 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeTemporally Consistent Horizon Lines
Jul 23, 2019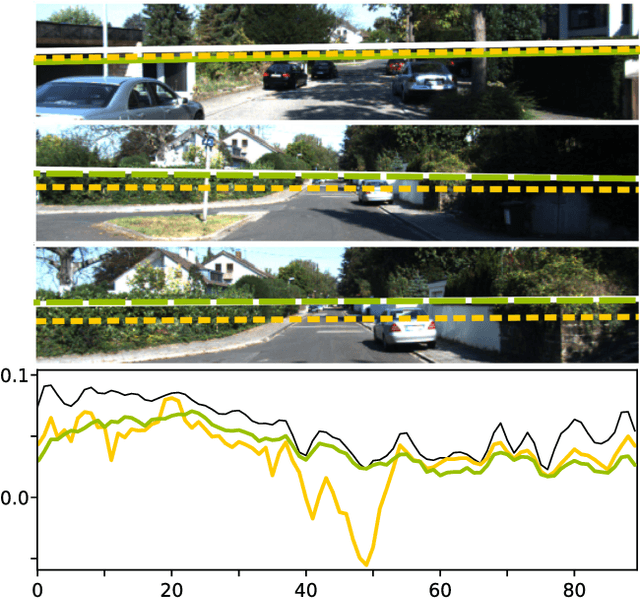
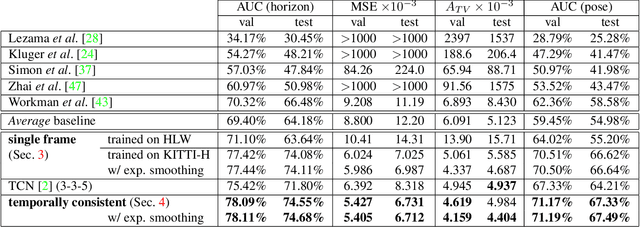
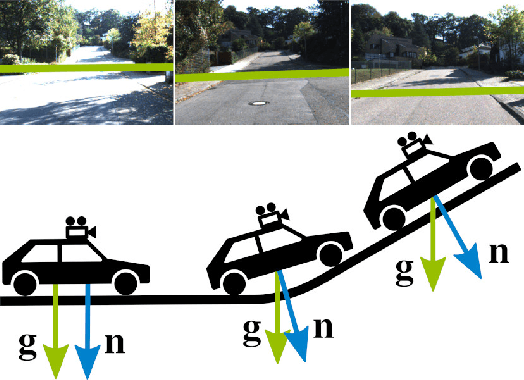
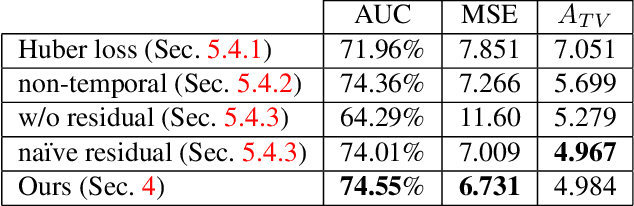
The horizon line is an important geometric feature for many image processing and scene understanding tasks in computer vision. For instance, in navigation of autonomous vehicles or driver assistance, it can be used to improve 3D reconstruction as well as for semantic interpretation of dynamic environments. While both algorithms and datasets exist for single images, the problem of horizon line estimation from video sequences has not gained attention. In this paper, we show how convolutional neural networks are able to utilise the temporal consistency imposed by video sequences in order to increase the accuracy and reduce the variance of horizon line estimates. A novel CNN architecture with an improved residual convolutional LSTM is presented for temporally consistent horizon line estimation. We propose an adaptive loss function that ensures stable training as well as accurate results. Furthermore, we introduce an extension of the KITTI dataset which contains precise horizon line labels for 43699 images across 72 video sequences. A comprehensive evaluation shows that the proposed approach consistently achieves superior performance compared with existing methods.
Unsupervised Domain Adaptation for Multispectral Pedestrian Detection
Apr 07, 2019
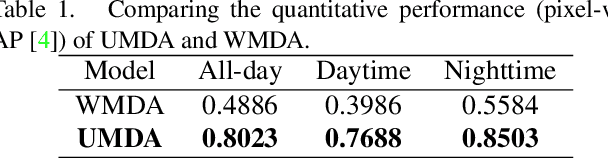
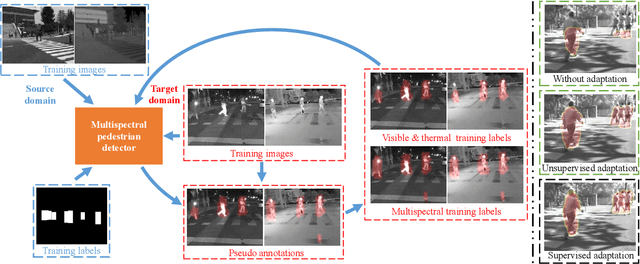

Multimodal information (e.g., visible and thermal) can generate robust pedestrian detections to facilitate around-the-clock computer vision applications, such as autonomous driving and video surveillance. However, it still remains a crucial challenge to train a reliable detector working well in different multispectral pedestrian datasets without manual annotations. In this paper, we propose a novel unsupervised domain adaptation framework for multispectral pedestrian detection, by iteratively generating pseudo annotations and updating the parameters of our designed multispectral pedestrian detector on target domain. Pseudo annotations are generated using the detector trained on source domain, and then updated by fixing the parameters of detector and minimizing the cross entropy loss without back-propagation. Training labels are generated using the pseudo annotations by considering the characteristics of similarity and complementarity between well-aligned visible and infrared image pairs. The parameters of detector are updated using the generated labels by minimizing our defined multi-detection loss function with back-propagation. The optimal parameters of detector can be obtained after iteratively updating the pseudo annotations and parameters. Experimental results show that our proposed unsupervised multimodal domain adaptation method achieves significantly higher detection performance than the approach without domain adaptation, and is competitive with the supervised multispectral pedestrian detectors.
Exploring the Semantics for Visual Relationship Detection
Apr 03, 2019
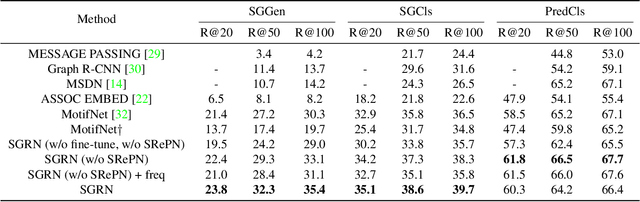
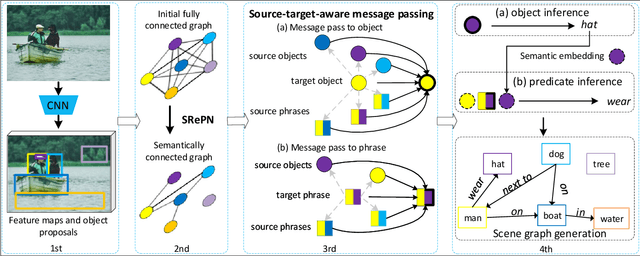
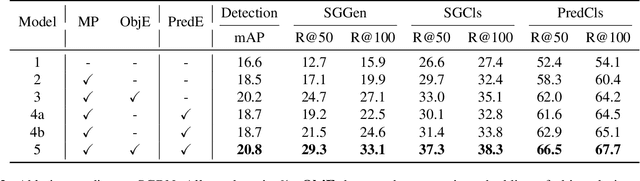
Scene graph construction / visual relationship detection from an image aims to give a precise structural description of the objects (nodes) and their relationships (edges). The mutual promotion of object detection and relationship detection is important for enhancing their individual performance. In this work, we propose a new framework, called semantics guided graph relation neural network (SGRN), for effective visual relationship detection. First, to boost the object detection accuracy, we introduce a source-target class cognoscitive transformation that transforms the features of the co-occurent objects to the target object domain to refine the visual features. Similarly, source-target cognoscitive transformations are used to refine features of objects from features of relations, and vice versa. Second, to boost the relation detection accuracy, besides the visual features of the paired objects, we embed the class probability of the object and subject separately to provide high level semantic information. In addition, to reduce the search space of relationships, we design a semantics-aware relationship filter to exclude those object pairs that have no relation. We evaluate our approach on the Visual Genome dataset and it achieves the state-of-the-art performance for visual relationship detection. Additionally, Our approach also significantly improves the object detection performance (i.e. 4.2\% in mAP accuracy).
Robust object extraction from remote sensing data
Apr 03, 2019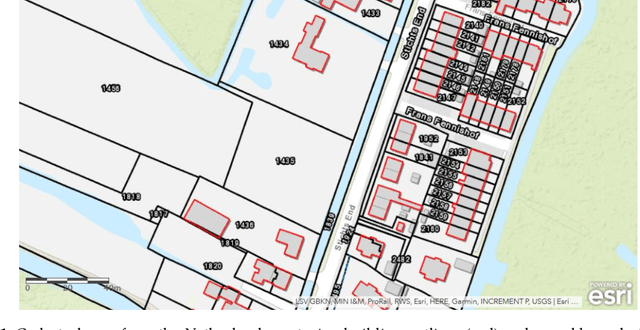

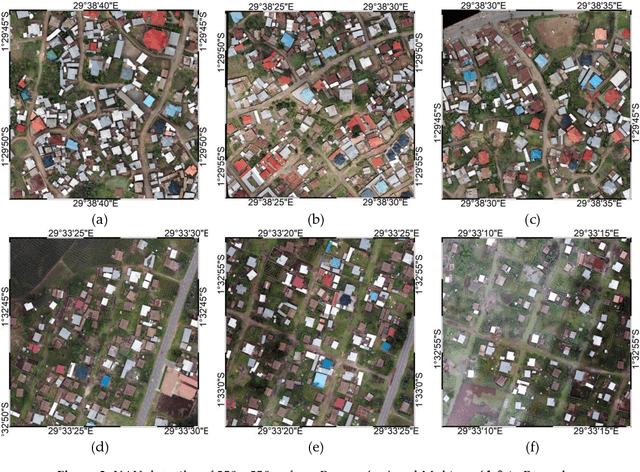
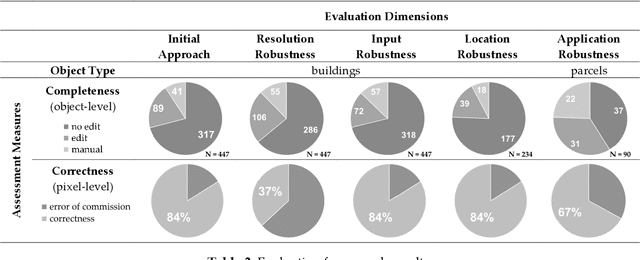
The extraction of object outlines has been a research topic during the last decades. In spite of advances in photogrammetry, remote sensing and computer vision, this task remains challenging due to object and data complexity. The development of object extraction approaches is promoted through publically available benchmark datasets and evaluation frameworks. Many aspects of performance evaluation have already been studied. This study collects the best practices from literature, puts the various aspects in one evaluation framework, and demonstrates its usefulness to a case study on mapping object outlines. The evaluation framework includes five dimensions: the robustness to changes in resolution, input, location, parameters, and application. Examples for investigating these dimensions are provided, as well as accuracy measures for their qualitative analysis. The measures consist of time efficiency and a procedure for line-based accuracy assessment regarding quantitative completeness and spatial correctness. The delineation approach to which the evaluation framework is applied, was previously introduced and is substantially improved in this study.
Box-level Segmentation Supervised Deep Neural Networks for Accurate and Real-time Multispectral Pedestrian Detection
Feb 14, 2019
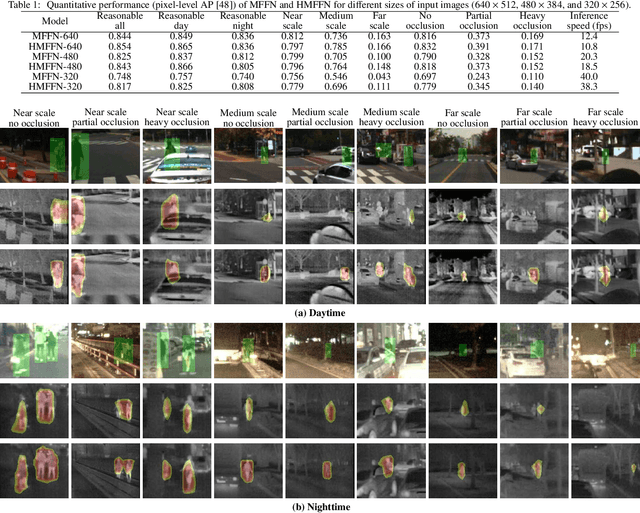
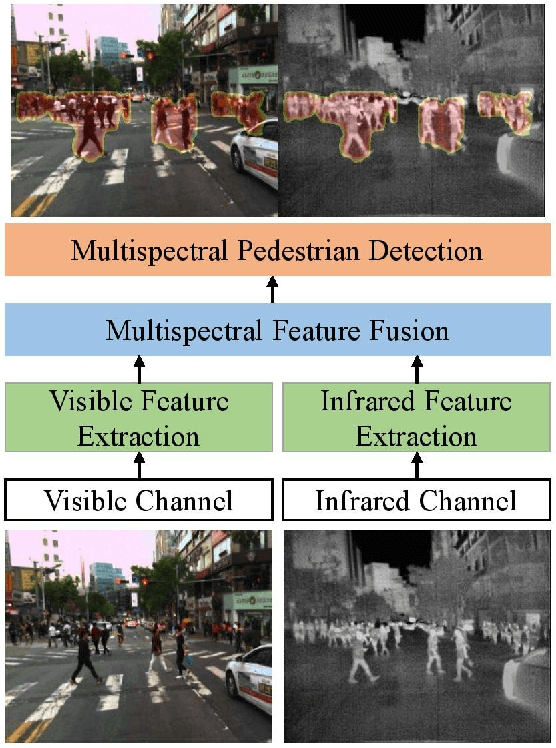
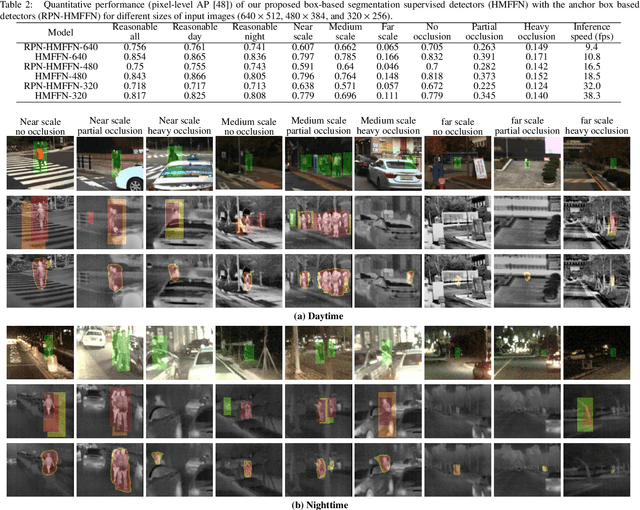
Effective fusion of complementary information captured by multi-modal sensors (visible and infrared cameras) enables robust pedestrian detection under various surveillance situations (e.g. daytime and nighttime). In this paper, we present a novel box-level segmentation supervised learning framework for accurate and real-time multispectral pedestrian detection by incorporating features extracted in visible and infrared channels. Specifically, our method takes pairs of aligned visible and infrared images with easily obtained bounding box annotations as input and estimates accurate prediction maps to highlight the existence of pedestrians. It offers two major advantages over the existing anchor box based multispectral detection methods. Firstly, it overcomes the hyperparameter setting problem occurred during the training phase of anchor box based detectors and can obtain more accurate detection results, especially for small and occluded pedestrian instances. Secondly, it is capable of generating accurate detection results using small-size input images, leading to improvement of computational efficiency for real-time autonomous driving applications. Experimental results on KAIST multispectral dataset show that our proposed method outperforms state-of-the-art approaches in terms of both accuracy and speed.
Security Event Recognition for Visual Surveillance
Oct 26, 2018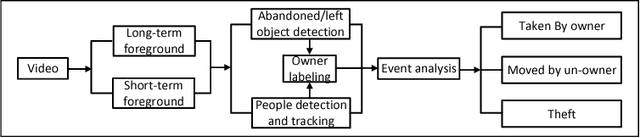
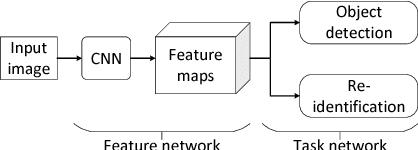

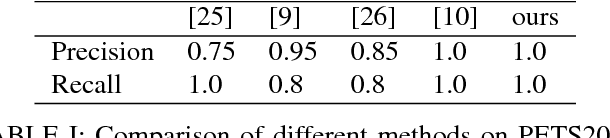
With rapidly increasing deployment of surveillance cameras, the reliable methods for automatically analyzing the surveillance video and recognizing special events are demanded by different practical applications. This paper proposes a novel effective framework for security event analysis in surveillance videos. First, convolutional neural network (CNN) framework is used to detect objects of interest in the given videos. Second, the owners of the objects are recognized and monitored in real-time as well. If anyone moves any object, this person will be verified whether he/she is its owner. If not, this event will be further analyzed and distinguished between two different scenes: moving the object away or stealing it. To validate the proposed approach, a new video dataset consisting of various scenarios is constructed for more complex tasks. For comparison purpose, the experiments are also carried out on the benchmark databases related to the task on abandoned luggage detection. The experimental results show that the proposed approach outperforms the state-of-the-art methods and effective in recognizing complex security events.
The UAVid Dataset for Video Semantic Segmentation
Oct 24, 2018

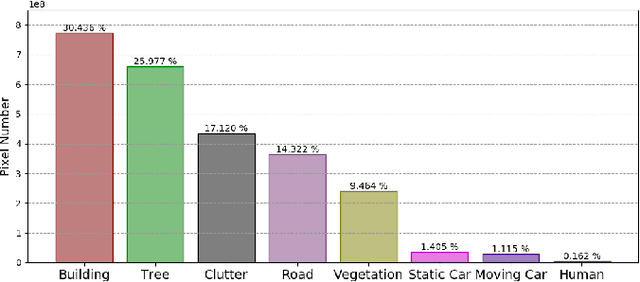
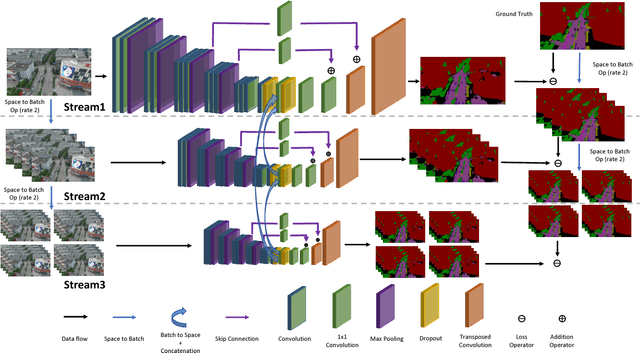
Video semantic segmentation has been one of the research focus in computer vision recently. It serves as a perception foundation for many fields such as robotics and autonomous driving. The fast development of semantic segmentation attributes enormously to the large scale datasets, especially for the deep learning related methods. Currently, there already exist several semantic segmentation datasets for complex urban scenes, such as the Cityscapes and CamVid datasets. They have been the standard datasets for comparison among semantic segmentation methods. In this paper, we introduce a new high resolution UAV video semantic segmentation dataset as complement, UAVid. Our UAV dataset consists of 30 video sequences capturing high resolution images. In total, 300 images have been densely labelled with 8 classes for urban scene understanding task. Our dataset brings out new challenges. We provide several deep learning baseline methods, among which the proposed novel Multi-Scale-Dilation net performs the best via multi-scale feature extraction. We have also explored the usability of sequence data by leveraging on CRF model in both spatial and temporal domain.
Change Detection between Multimodal Remote Sensing Data Using Siamese CNN
Jul 25, 2018

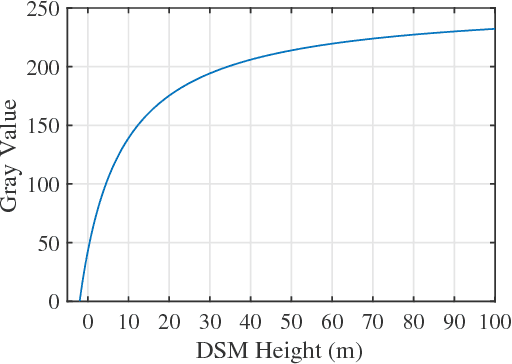

Detecting topographic changes in the urban environment has always been an important task for urban planning and monitoring. In practice, remote sensing data are often available in different modalities and at different time epochs. Change detection between multimodal data can be very challenging since the data show different characteristics. Given 3D laser scanning point clouds and 2D imagery from different epochs, this paper presents a framework to detect building and tree changes. First, the 2D and 3D data are transformed to image patches, respectively. A Siamese CNN is then employed to detect candidate changes between the two epochs. Finally, the candidate patch-based changes are grouped and verified as individual object changes. Experiments on the urban data show that 86.4\% of patch pairs can be correctly classified by the model.
Patch-based Evaluation of Dense Image Matching Quality
Jul 25, 2018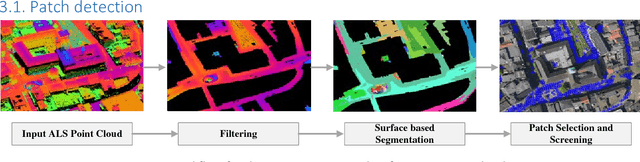

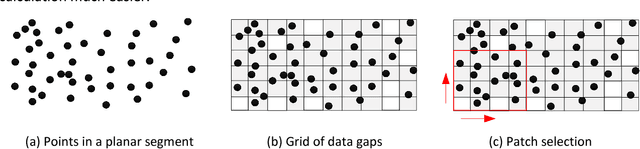

Airborne laser scanning and photogrammetry are two main techniques to obtain 3D data representing the object surface. Due to the high cost of laser scanning, we want to explore the potential of using point clouds derived by dense image matching (DIM), as effective alternatives to laser scanning data. We present a framework to evaluate point clouds from dense image matching and derived Digital Surface Models (DSM) based on automatically extracted sample patches. Dense matching error and noise level are evaluated quantitatively at both the local level and whole block level. Experiments show that the optimal vertical accuracy achieved by dense matching is as follows: the mean offset to the reference data is 0.1 Ground Sampling Distance (GSD); the maximum offset goes up to 1.0 GSD. When additional oblique images are used in dense matching, the mean deviation, the variation of mean deviation and the level of random noise all get improved. We also detect a bias between the point cloud and DSM from a single photogrammetric workflow. This framework also allows to reveal inhomogeneity in the distribution of the dense matching errors due to over-fitted BBA network. Meanwhile, suggestions are given on the photogrammetric quality control.
* 16 pages
Object Recognition from very few Training Examples for Enhancing Bicycle Maps
May 28, 2018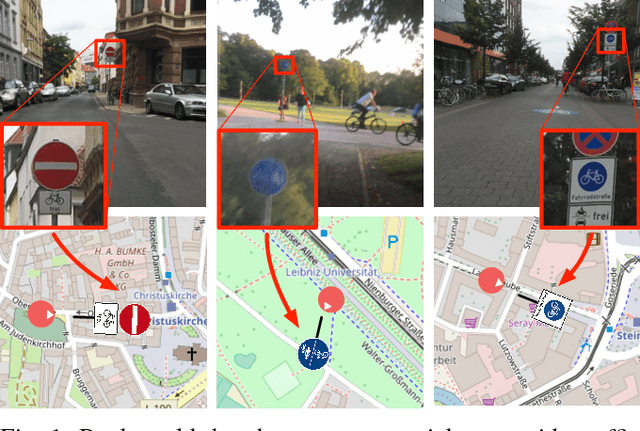
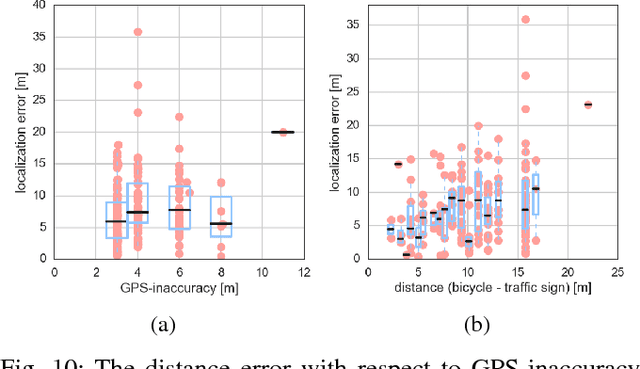
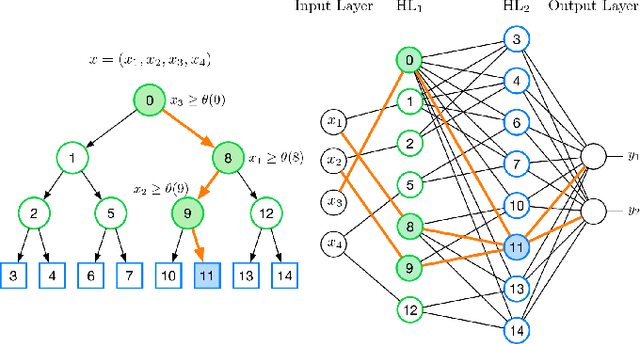

In recent years, data-driven methods have shown great success for extracting information about the infrastructure in urban areas. These algorithms are usually trained on large datasets consisting of thousands or millions of labeled training examples. While large datasets have been published regarding cars, for cyclists very few labeled data is available although appearance, point of view, and positioning of even relevant objects differ. Unfortunately, labeling data is costly and requires a huge amount of work. In this paper, we thus address the problem of learning with very few labels. The aim is to recognize particular traffic signs in crowdsourced data to collect information which is of interest to cyclists. We propose a system for object recognition that is trained with only 15 examples per class on average. To achieve this, we combine the advantages of convolutional neural networks and random forests to learn a patch-wise classifier. In the next step, we map the random forest to a neural network and transform the classifier to a fully convolutional network. Thereby, the processing of full images is significantly accelerated and bounding boxes can be predicted. Finally, we integrate data of the Global Positioning System (GPS) to localize the predictions on the map. In comparison to Faster R-CNN and other networks for object recognition or algorithms for transfer learning, we considerably reduce the required amount of labeled data. We demonstrate good performance on the recognition of traffic signs for cyclists as well as their localization in maps.