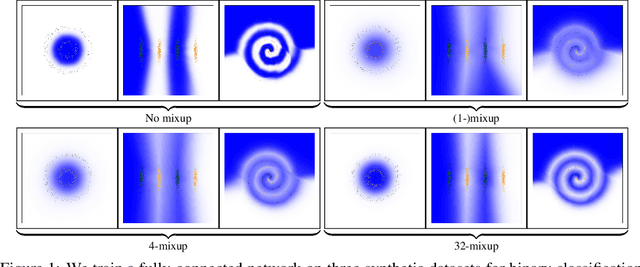
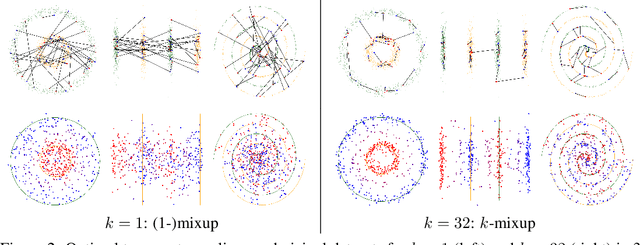

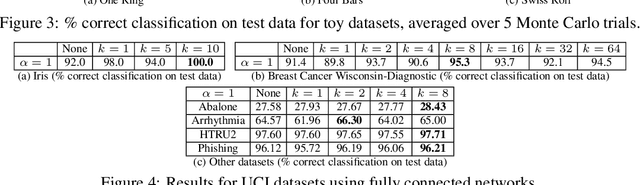
Mixup is a popular regularization technique for training deep neural networks that can improve generalization and increase adversarial robustness. It perturbs input training data in the direction of other randomly-chosen instances in the training set. To better leverage the structure of the data, we extend mixup to \emph{$k$-mixup} by perturbing $k$-batches of training points in the direction of other $k$-batches using displacement interpolation, interpolation under the Wasserstein metric. We demonstrate theoretically and in simulations that $k$-mixup preserves cluster and manifold structures, and we extend theory studying efficacy of standard mixup. Our empirical results show that training with $k$-mixup further improves generalization and robustness on benchmark datasets.