 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeEncrypted Large Model Inference: The Equivariant Encryption Paradigm
Feb 03, 2025Large scale deep learning model, such as modern language models and diffusion architectures, have revolutionized applications ranging from natural language processing to computer vision. However, their deployment in distributed or decentralized environments raises significant privacy concerns, as sensitive data may be exposed during inference. Traditional techniques like secure multi-party computation, homomorphic encryption, and differential privacy offer partial remedies but often incur substantial computational overhead, latency penalties, or limited compatibility with non-linear network operations. In this work, we introduce Equivariant Encryption (EE), a novel paradigm designed to enable secure, "blind" inference on encrypted data with near zero performance overhead. Unlike fully homomorphic approaches that encrypt the entire computational graph, EE selectively obfuscates critical internal representations within neural network layers while preserving the exact functionality of both linear and a prescribed set of non-linear operations. This targeted encryption ensures that raw inputs, intermediate activations, and outputs remain confidential, even when processed on untrusted infrastructure. We detail the theoretical foundations of EE, compare its performance and integration complexity against conventional privacy preserving techniques, and demonstrate its applicability across a range of architectures, from convolutional networks to large language models. Furthermore, our work provides a comprehensive threat analysis, outlining potential attack vectors and baseline strategies, and benchmarks EE against standard inference pipelines in decentralized settings. The results confirm that EE maintains high fidelity and throughput, effectively bridging the gap between robust data confidentiality and the stringent efficiency requirements of modern, large scale model inference.
Grounding Open-Domain Instructions to Automate Web Support Tasks
Apr 04, 2021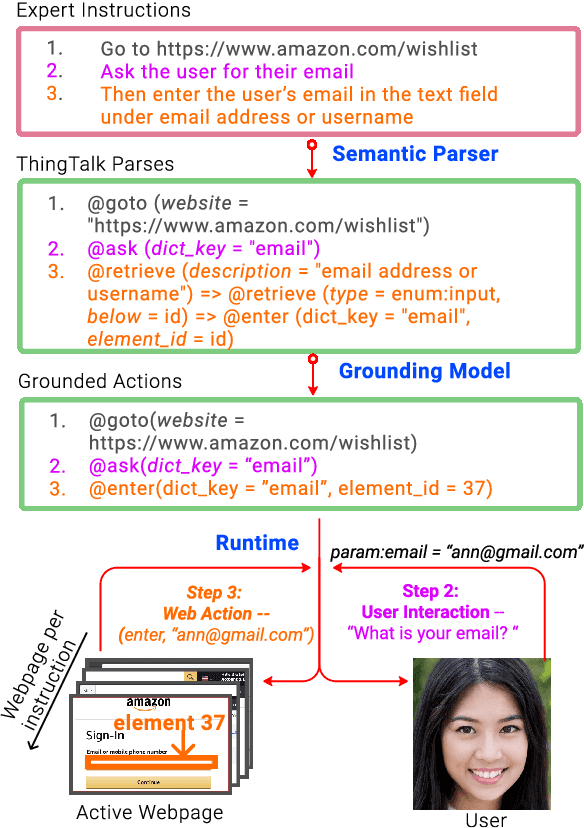
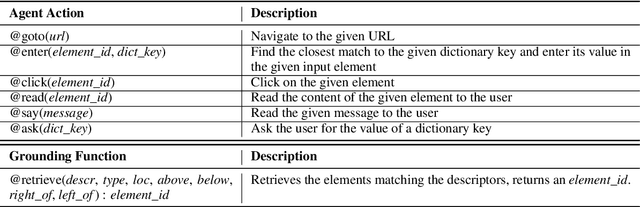
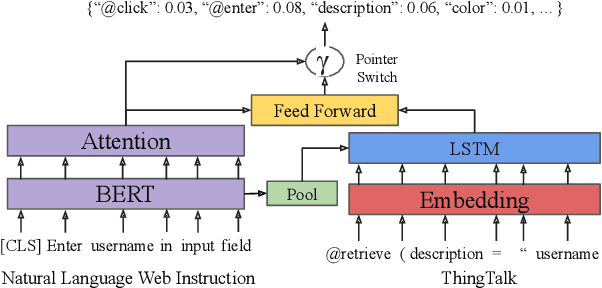

Grounding natural language instructions on the web to perform previously unseen tasks enables accessibility and automation. We introduce a task and dataset to train AI agents from open-domain, step-by-step instructions originally written for people. We build RUSS (Rapid Universal Support Service) to tackle this problem. RUSS consists of two models: First, a BERT-LSTM with pointers parses instructions to ThingTalk, a domain-specific language we design for grounding natural language on the web. Then, a grounding model retrieves the unique IDs of any webpage elements requested in ThingTalk. RUSS may interact with the user through a dialogue (e.g. ask for an address) or execute a web operation (e.g. click a button) inside the web runtime. To augment training, we synthesize natural language instructions mapped to ThingTalk. Our dataset consists of 80 different customer service problems from help websites, with a total of 741 step-by-step instructions and their corresponding actions. RUSS achieves 76.7% end-to-end accuracy predicting agent actions from single instructions. It outperforms state-of-the-art models that directly map instructions to actions without ThingTalk. Our user study shows that RUSS is preferred by actual users over web navigation.