 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeMulti-objective Asynchronous Successive Halving
Jun 23, 2021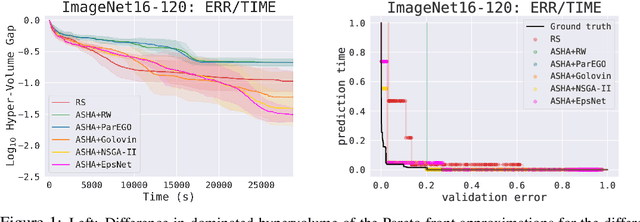

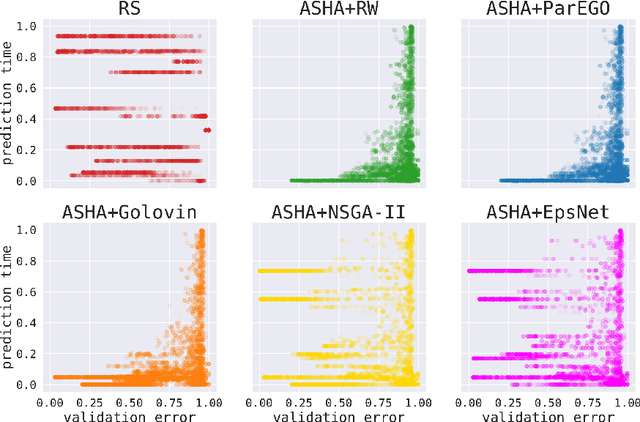

Hyperparameter optimization (HPO) is increasingly used to automatically tune the predictive performance (e.g., accuracy) of machine learning models. However, in a plethora of real-world applications, accuracy is only one of the multiple -- often conflicting -- performance criteria, necessitating the adoption of a multi-objective (MO) perspective. While the literature on MO optimization is rich, few prior studies have focused on HPO. In this paper, we propose algorithms that extend asynchronous successive halving (ASHA) to the MO setting. Considering multiple evaluation metrics, we assess the performance of these methods on three real world tasks: (i) Neural architecture search, (ii) algorithmic fairness and (iii) language model optimization. Our empirical analysis shows that MO ASHA enables to perform MO HPO at scale. Further, we observe that that taking the entire Pareto front into account for candidate selection consistently outperforms multi-fidelity HPO based on MO scalarization in terms of wall-clock time. Our algorithms (to be open-sourced) establish new baselines for future research in the area.
On the Lack of Robust Interpretability of Neural Text Classifiers
Jun 08, 2021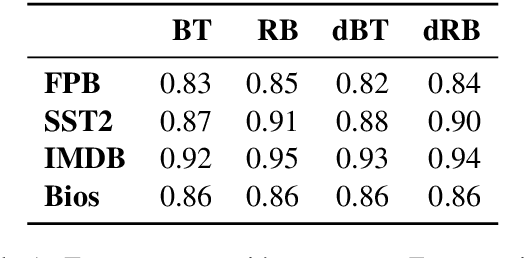
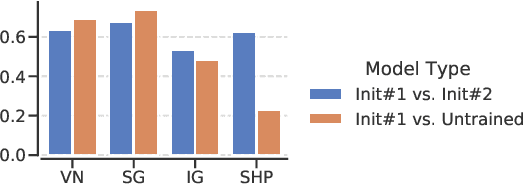

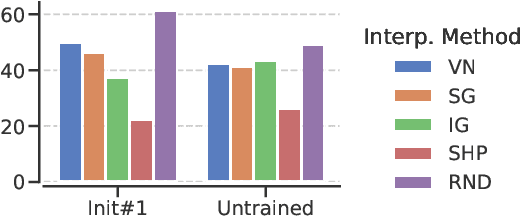
With the ever-increasing complexity of neural language models, practitioners have turned to methods for understanding the predictions of these models. One of the most well-adopted approaches for model interpretability is feature-based interpretability, i.e., ranking the features in terms of their impact on model predictions. Several prior studies have focused on assessing the fidelity of feature-based interpretability methods, i.e., measuring the impact of dropping the top-ranked features on the model output. However, relatively little work has been conducted on quantifying the robustness of interpretations. In this work, we assess the robustness of interpretations of neural text classifiers, specifically, those based on pretrained Transformer encoders, using two randomization tests. The first compares the interpretations of two models that are identical except for their initializations. The second measures whether the interpretations differ between a model with trained parameters and a model with random parameters. Both tests show surprising deviations from expected behavior, raising questions about the extent of insights that practitioners may draw from interpretations.
Amazon SageMaker Automatic Model Tuning: Scalable Black-box Optimization
Dec 15, 2020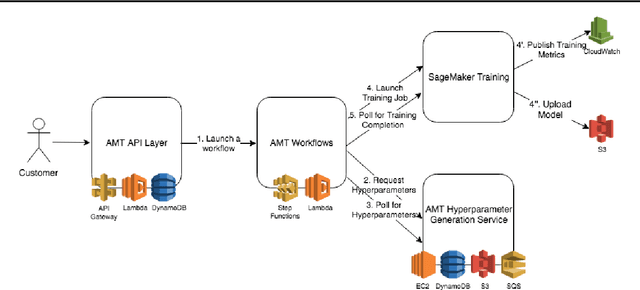
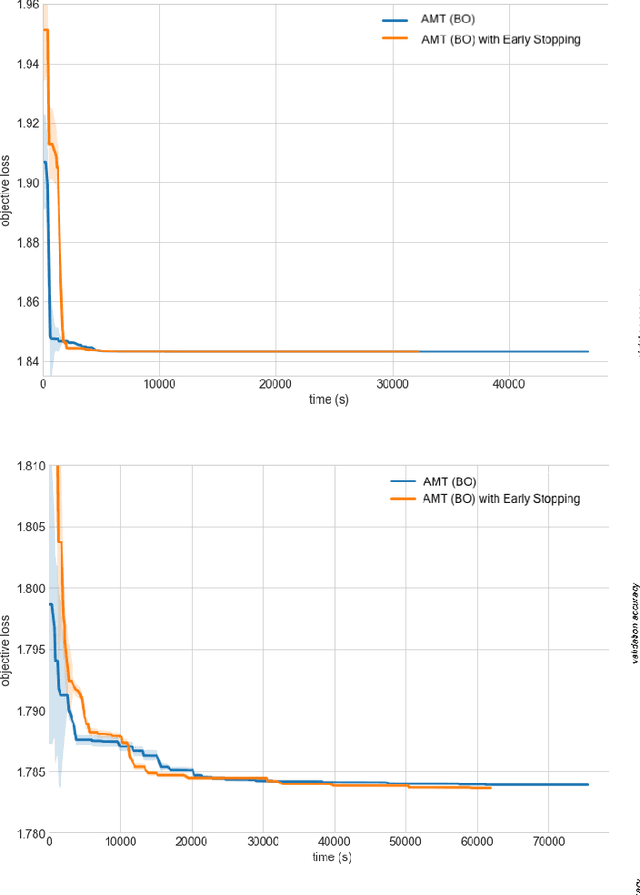
Tuning complex machine learning systems is challenging. Machine learning models typically expose a set of hyperparameters, be it regularization, architecture, or optimization parameters, whose careful tuning is critical to achieve good performance. To democratize access to such systems, it is essential to automate this tuning process. This paper presents Amazon SageMaker Automatic Model Tuning (AMT), a fully managed system for black-box optimization at scale. AMT finds the best version of a machine learning model by repeatedly training it with different hyperparameter configurations. It leverages either random search or Bayesian optimization to choose the hyperparameter values resulting in the best-performing model, as measured by the metric chosen by the user. AMT can be used with built-in algorithms, custom algorithms, and Amazon SageMaker pre-built containers for machine learning frameworks. We discuss the core functionality, system architecture and our design principles. We also describe some more advanced features provided by AMT, such as automated early stopping and warm-starting, demonstrating their benefits in experiments.
Fair Bayesian Optimization
Jun 09, 2020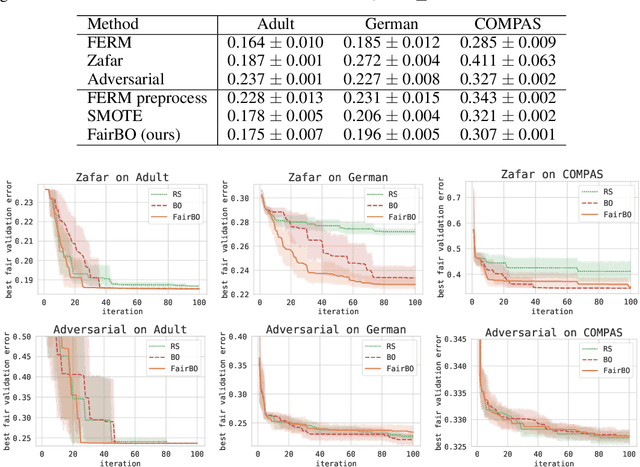
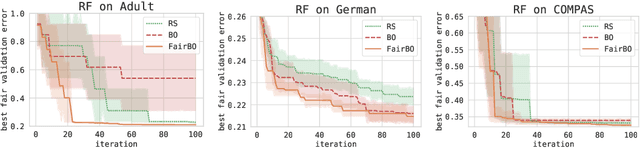

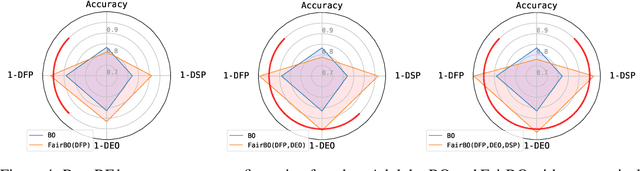
Given the increasing importance of machine learning (ML) in our lives, algorithmic fairness techniques have been proposed to mitigate biases that can be amplified by ML. Commonly, these specialized techniques apply to a single family of ML models and a specific definition of fairness, limiting their effectiveness in practice. We introduce a general constrained Bayesian optimization (BO) framework to optimize the performance of any ML model while enforcing one or multiple fairness constraints. BO is a global optimization method that has been successfully applied to automatically tune the hyperparameters of ML models. We apply BO with fairness constraints to a range of popular models, including random forests, gradient boosting, and neural networks, showing that we can obtain accurate and fair solutions by acting solely on the hyperparameters. We also show empirically that our approach is competitive with specialized techniques that explicitly enforce fairness constraints during training, and outperforms preprocessing methods that learn unbiased representations of the input data. Moreover, our method can be used in synergy with such specialized fairness techniques to tune their hyperparameters. Finally, we study the relationship between hyperparameters and fairness of the generated model. We observe a correlation between regularization and unbiased models, explaining why acting on the hyperparameters leads to ML models that generalize well and are fair.
Scheduling the Learning Rate via Hypergradients: New Insights and a New Algorithm
Oct 18, 2019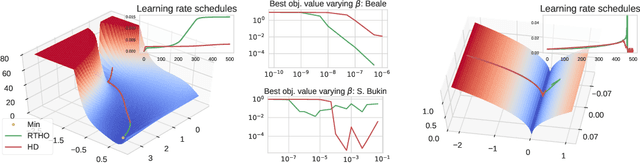
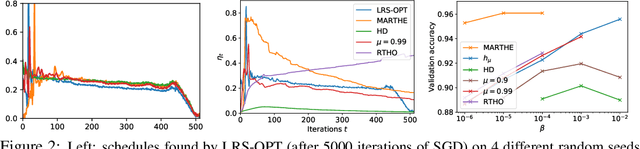
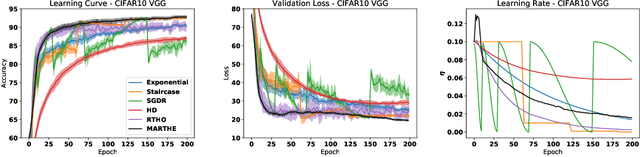
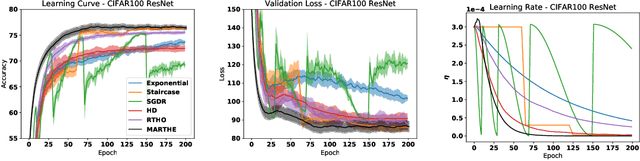
We study the problem of fitting task-specific learning rate schedules from the perspective of hyperparameter optimization. This allows us to explicitly search for schedules that achieve good generalization. We describe the structure of the gradient of a validation error w.r.t. the learning rate, the hypergradient, and based on this we introduce a novel online algorithm. Our method adaptively interpolates between the recently proposed techniques of Franceschi et al. (2017) and Baydin et al. (2017), featuring increased stability and faster convergence. We show empirically that the proposed method compares favourably with baselines and related methods in terms of final test accuracy.
Voting with Random Classifiers (VORACE)
Sep 18, 2019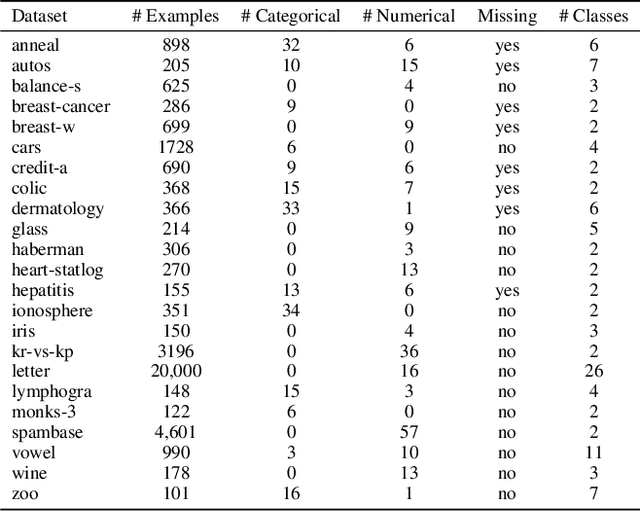
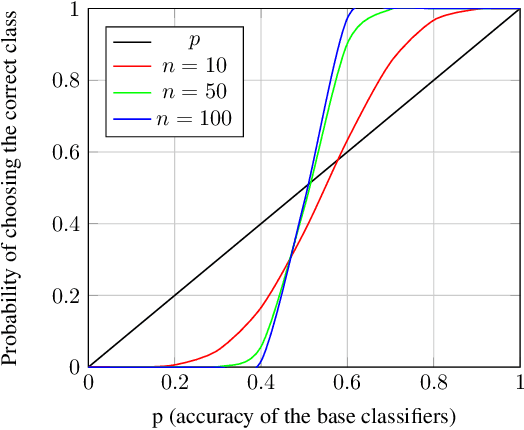

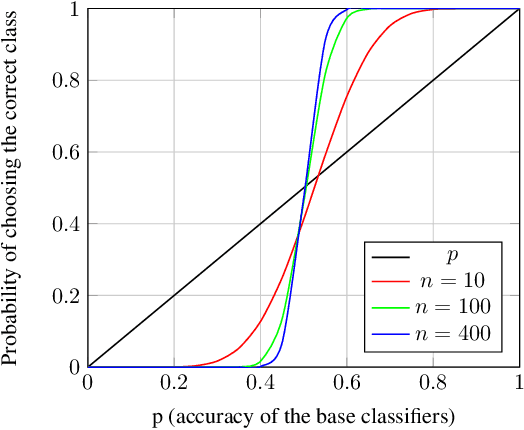
In many machine learning scenarios, looking for the best classifier that fits a particular dataset can be very costly in terms of time and resources. Moreover, it can require deep knowledge of the specific domain. We propose a new technique which does not require profound expertise in the domain and avoids the commonly used strategy of hyper-parameter tuning and model selection. Our method is an innovative ensemble technique that uses voting rules over a set of randomly-generated classifiers. Given a new input sample, we interpret the output of each classifier as a ranking over the set of possible classes. We then aggregate these output rankings using a voting rule, which treats them as preferences over the classes. We show that our approach obtains good results compared to the state-of-the-art, both providing a theoretical analysis and an empirical evaluation of the approach on several datasets.
Learning Fair and Transferable Representations
Jun 25, 2019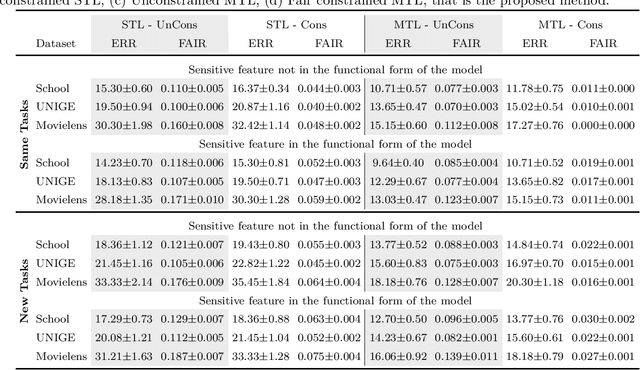
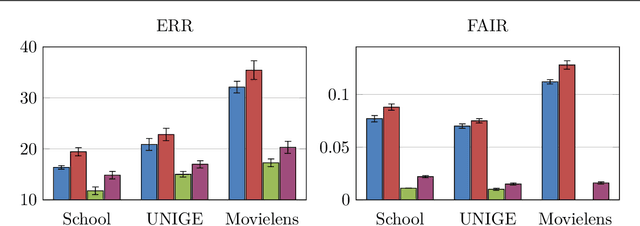
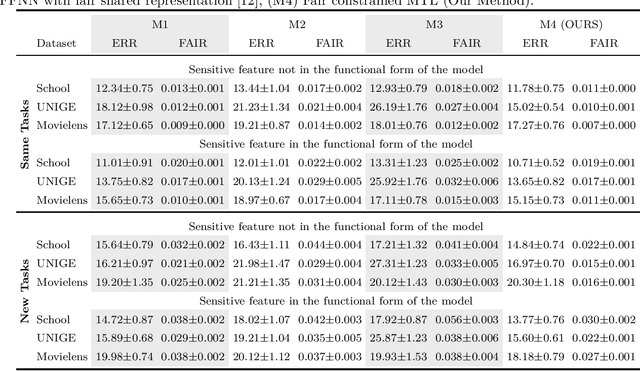
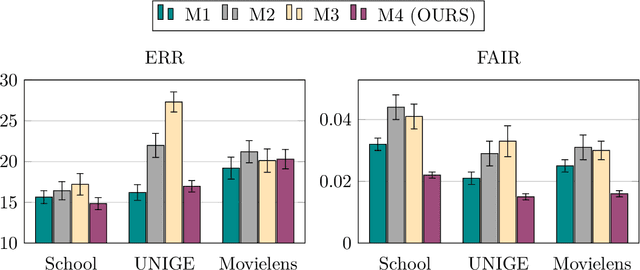
Developing learning methods which do not discriminate subgroups in the population is a central goal of algorithmic fairness. One way to reach this goal is by modifying the data representation in order to meet certain fairness constraints. In this work we measure fairness according to demographic parity. This requires the probability of the possible model decisions to be independent of the sensitive information. We argue that the goal of imposing demographic parity can be substantially facilitated within a multitask learning setting. We leverage task similarities by encouraging a shared fair representation across the tasks via low rank matrix factorization. We derive learning bounds establishing that the learned representation transfers well to novel tasks both in terms of prediction performance and fairness metrics. We present experiments on three real world datasets, showing that the proposed method outperforms state-of-the-art approaches by a significant margin.
General Fair Empirical Risk Minimization
Jan 29, 2019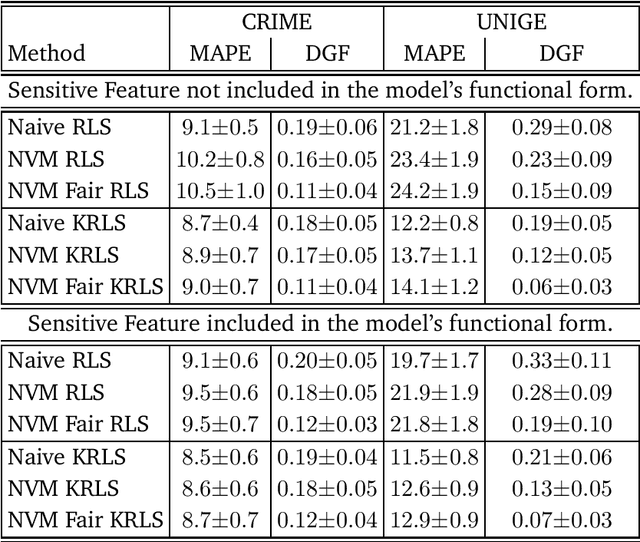
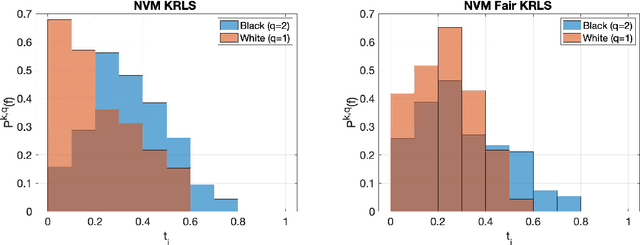
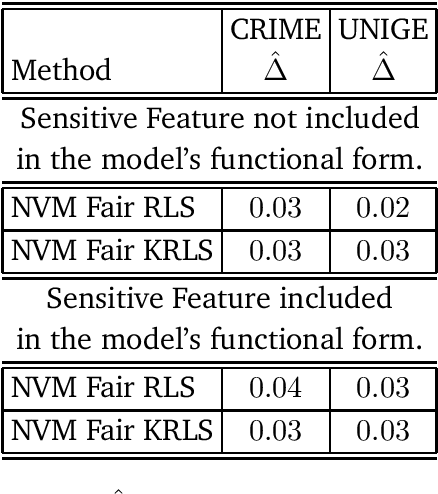
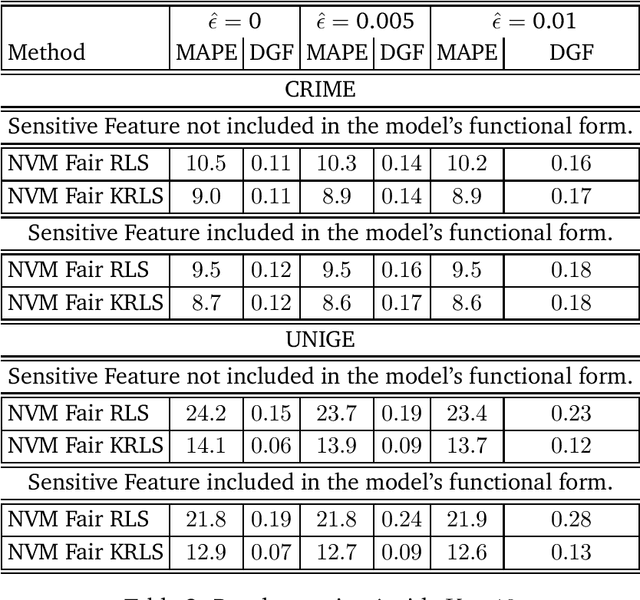
We tackle the problem of algorithmic fairness, where the goal is to avoid the unfairly influence of sensitive information, in the general context of regression with possible continuous sensitive attributes. We extend the framework of fair empirical risk minimization to this general scenario, covering in this way the whole standard supervised learning setting. Our generalized fairness measure reduces to well known notions of fairness available in literature. We derive learning guarantees for our method, that imply in particular its statistical consistency, both in terms of the risk and the fairness measure. We then specialize our approach to kernel methods and propose a convex fair estimator in that setting. We test the estimator on a commonly used benchmark dataset (Communities and Crime) and on a new dataset collected at the University of Genova, containing the information of the academic career of five thousand students. The latter dataset provides a challenging real case scenario of unfair behaviour of standard regression methods that benefits from our methodology. The experimental results show that our estimator is effective at mitigating the trade-off between accuracy and fairness requirements.
Taking Advantage of Multitask Learning for Fair Classification
Oct 19, 2018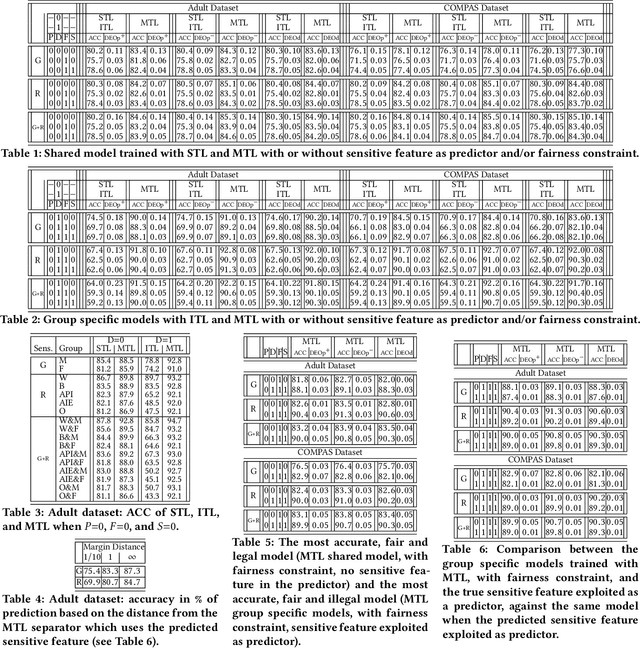
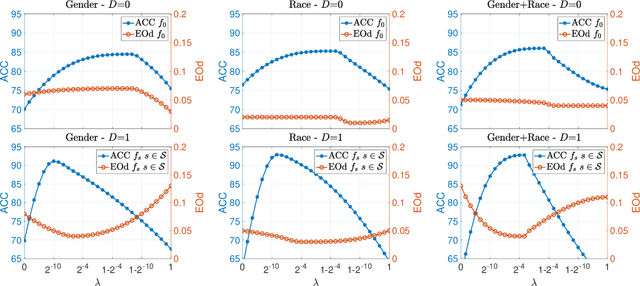
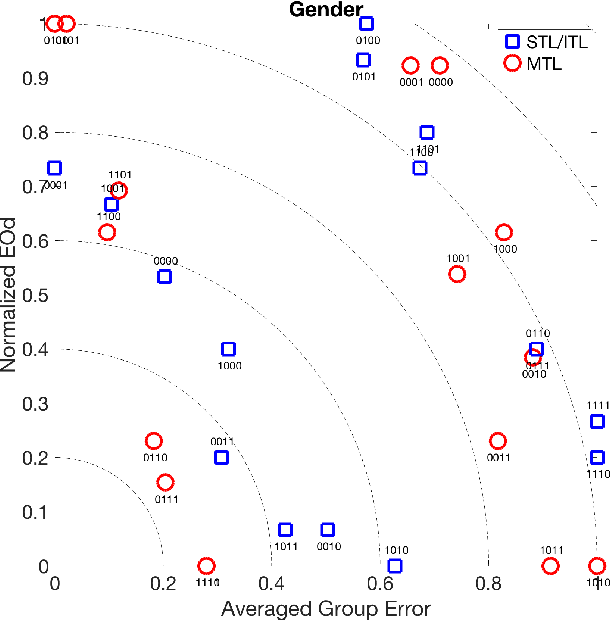
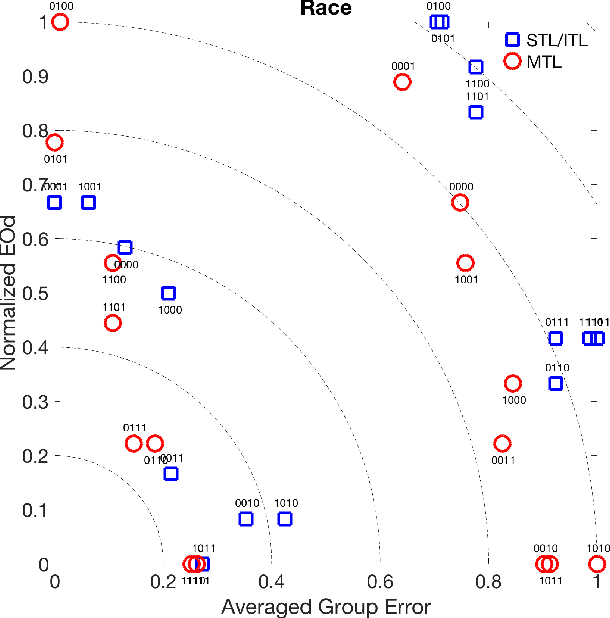
A central goal of algorithmic fairness is to reduce bias in automated decision making. An unavoidable tension exists between accuracy gains obtained by using sensitive information (e.g., gender or ethnic group) as part of a statistical model, and any commitment to protect these characteristics. Often, due to biases present in the data, using the sensitive information in the functional form of a classifier improves classification accuracy. In this paper we show how it is possible to get the best of both worlds: optimize model accuracy and fairness without explicitly using the sensitive feature in the functional form of the model, thereby treating different individuals equally. Our method is based on two key ideas. On the one hand, we propose to use Multitask Learning (MTL), enhanced with fairness constraints, to jointly learn group specific classifiers that leverage information between sensitive groups. On the other hand, since learning group specific models might not be permitted, we propose to first predict the sensitive features by any learning method and then to use the predicted sensitive feature to train MTL with fairness constraints. This enables us to tackle fairness with a three-pronged approach, that is, by increasing accuracy on each group, enforcing measures of fairness during training, and protecting sensitive information during testing. Experimental results on two real datasets support our proposal, showing substantial improvements in both accuracy and fairness.
Empirical Risk Minimization under Fairness Constraints
Jun 26, 2018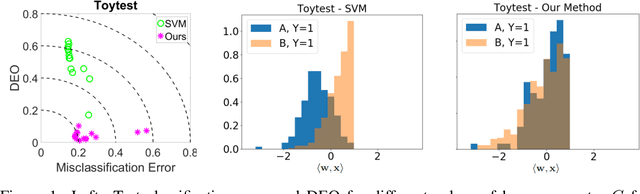
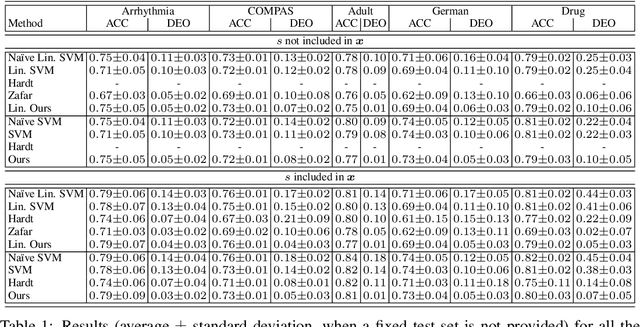
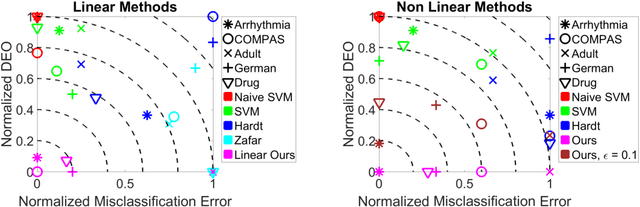
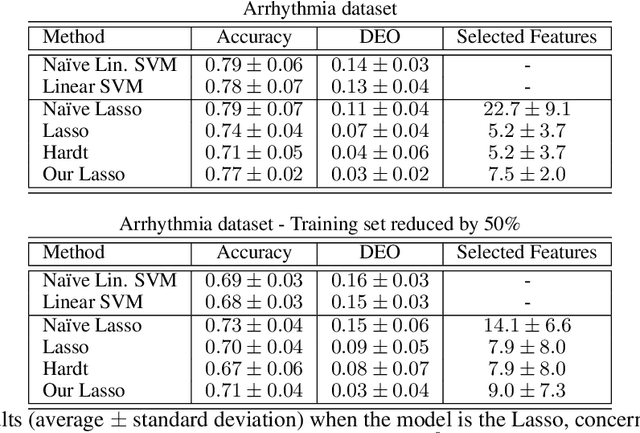
We address the problem of algorithmic fairness: ensuring that sensitive variables do not unfairly influence the outcome of a classifier. We present an approach based on empirical risk minimization, which incorporates a fairness constraint into the learning problem. It encourages the conditional risk of the learned classifier to be approximately constant with respect to the sensitive variable. We derive both risk and fairness bounds that support the statistical consistency of our approach. We specify our approach to kernel methods and observe that the fairness requirement implies an orthogonality constraint which can be easily added to these methods. We further observe that for linear models the constraint translates into a simple data preprocessing step. Experiments indicate that the method is empirically effective and performs favorably against state-of-the-art approaches.