 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeRethinking the Role of Demonstrations: What Makes In-Context Learning Work?
Feb 25, 2022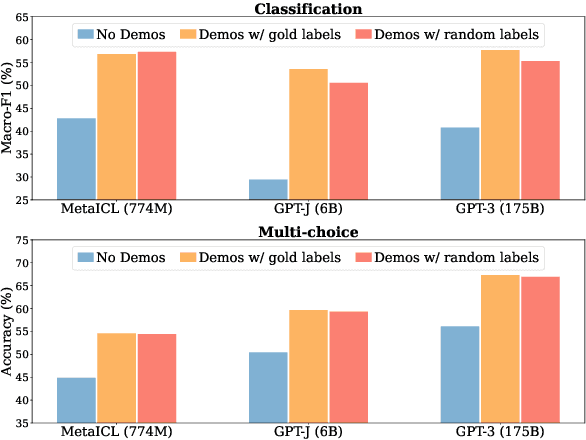

Large language models (LMs) are able to in-context learn -- perform a new task via inference alone by conditioning on a few input-label pairs (demonstrations) and making predictions for new inputs. However, there has been little understanding of how the model learns and which aspects of the demonstrations contribute to end task performance. In this paper, we show that ground truth demonstrations are in fact not required -- randomly replacing labels in the demonstrations barely hurts performance, consistently over 12 different models including GPT-3. Instead, we find that other aspects of the demonstrations are the key drivers of end task performance, including the fact that they provide a few examples of (1) the label space, (2) the distribution of the input text, and (3) the overall format of the sequence. Together, our analysis provides a new way of understanding how and why in-context learning works, while opening up new questions about how much can be learned from large language models through inference alone.
CM3: A Causal Masked Multimodal Model of the Internet
Jan 19, 2022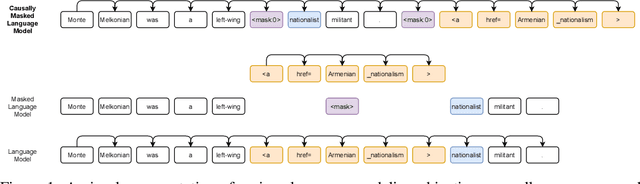
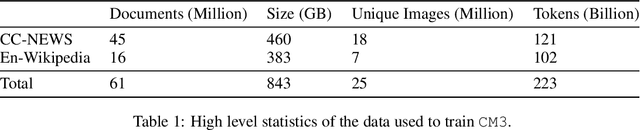
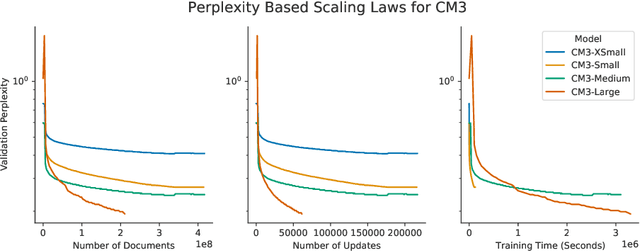
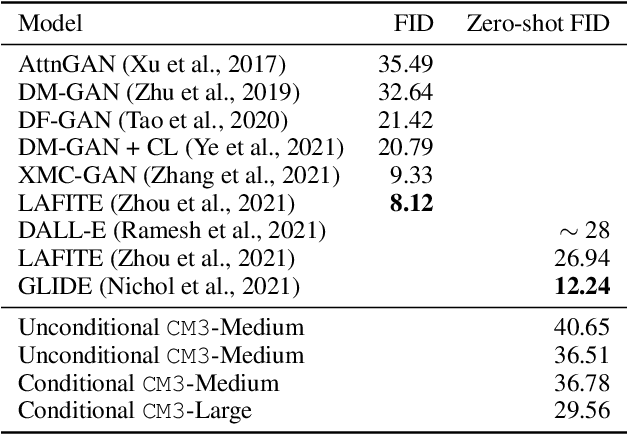
We introduce CM3, a family of causally masked generative models trained over a large corpus of structured multi-modal documents that can contain both text and image tokens. Our new causally masked approach generates tokens left to right while also masking out a small number of long token spans that are generated at the end of the string, instead of their original positions. The casual masking object provides a type of hybrid of the more common causal and masked language models, by enabling full generative modeling while also providing bidirectional context when generating the masked spans. We train causally masked language-image models on large-scale web and Wikipedia articles, where each document contains all of the text, hypertext markup, hyperlinks, and image tokens (from a VQVAE-GAN), provided in the order they appear in the original HTML source (before masking). The resulting CM3 models can generate rich structured, multi-modal outputs while conditioning on arbitrary masked document contexts, and thereby implicitly learn a wide range of text, image, and cross modal tasks. They can be prompted to recover, in a zero-shot fashion, the functionality of models such as DALL-E, GENRE, and HTLM. We set the new state-of-the-art in zero-shot summarization, entity linking, and entity disambiguation while maintaining competitive performance in the fine-tuning setting. We can generate images unconditionally, conditioned on text (like DALL-E) and do captioning all in a zero-shot setting with a single model.
MetaICL: Learning to Learn In Context
Oct 29, 2021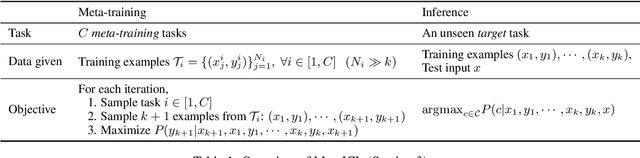
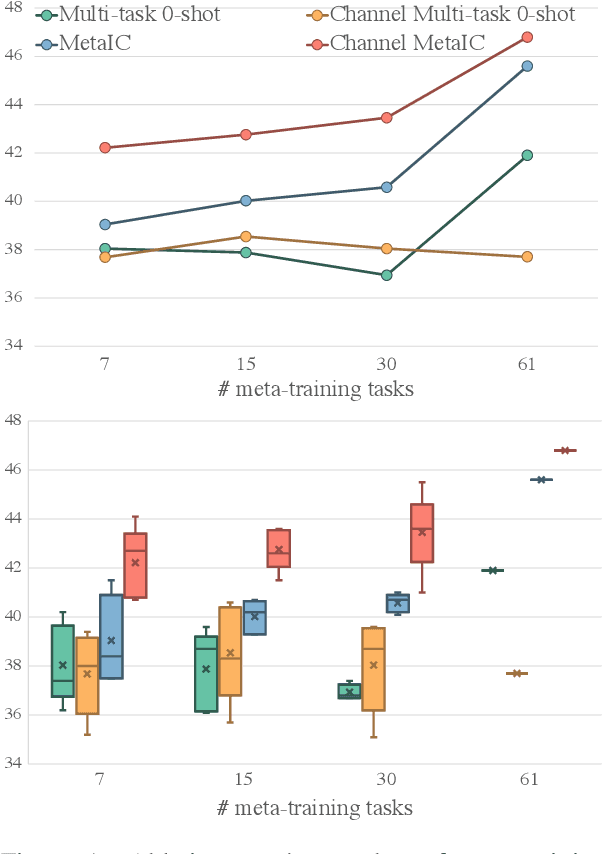
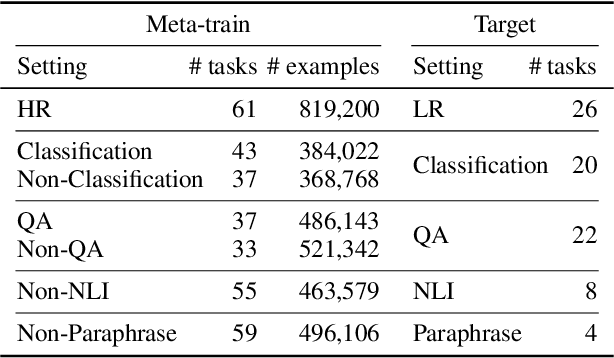
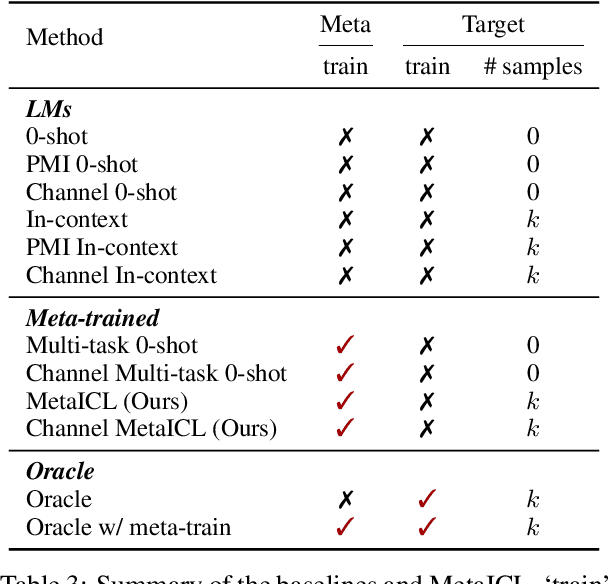
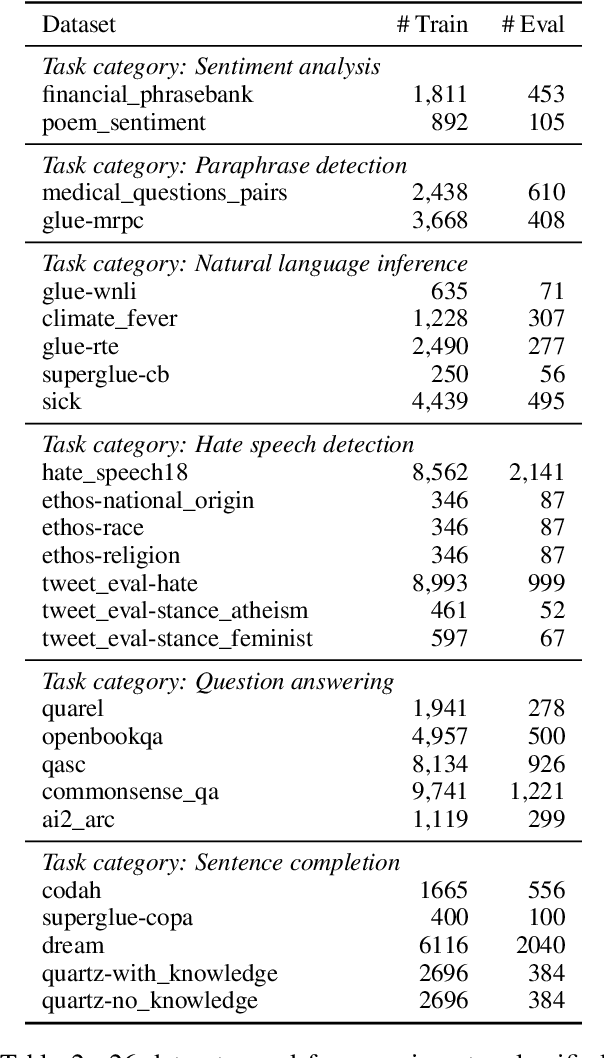
We introduce MetaICL (Meta-training for In-Context Learning), a new meta-training framework for few-shot learning where a pretrained language model is tuned to do in-context learn-ing on a large set of training tasks. This meta-training enables the model to more effectively learn a new task in context at test time, by simply conditioning on a few training examples with no parameter updates or task-specific templates. We experiment on a large, diverse collection of tasks consisting of 142 NLP datasets including classification, question answering, natural language inference, paraphrase detection and more, across seven different meta-training/target splits. MetaICL outperforms a range of baselines including in-context learning without meta-training and multi-task learning followed by zero-shot transfer. We find that the gains are particularly significant for target tasks that have domain shifts from the meta-training tasks, and that using a diverse set of the meta-training tasks is key to improvements. We also show that MetaICL approaches (and sometimes beats) the performance of models fully finetuned on the target task training data, and outperforms much bigger models with nearly 8x parameters.
Sparse Distillation: Speeding Up Text Classification by Using Bigger Models
Oct 16, 2021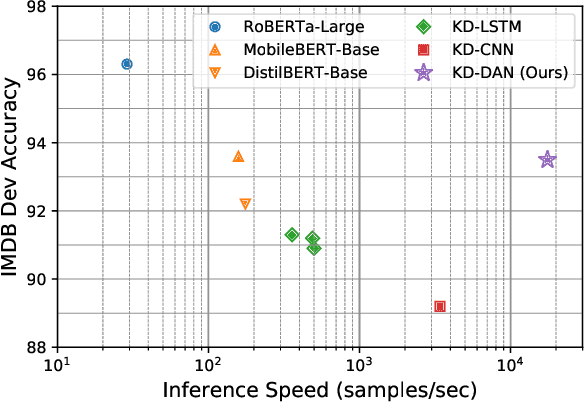
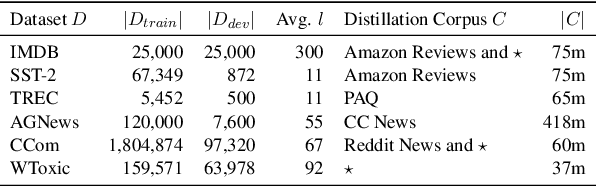
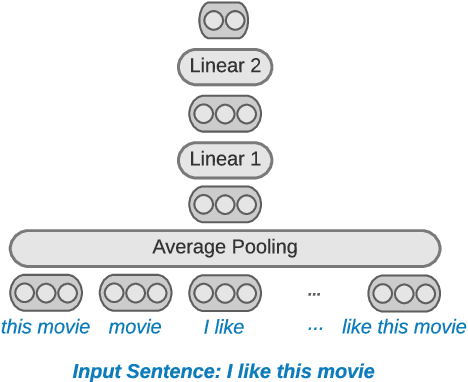
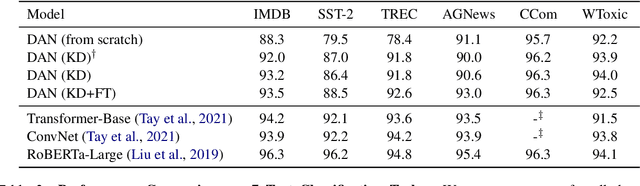
Distilling state-of-the-art transformer models into lightweight student models is an effective way to reduce computation cost at inference time. However, the improved inference speed may be still unsatisfactory for certain time-sensitive applications. In this paper, we aim to further push the limit of inference speed by exploring a new area in the design space of the student model. More specifically, we consider distilling a transformer-based text classifier into a billion-parameter, sparsely-activated student model with a embedding-averaging architecture. Our experiments show that the student models retain 97% of the RoBERTa-Large teacher performance on a collection of six text classification tasks. Meanwhile, the student model achieves up to 600x speed-up on both GPUs and CPUs, compared to the teacher models. Further investigation shows that our pipeline is also effective in privacy-preserving and domain generalization settings.
Tricks for Training Sparse Translation Models
Oct 15, 2021
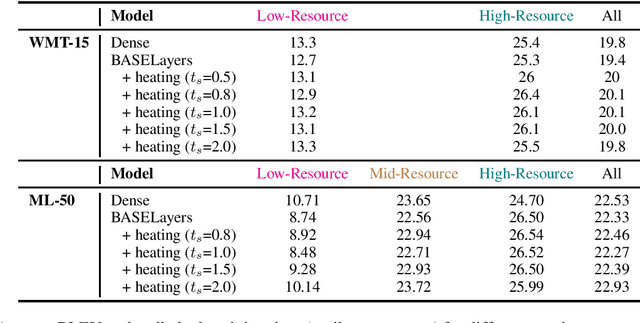
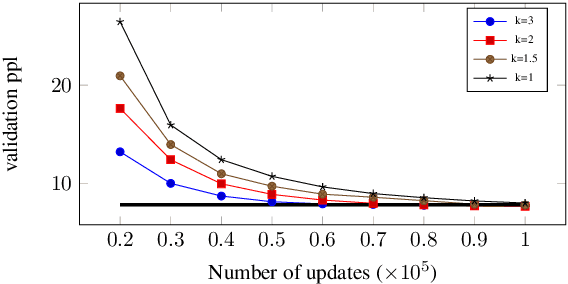
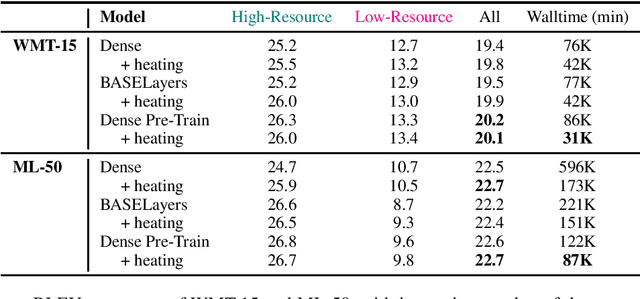
Multi-task learning with an unbalanced data distribution skews model learning towards high resource tasks, especially when model capacity is fixed and fully shared across all tasks. Sparse scaling architectures, such as BASELayers, provide flexible mechanisms for different tasks to have a variable number of parameters, which can be useful to counterbalance skewed data distributions. We find that that sparse architectures for multilingual machine translation can perform poorly out of the box, and propose two straightforward techniques to mitigate this - a temperature heating mechanism and dense pre-training. Overall, these methods improve performance on two multilingual translation benchmarks compared to standard BASELayers and Dense scaling baselines, and in combination, more than 2x model convergence speed.
8-bit Optimizers via Block-wise Quantization
Oct 06, 2021



Stateful optimizers maintain gradient statistics over time, e.g., the exponentially smoothed sum (SGD with momentum) or squared sum (Adam) of past gradient values. This state can be used to accelerate optimization compared to plain stochastic gradient descent but uses memory that might otherwise be allocated to model parameters, thereby limiting the maximum size of models trained in practice. In this paper, we develop the first optimizers that use 8-bit statistics while maintaining the performance levels of using 32-bit optimizer states. To overcome the resulting computational, quantization, and stability challenges, we develop block-wise dynamic quantization. Block-wise quantization divides input tensors into smaller blocks that are independently quantized. Each block is processed in parallel across cores, yielding faster optimization and high precision quantization. To maintain stability and performance, we combine block-wise quantization with two additional changes: (1) dynamic quantization, a form of non-linear optimization that is precise for both large and small magnitude values, and (2) a stable embedding layer to reduce gradient variance that comes from the highly non-uniform distribution of input tokens in language models. As a result, our 8-bit optimizers maintain 32-bit performance with a small fraction of the memory footprint on a range of tasks, including 1.5B parameter language modeling, GLUE finetuning, ImageNet classification, WMT'14 machine translation, MoCo v2 contrastive ImageNet pretraining+finetuning, and RoBERTa pretraining, without changes to the original optimizer hyperparameters. We open-source our 8-bit optimizers as a drop-in replacement that only requires a two-line code change.
Train Short, Test Long: Attention with Linear Biases Enables Input Length Extrapolation
Aug 27, 2021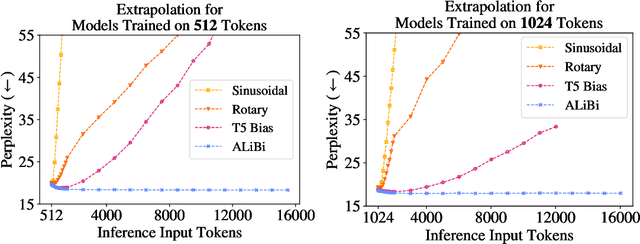
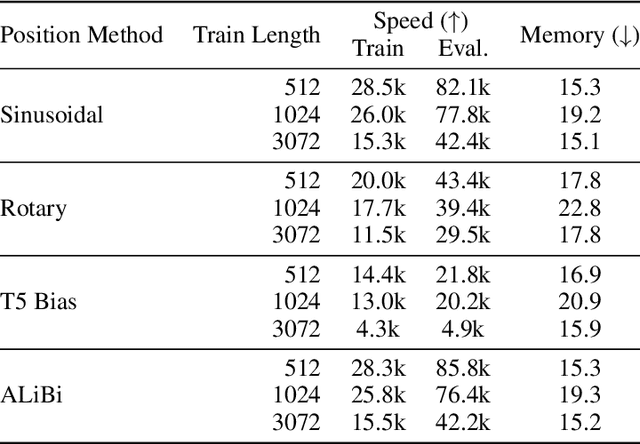

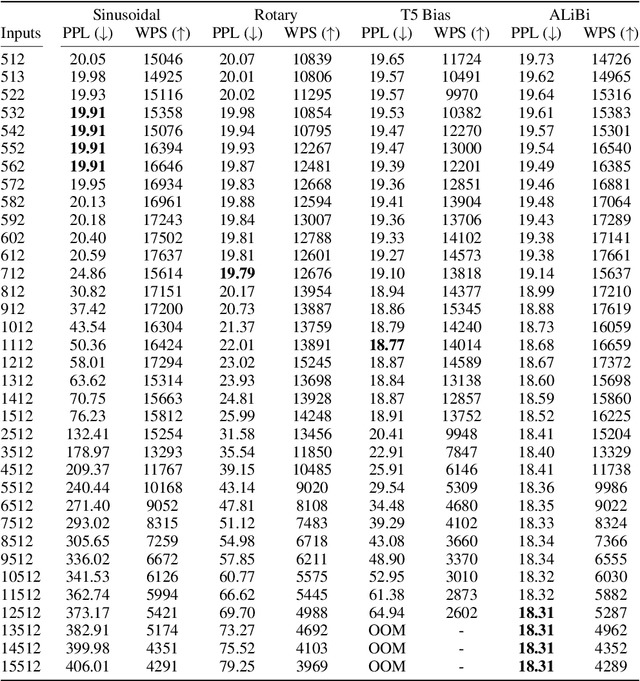
Since the introduction of the transformer model by Vaswani et al. (2017), a fundamental question remains open: how to achieve extrapolation at inference time to longer sequences than seen during training? We first show that extrapolation can be improved by changing the position representation method, though we find that existing proposals do not allow efficient extrapolation. We introduce a simple and efficient method, Attention with Linear Biases (ALiBi), that allows for extrapolation. ALiBi does not add positional embeddings to the word embeddings; instead, it biases the query-key attention scores with a term that is proportional to their distance. We show that this method allows training a 1.3 billion parameter model on input sequences of length 1024 that extrapolates to input sequences of length 2048, achieving the same perplexity as a sinusoidal position embedding model trained on inputs of length 2048, 11% faster and using 11% less memory. ALiBi's inductive bias towards recency allows it to outperform multiple strong position methods on the WikiText-103 benchmark. Finally, we provide analysis of ALiBi to understand why it leads to better performance.
DEMix Layers: Disentangling Domains for Modular Language Modeling
Aug 20, 2021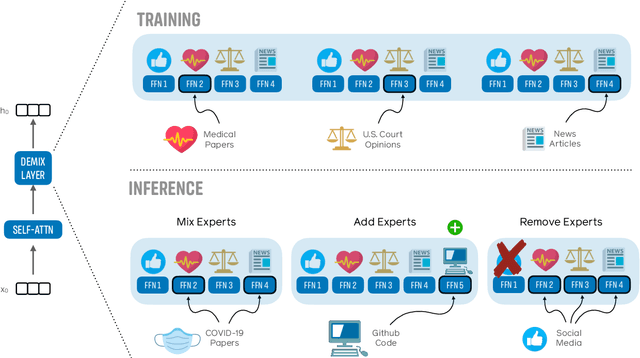
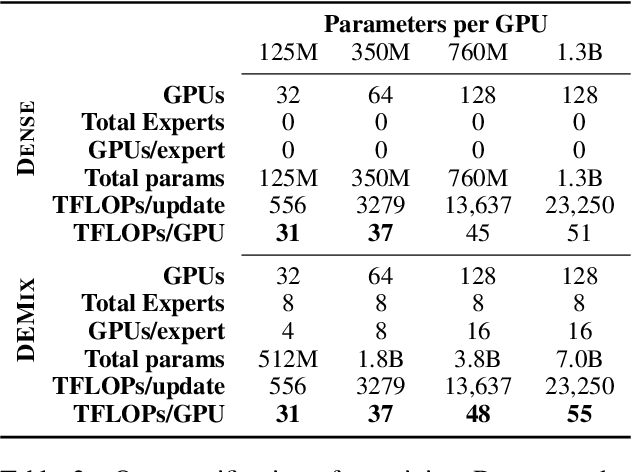
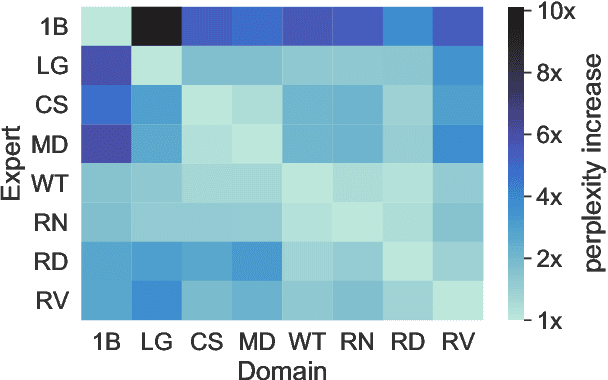
We introduce a new domain expert mixture (DEMix) layer that enables conditioning a language model (LM) on the domain of the input text. A DEMix layer is a collection of expert feedforward networks, each specialized to a domain, that makes the LM modular: experts can be mixed, added or removed after initial training. Extensive experiments with autoregressive transformer LMs (up to 1.3B parameters) show that DEMix layers reduce test-time perplexity, increase training efficiency, and enable rapid adaptation with little overhead. We show that mixing experts during inference, using a parameter-free weighted ensemble, allows the model to better generalize to heterogeneous or unseen domains. We also show that experts can be added to iteratively incorporate new domains without forgetting older ones, and that experts can be removed to restrict access to unwanted domains, without additional training. Overall, these results demonstrate benefits of explicitly conditioning on textual domains during language modeling.
Noisy Channel Language Model Prompting for Few-Shot Text Classification
Aug 15, 2021

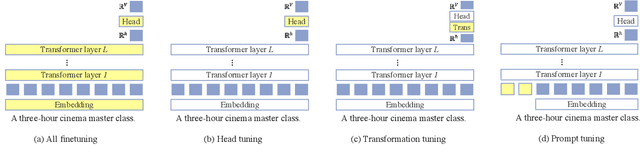
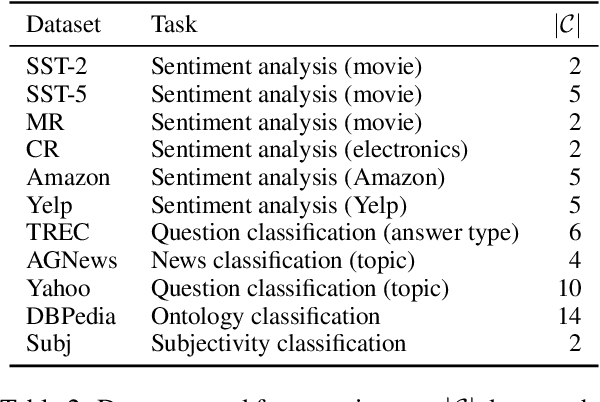
We introduce a noisy channel approach for language model prompting in few-shot text classification. Instead of computing the likelihood of the label given the input (referred as direct models), channel models compute the conditional probability of the input given the label, and are thereby required to explain every word in the input. We use channel models for recently proposed few-shot learning methods with no or very limited updates to the language model parameters, via either in-context demonstration or prompt tuning. Our experiments show that, for both methods, channel models significantly outperform their direct counterparts, which we attribute to their stability, i.e., lower variance and higher worst-case accuracy. We also present extensive ablations that provide recommendations for when to use channel prompt tuning instead of other competitive models (e.g., direct head tuning): channel prompt tuning is preferred when the number of training examples is small, labels in the training data are imbalanced, or generalization to unseen labels is required.
HTLM: Hyper-Text Pre-Training and Prompting of Language Models
Jul 14, 2021



We introduce HTLM, a hyper-text language model trained on a large-scale web crawl. Modeling hyper-text has a number of advantages: (1) it is easily gathered at scale, (2) it provides rich document-level and end-task-adjacent supervision (e.g. class and id attributes often encode document category information), and (3) it allows for new structured prompting that follows the established semantics of HTML (e.g. to do zero-shot summarization by infilling title tags for a webpage that contains the input text). We show that pretraining with a BART-style denoising loss directly on simplified HTML provides highly effective transfer for a wide range of end tasks and supervision levels. HTLM matches or exceeds the performance of comparably sized text-only LMs for zero-shot prompting and fine-tuning for classification benchmarks, while also setting new state-of-the-art performance levels for zero-shot summarization. We also find that hyper-text prompts provide more value to HTLM, in terms of data efficiency, than plain text prompts do for existing LMs, and that HTLM is highly effective at auto-prompting itself, by simply generating the most likely hyper-text formatting for any available training data. We will release all code and models to support future HTLM research.